| 00:00 | start recording and the lecture. So today mm we'll introduce or where will |
|
| 00:14 | just introduced one more tool that I . We'll use for the assignments and |
|
| 00:22 | projects and that's related to under the and energy consumption in computing so and |
|
| 00:35 | the end of the lecture or at when I'm done with talking about this |
|
| 00:40 | . So yes for the demo of tool but first I will um talk |
|
| 00:47 | little bit or motivational part why it has become a key concern. I |
|
| 00:56 | different aspects on this uh this kind outlined on this slide starting with talking |
|
| 01:04 | about high level issues in terms of and environmental concerns and but those are |
|
| 01:12 | fact significant in terms of giving and what this issue about the energy and |
|
| 01:19 | has to deal with HPC and then a little bit of background to why |
|
| 01:24 | has become such an issue from a perspective. And then getting onto talking |
|
| 01:34 | how you in fact the measure power energy and then onto the demo. |
|
| 01:41 | here is kind of the high level of it. So in terms of |
|
| 01:47 | all know that yeah, computing becoming in all kinds of forms, even |
|
| 01:54 | the classes mostly focused on servers and centers. But it's here look at |
|
| 02:02 | particular plot on the left hand the green field as kind of showing |
|
| 02:09 | through cloud computing and other usages of centers it's becoming a quite significant growth |
|
| 02:19 | as well as so are other aspects is usually yes um thrown together in |
|
| 02:28 | label up IOT or information um So the point that's the sort of |
|
| 02:41 | high level thing that it's in fact substantial portion already and it's a rapidly |
|
| 02:50 | and an increasing proportion or portion of total energy consumption. And it's such |
|
| 02:58 | scale that secretariat requires the addition of large power plants each year in order |
|
| 03:07 | power uh computing in one form or that's being used. So it is |
|
| 03:14 | high level of societal point, a concern. Now the cost is too |
|
| 03:24 | kind of illustrated and this one and think so brought that up at the |
|
| 03:28 | beginning of this course that the the cost of ownership for a server or |
|
| 03:36 | or data center more than half of cost is these days in most occasions |
|
| 03:43 | attributed to power and cooling costs. it is uh one of the reasons |
|
| 03:53 | both designers of chips and designers of and operator something data centres left google |
|
| 04:03 | amazon and facebook day uh paying it attention and in fact designed their own |
|
| 04:11 | to a very large degree and then increasing degree. Mhm. So of |
|
| 04:16 | electricity prices are not fixed. So is just to show that yes they |
|
| 04:20 | increased but as it says on the of the slide here in fact they |
|
| 04:26 | rate of any consumption and most installations significantly higher than the costs of the |
|
| 04:35 | that there in the total cost of over this world five years that equipment |
|
| 04:44 | to be used. Much of the does not come from increased electricity |
|
| 04:51 | but it actually comes from other sources this is kind of a another element |
|
| 04:59 | the scale more up to so the center level and just mentioned that before |
|
| 05:06 | . But these data centers, they basically consumer electricity like small towns and |
|
| 05:15 | show a little bit of this. that means the data center at the |
|
| 05:19 | of the internet companies as well as forms of service providers. There are |
|
| 05:27 | by plumbing in one form or It's not so much the computer action |
|
| 05:33 | taking space element comment on the environmental and by now I think most people |
|
| 05:42 | aware of the climate change and but temperature of the gold is after a |
|
| 05:51 | period of time, it was declining About 100 years ago when things started |
|
| 05:57 | go in the other direction. And that's also is well known by now |
|
| 06:03 | is a strong correlation by emissions, just carbon dioxide and other forms of |
|
| 06:10 | as well and global warming anyway, that is a concern And the |
|
| 06:20 | the big consumers are paying attention to in more than one way, both |
|
| 06:25 | terms of costs but also in terms what kind of energy they're using. |
|
| 06:29 | this is just example of, oh in this case has addressed the issue |
|
| 06:36 | trying to use renewable and clean energy there is another example of his cook |
|
| 06:43 | , The big consumers do pay attention more than one way now a little |
|
| 06:49 | . So how is this kind of to high performance and computing and why |
|
| 06:55 | I bring it up in this And so here is kind of the |
|
| 07:03 | , our systems tend to work. this is coming from an article a |
|
| 07:09 | years ago, actually quite a few ago by now uh from google that |
|
| 07:17 | the green line, it kind of the power consumption as a functional workload |
|
| 07:26 | . And then and the horizontal axis the utilization of the fraction of peak |
|
| 07:35 | is being used from the system. it kind of shows that as the |
|
| 07:42 | goes down, so does the energy , so and that's because the power |
|
| 07:51 | does not decrease at the rate that load on the system does. So |
|
| 07:56 | get really good energy efficiency, one to have hi resource utilization and that's |
|
| 08:04 | of what where the connection comes to HPC class which is kind of focused |
|
| 08:09 | making good use or the resources that your disproportion disposal. This is kind |
|
| 08:21 | an old ish yeah plot but it's still relevant even though things has gotten |
|
| 08:27 | through all kinds of mechanisms that the has been doing since then but it |
|
| 08:31 | still the case that hi you're degree utilization of their sources leads to how |
|
| 08:41 | energy efficiency. So now I will sort of a few comments here about |
|
| 08:50 | things why this is happening in terms why the costs or that and the |
|
| 08:59 | consumption, relatively speaking has become big over time and it's now really the |
|
| 09:09 | design constraints except for obviously reliability and and security. But on a normal |
|
| 09:16 | when things are what kind of moving as they should be, then they |
|
| 09:23 | . The main concern is to produce A. G consumption both in the |
|
| 09:33 | stage as well as when things are . So I will first make some |
|
| 09:39 | about but this issue at the high and then talk a little bit more |
|
| 09:45 | details and getting to the point where can in the class actually get some |
|
| 09:51 | through measurements. Okay, so here some statistics that has been collected by |
|
| 10:01 | around as Comey at stanford and together the collection of other people in the |
|
| 10:09 | as well. So it basically plots kind of utility or work that you |
|
| 10:18 | per unit energy. So so over which is horizontal axis and shows how |
|
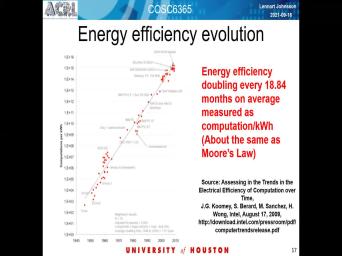
| 10:26 | has improved them. I guess this and doesn't call me on 2010 but |
|
| 10:33 | has more or less continued in the way the so basically from this lot |
|
| 10:43 | looks at, one can conclude that terms of utility or work for unit |
|
| 10:50 | things have actually improved pretty much in with moore's law. So that's a |
|
| 10:59 | note. That is clearly, I say a fantastic achievement and I'll come |
|
| 11:05 | to that. How amazing this achievement that Yeah, the energy efficiency or |
|
| 11:14 | improved along the lines almost long. that's clearly very good news. Um |
|
| 11:25 | it is another part of the good . Um and in this case it's |
|
| 11:32 | at performance gain over time for the on this Top 500 list that I |
|
| 11:40 | referred to a number of times. it's basically shows again and this logarithmic |
|
| 11:48 | again on the left axis. Or shows this exponential improvement in performance over |
|
| 11:57 | . Mm And that's again amazingly good . But it turns out that the |
|
| 12:05 | in performance over time as this year actually has been improving more rapidly than |
|
| 12:17 | the moore's law In terms of doubling things more or less every 18 to |
|
| 12:23 | months. So in this case the rate is closer to a little bit |
|
| 12:31 | a year. So what's happening then something like this? So in fact |
|
| 12:37 | have to exponential one is the growth performance of systems and the other part |
|
| 12:45 | the growth in You know, work two unit energy and historically and it |
|
| 12:54 | is the case that performance has grown rapidly exponentially than the improvement in energy |
|
| 13:05 | has been growing. So the fact in that case there is a God |
|
| 13:11 | when the gap is exponential things shows fairly quickly so that at sort of |
|
| 13:18 | high level, the reason why energy and system has become a prime concern |
|
| 13:28 | not only for better operated devices where always been a concern to for longevity |
|
| 13:36 | charges and what you can do before need to recharge. But it's now |
|
| 13:40 | since more than a decade back, prime concern in terms of servers, |
|
| 13:48 | , even things which has network power of the cost and impact on the |
|
| 13:56 | unless you happen to be lucky and totally clean energy, which is not |
|
| 13:59 | case in most cases. So now to this issue on a little bit |
|
| 14:11 | detailed and technical, we're all getting to uh the just more core computer |
|
| 14:18 | point of view. So now taking look at what is kind of the |
|
| 14:28 | of discrepancy that I just pointed out the terms of the exponential is growing |
|
| 14:32 | different rates. So I'll first talk little bit about architecture because architecture |
|
| 14:41 | this whole premise for this class. , it's resource well efficient use of |
|
| 14:49 | , computing resources and you can't really that by being ignorant of the |
|
| 14:55 | So that's why I'm bringing get up the motivation for giving you the tools |
|
| 15:01 | you can figure out how well you're the systems are working on. So |
|
| 15:08 | we didn't tell the puppy and then of high level tools in terms of |
|
| 15:13 | and tracing and today then towards the of this discussion about power and energy |
|
| 15:22 | a tool that you can use for power consumption in the system or for |
|
| 15:29 | application. So now about the So this is something that was published |
|
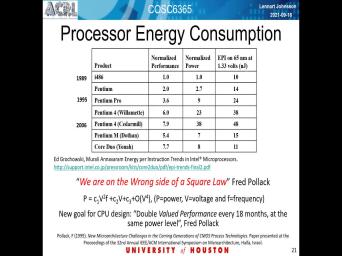
| 15:36 | long time ago and it shows A of generations of Intel processors starting back |
|
| 15:47 | 1989 and You know beyond 2006, I just plugged in those years is |
|
| 15:57 | get a little bit of a So, and then it's the stable |
|
| 16:03 | normalized to This until 4 86. was released in 1989. So the |
|
| 16:12 | I wanted to you to pay attention is the right most column and the |
|
| 16:19 | stands for energy per instruction. So shows over About a little bit over |
|
| 16:30 | years, but not quite two The energy per instruction girls grew by |
|
| 16:36 | a factor of five. And that obviously quite significant. So just to |
|
| 16:49 | , you so if you were to again that we tend to focus on |
|
| 16:53 | the course, you know, the multiply and other things. But the |
|
| 16:58 | of multiplication and addition has one instructions assess over time, the energy to |
|
| 17:05 | that instruction Grew by almost a factor five. So not uh had serious |
|
| 17:19 | . And I'll cover a little bit on the next few slides, but |
|
| 17:23 | made this fellow or a couple of fellows at. And so uh calling |
|
| 17:32 | phrase here on the wrong side of square law and the square law was |
|
| 17:36 | underneath. And I'll talk a little more about where that comes from. |
|
| 17:40 | its basic property of the technology being to implement both processors and memory known |
|
| 17:47 | C most complement metal oxide semiconductors. now a little bit too where Justice |
|
| 17:59 | Law come from a little bit. the reason why The energy per instruction |
|
| 18:06 | up by coastal factor of five the two lunch against. I should comment |
|
| 18:10 | those two in the table. Ah a little bit of um a consequence |
|
| 18:19 | the industry realizing that This trend that down from 1989 to 2006 wasn't |
|
| 18:29 | Something needed to be done. And end of that started to change course |
|
| 18:33 | what how it was doing um processor . So here is kind of just |
|
| 18:43 | slow about it. And the plot shows the growth, the tremendous growth |
|
| 18:49 | the transistor count on a piece of for a process that I went from |
|
| 18:55 | the order of thousands, two And what for a long time what |
|
| 19:02 | computer architects did. They used them Try to make on one hand programming |
|
| 19:10 | easily. Uh It also introduced many features like vector instructions and other |
|
| 19:17 | So the increased instruction sets but that come without cost. That requires more |
|
| 19:24 | and more transistors to serve these They policy introduced things like out of |
|
| 19:31 | execution and predictability and all kinds of to again simplify programming. Um and |
|
| 19:42 | trying to get very good performance out the processor without having to pace so |
|
| 19:49 | attention to details of the code. then other things was to improve reliability |
|
| 19:55 | serviceability or rows for short. Again it came at the price of |
|
| 20:03 | . So we're now I have a of more slice about this. So |
|
| 20:10 | is from the Lawrence Berkeley lab as as the National Ngos Research Center and |
|
| 20:21 | . So they looked at the number their codes are basically scientific and engineering |
|
| 20:28 | and they discovered and that all of chinese significant growth in instructions that was |
|
| 20:36 | in order to make processes also usable a and by their markets. So |
|
| 20:44 | all instructions is needed everywhere about to get high volume. Then there was |
|
| 20:51 | of no specialization. So it's kind one shoe fits all approach that was |
|
| 20:56 | for many years and for many years worked just fine but it has stopped |
|
| 21:03 | . I'll come back to that. anyway what the people at Lawrence Berkeley |
|
| 21:08 | out that Of the at the time 300 instructions in an in food processor |
|
| 21:14 | the time. Their code is basically usable 80 so you put throughout |
|
| 21:21 | More than 2/3 of the instructions and will not adversely affect the performance of |
|
| 21:26 | coats. And by now there is than 500 instructions and Intel processors. |
|
| 21:34 | the growth and instructions has continued. basically there one rule that very famous |
|
| 21:43 | architect known as seem okay said that design people principle is avoid waste. |
|
| 21:50 | was his former staying in order to design supercomputers. And here is kind |
|
| 21:56 | just another slide showing us a little in a graphical way how this energy |
|
| 22:03 | instructions kept decreasing over the years uh successive generations of inter process that is |
|
| 22:11 | by inter people. So um it cover other processors. And it also |
|
| 22:18 | at the bottom you know how Uh the number of instructions grew up And |
|
| 22:24 | it showed also that as the previous showed in terms of any different instruction |
|
| 22:32 | it was not sustainable. So at point, the design principle for computer |
|
| 22:38 | kept changing. And a number of features that was very common then started |
|
| 22:46 | be taking out in order to make efficient energy efficient processors. But it |
|
| 22:55 | created a proliferation in terms of computer architecture or processors when I come back |
|
| 23:04 | that. So another consequence of this for instructions was what's kind of shown |
|
| 23:12 | this slide that the heat density which kind of on the left taxes here |
|
| 23:19 | the years and this is way back it showed that the heat density of |
|
| 23:30 | increased to an exponential rate as did performance as special before. But it |
|
| 23:41 | meant that the heat tends to regards high so as you can see on |
|
| 23:48 | slide so the heat density on some the processes that were top of the |
|
| 23:53 | at the time uh towards the right of this slide with the graph at |
|
| 24:00 | famous close to that in a nuclear and orders of magnitude or at least |
|
| 24:06 | order of magnitude higher than you your heating plate on your stove that |
|
| 24:12 | use for you know making your tea or go your eggs or try |
|
| 24:17 | So the heat density on chips is higher than on devices that we tend |
|
| 24:27 | be familiar with us, just private . But it also means that cooling |
|
| 24:36 | became is serious business and you can some examples of things are not going |
|
| 24:45 | well I guess on the top right , but if you look at the |
|
| 24:49 | right hand side uh all the cooling that are put on this chip basically |
|
| 24:55 | way bigger than the chips of self the processor chip. So things uh |
|
| 25:03 | , kind of very difficult and here just another slide that shows a little |
|
| 25:08 | more in terms of actual numbers of the heat tends today is actually up |
|
| 25:16 | current times, pretty much so, is includes many of recent processors and |
|
| 25:24 | are still up there in the right corner. Yeah, so one of |
|
| 25:33 | things that again coming back to this per instruction slide and the heat density |
|
| 25:42 | as I said, fledge process of in fact had to change course and |
|
| 25:53 | companies were a little bit more attentive the issue than I guess intel was |
|
| 26:00 | they basically had to abandoned one of designs because they realized it would not |
|
| 26:06 | operate the way it was intended. the point essentially was what happened was |
|
| 26:13 | order to try to continue this exponential and performance, that's when we got |
|
| 26:20 | processes. So that has been around for close to two decades, at |
|
| 26:25 | 15 years and that has all to with energy consumption in part so |
|
| 26:33 | if the heat issue basically forced or an impact on applications and codes because |
|
| 26:46 | threaded coats could no longer offer the improvement in performance. So things that |
|
| 26:54 | very at the physics, I believe had a profound or has had a |
|
| 26:59 | impact on the both algorithms and software what we need to do in order |
|
| 27:09 | get scalable performance and good efficiency, dropping down on more levels. So |
|
| 27:21 | why this, it density went up the energy per instruction in part was |
|
| 27:29 | to again these architectural features that computer introduced, but it's also in part |
|
| 27:38 | to the underlying, see most technologies to implement processors and memory. So |
|
| 27:50 | I'm going to try a little bit this and then yes, I should |
|
| 27:54 | for a little bit of questions, if there are questions, but let |
|
| 27:58 | talk a little bit about Seamus before do that. Yeah, so the |
|
| 28:07 | being used, this complementary metal oxide is essentially what sometimes is called the |
|
| 28:17 | transfer technologies, you just move electrons um and what's your here as so |
|
| 28:26 | somewhere along the lines, most of has encountered this notion of, you |
|
| 28:33 | , arms law and yeah, the of capacitors and resistors and simple |
|
| 28:43 | So in terms of computers, the in this case is really modeling what |
|
| 28:51 | transistor is. So, and the is not something that that necessarily insert |
|
| 29:01 | . What um designed by all kinds wires they do have resistance or kind |
|
| 29:07 | captures that wire resistance. And then way transistors works is basically, it's |
|
| 29:15 | charging and un charging a capacitor. and then when you compute to basically |
|
| 29:22 | into these capacitors up and down to yep the logic to do the computation |
|
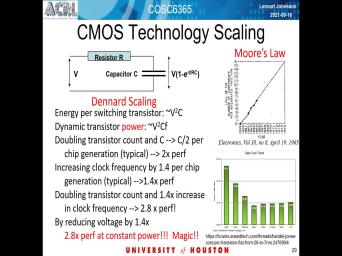
| 29:30 | So what so from this kind of simple sketch uh cmos works and as |
|
| 29:40 | charge transfer technology and arms law wanting figure out here the energy of for |
|
| 29:48 | transistor is proportional to the voltage and charge on the capacitor which is proportional |
|
| 29:56 | the voltage and the capacity. And you get something where they um energy |
|
| 30:04 | charging or charging. Right capacitor is to the square on the voltage and |
|
| 30:13 | capacities. And then as you compute switch this thing off and on. |
|
| 30:20 | depending upon the rate at which you these transistors off and on or basically |
|
| 30:28 | rate at which you charge and discharge capacitor. The power goes up because |
|
| 30:34 | proportional to the number of times or freak of the unit time that you |
|
| 30:39 | the switching. So it's proportional to clock frequency on the circuit you're |
|
| 30:46 | So now this is part of the law that was in the previous slide |
|
| 30:50 | shows what's known as the dynamic the pumping of charges not is necessary |
|
| 30:56 | do the computation in Seamus that is to the square on the wall, |
|
| 31:02 | the frequency at which you operate. the rest of the lines on this |
|
| 31:10 | on the left hand side has to with how they moore's law and the |
|
| 31:17 | that more slow advice that basically was that again, that you want more |
|
| 31:23 | less doubled the number of transistors. every To 18, 20 months or |
|
| 31:33 | . So there there is that if that the technology being used to built |
|
| 31:43 | , what improves you can make scale down, you can make smaller and |
|
| 31:48 | transistors and thinner and thinner wires. and the rule of thumb has been |
|
| 31:55 | technology generation, you scale you'll make half as wide and in principle also |
|
| 32:04 | stick. So that means both say a plane both in the X direction |
|
| 32:13 | the wind direction. The future sizes about a half size. So that |
|
| 32:21 | um that If you do that I government a little bit ahead of |
|
| 32:29 | Sorry. So in principle you scale down by about 70%. and so |
|
| 32:35 | two generations, in fact scallop by factor of four. But in one |
|
| 32:40 | things get scaled down my .7 So speak. So that means you get |
|
| 32:48 | the number 2.7 in both dimensions and it to get sort of 5.5. |
|
| 32:54 | that means you get twice as many in the same silicon area for a |
|
| 33:02 | . Which is what the more slow more slow gives you the time frame |
|
| 33:07 | that change. So that means by quite suspended transistors well in principle would |
|
| 33:14 | the performance on the same size Piece silicon with each generation or scaling down |
|
| 33:23 | 70%. Now if you then I'll increases increase the clock frequency um and |
|
| 33:37 | inverse proportion to the scaling down, on that in a bit. That |
|
| 33:43 | the conference will go up for Factor 1.41 divided by .7. But |
|
| 33:51 | that means you get twice as many that run faster. So that would |
|
| 33:56 | that you get something. There is three times the performance per generation of |
|
| 34:06 | To see most technology or the scaling from one generation to the next. |
|
| 34:14 | the reason why luncheons in fact scaling the clock which happened actually for many |
|
| 34:24 | . That was part of the problem the increasing intensity. But even um |
|
| 34:35 | guess by scaling up the clock without the heat density was possible because the |
|
| 34:43 | this equation works. Um Yes see um right reduced um when you scale |
|
| 35:02 | down the area of the capacity goes when the square of the scaling and |
|
| 35:07 | distance between the two plates of the also goes down. And the one |
|
| 35:13 | remembers to how the capacitance of some figured out than the negative factors that |
|
| 35:19 | scales down. And so the product of C times F allowed you to |
|
| 35:29 | up the frequency in proportion to the of the future sizes. Their products |
|
| 35:37 | fixed now. But since you have transistors in a given area that would |
|
| 35:47 | that the power density goes up. if you scale down the frequency oh |
|
| 35:55 | vaulted, sorry skilled on the hostage proportion to your scaling down the geometric |
|
| 36:06 | than both the square gets reduced by factor too. So that means you |
|
| 36:14 | double the number of transistors in the area and preserved the participation by scaling |
|
| 36:25 | the voltage. So that's what has . That essentially one could yeah, |
|
| 36:35 | or less three times the performance in unit area or yes on unit silicon |
|
| 36:48 | chip for processing generation. And that the magic in terms of this exponential |
|
| 36:55 | that went on for a number of . And then it turned out that |
|
| 37:00 | architects in fact dead and increase the creates a little bit beyond these |
|
| 37:06 | So that in fact he densely did up and show them the previous |
|
| 37:12 | So it wasn't quite as good. they actually push the envelope a little |
|
| 37:17 | beyond this scaling. Now this way scaling in relation to the electrical properties |
|
| 37:32 | known as an art scaling that it on this slide. Whereas the moore's |
|
| 37:37 | talked about the density of transistors in area and then I was a engineer |
|
| 37:48 | I am that actually applying how the way to scale Seamus technology was. |
|
| 37:59 | they did was is important because it no longer mhm uh working. But |
|
| 38:10 | is just a slide showing this um law again and I have some other |
|
| 38:17 | that in fact is related to what going to talk about next. And |
|
| 38:23 | . Denard scaling that it's important that are aware of as the computer sciences |
|
| 38:27 | least those of you who are. there's other things that related to the |
|
| 38:33 | and other things are calling like fans I'm not going to go into the |
|
| 38:39 | and listing. But just to point what the consequences. So now just |
|
| 38:44 | what uh comment that this did not stop working. So uh it's because |
|
| 39:01 | the physics involved when the feature sizes small enough so to speak. So |
|
| 39:09 | one fellow at uh this is actually former intel fellow and that also work |
|
| 39:14 | the agency known as DARPA basically said know more gave them more transistors as |
|
| 39:21 | said but that the northern scaling how scale the electrical properties made them |
|
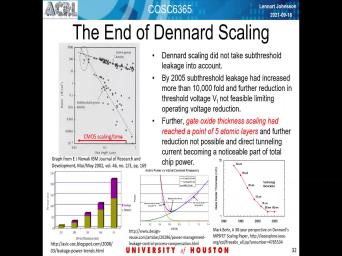
| 39:30 | Now the problem now is that what was what's known as this leakage. |
|
| 39:39 | the graph in the upper left hand basically shows you um the dash line |
|
| 39:50 | And finally dashed line I should And with pretty significant slope and pick |
|
| 39:59 | dash. It's in a different And what's on the horizontal axis is |
|
| 40:06 | dimensions or feature sizes of C. technologies. So over time things progressed |
|
| 40:12 | the right hand side of this upper hand plot towards um the left access |
|
| 40:20 | the clock. So what has chose more finally dashed lines started to approach |
|
| 40:30 | in fact cross over for the other certainly top line with its lower slope |
|
| 40:39 | a dynamic energy, useful energy for computing. And the other line is |
|
| 40:45 | leakage power. So it then that electrical scaling that they're not worked out |
|
| 40:57 | work anymore. So that means you not continue to reduce the voltage because |
|
| 41:06 | this leakage currents. So that means things used to work very nicely. |
|
| 41:14 | that's what this slide shows against the one. But the blue errors. |
|
| 41:20 | the cause of the lack of the scaling In the end one didn't get |
|
| 41:28 | times for technology generation on my basically to choose. Yeah. That you |
|
| 41:34 | kind of twice the chip capability than more power consumption or you get preserved |
|
| 41:44 | consumption and the smaller growth rate in of the capability per chip, which |
|
| 41:50 | kind of what has been witnessed in years. And if as this sellable |
|
| 41:58 | that is now yes. VP for at NVIDIA and formerly professor at MIT |
|
| 42:07 | stanford. Point out there is actually our team and that good. So |
|
| 42:12 | very little improvement in the can performance chip when you are power limited. |
|
| 42:27 | this is what does begin to So this type of what that people |
|
| 42:33 | talked about. A bunch of There's a parable, there's uh frequency |
|
| 42:39 | , you can't raise the clock frequency again because what yeah, increase the |
|
| 42:46 | dissipation and you can't fool it. that's a no, no. And |
|
| 42:55 | . That also means that the power has to be limited. So the |
|
| 43:00 | of that is to try to get performance on processor chip is to introduce |
|
| 43:08 | course. This is I guess the line. So this is again what |
|
| 43:18 | fellow big valley. That's a good . So again, coming back to |
|
| 43:24 | energy consumption is the prime thing and why it is such an important thing |
|
| 43:34 | design of chips, design of servers design of data centers and through the |
|
| 43:38 | thing. And it should also be to users and programmers and trying to |
|
| 43:47 | sure that the platforms are efficiently used order to reduce both cast and environmental |
|
| 43:54 | of computer. Mhm So uh huh of yes more comments before talking about |
|
| 44:06 | to measure power and getting to the where suggest can do them all the |
|
| 44:12 | that was used for the next But before that I can stop and |
|
| 44:17 | if there's any questions on this broad of why energy efficiency has become critical |
|
| 44:29 | there are regions of the problem that not so easy to solve. |
|
| 44:46 | so on the a little bit so I said, computer architects, they |
|
| 44:54 | to realize about 15 plus years No doing business as usual at that |
|
| 45:04 | was not sustainable. So a number things have changed since this and this |
|
| 45:15 | is just trying to point out what's they're coming in sort of it. |
|
| 45:21 | word among computer architects and and I the first lecture slide I encourage and |
|
| 45:29 | want to take listen to or look the video given by the Paterson and |
|
| 45:38 | Hennessy the touring award winner is about years or so ago. It's a |
|
| 45:43 | nice video. Yeah. Where are ? Point out there is much to |
|
| 45:52 | gained by starting to pay attention to applications actually needs and trying to |
|
| 46:01 | Make the architecture being more in tune what application needs. And that goes |
|
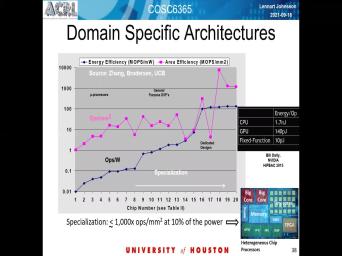
| 46:10 | the name of domain specific architectures. what this line of extension shows that |
|
| 46:17 | the benefits that can be achieved. again. Trying to do it's also |
|
| 46:26 | commonly known as co design that you your system according to the applications that |
|
| 46:35 | are expected to run on the system the vertical axis is again logarithmic access |
|
| 46:45 | on the horizontal axis is just a of different designs that this group Berkeley |
|
| 46:55 | for certain test and it's sort of broader sense group at U. |
|
| 46:59 | Berkeley they decide. But the point the bottom line I guess is that |
|
| 47:06 | doing um specialization or paying attention to the needs of an application actually are |
|
| 47:14 | gap Anywhere between three and 5 orders magnitude improvement in energy efficiency. So |
|
| 47:24 | what has happened in recent years and of you interested in ai and machine |
|
| 47:30 | will probably have or maybe we're of terrorism. A large number of startup |
|
| 47:37 | and now designing special purpose chips for machine learning and there's also you know |
|
| 47:44 | Gpus are effectively and in a way purpose processor that it was just um |
|
| 47:53 | to do pretty much rendering in the days. And then when I try |
|
| 47:57 | tweak the designed to make in the universal is useful. So today's Gpus |
|
| 48:02 | what they call general purpose Cpus as to the early ones. So that |
|
| 48:06 | one has tried to tweak the design it started out as being something optimist |
|
| 48:11 | doing computer graphics. But yeah, this is just to say that the |
|
| 48:19 | architects now increasingly you will find more architectures and that obviously has consequences for |
|
| 48:32 | codes and algorithms and again, one them to be on know what the |
|
| 48:39 | architecture is to make full use and the efficiency out of these architectures. |
|
| 48:45 | this is just another summary slide initials , orders of magnitude again and performance |
|
| 48:52 | specialization and more or less the same more recent plot where it actually specific |
|
| 49:03 | are plugged into this kind of a that is doubly logarithmic both in terms |
|
| 49:09 | terms of IT instructions per second on horizontal axis and the corresponding power on |
|
| 49:16 | vertical axis. Yeah. So then think I showed this on the early |
|
| 49:24 | So in terms again getting good energy and efficiency, paying attention to |
|
| 49:33 | how the software actually managed to make use of the platform also can give |
|
| 49:39 | of magnitude improvement in both performance and , correspondingly energy efficiency. So this |
|
| 49:48 | a game when I said that the today is cold design Just missed and |
|
| 49:54 | here and that's not serious signed by side. Mm And there is just |
|
| 49:59 | example just concrete example in doing certain and biomedicine. So just included this |
|
| 50:09 | something that is more specific in terms jean sequencing and it's in this case |
|
| 50:17 | think they range from start to finish About the factor of 10 to the |
|
| 50:22 | of 10,000 improvement. So now getting to what how to deal and how |
|
| 50:34 | measure performance because without doing so we really or measure power that we can't |
|
| 50:40 | much about it and figure out how impact what you're doing. So. |
|
| 50:49 | this shows pretty much what the data look look like in terms of the |
|
| 50:58 | supply, I should say, you , you start with electric power grid |
|
| 51:01 | you know if you have the single in the lab that may not a |
|
| 51:06 | of these steps are outside your piece control. But if you are in |
|
| 51:11 | data center, this just always Let's start with something connecting to they're |
|
| 51:18 | serious power grid. So the big you have high voltage transmission lines coming |
|
| 51:22 | something and then eventually get transformed down various voltage levels and then there's a |
|
| 51:31 | distribution system in the data centers where got things and possibly into various clusters |
|
| 51:41 | . So there's some feed for cluster then within the cluster there's feeds for |
|
| 51:47 | of racks and then within Iraq rode fees or power conversion or control for |
|
| 51:54 | racked and then from the wreck levels going to the Windows servers and from |
|
| 52:01 | server they go onto eventually separate So this is kind of just a |
|
| 52:07 | of pictures from the whole distribution change all at different points in this power |
|
| 52:18 | . There are ways of controlling and power now for this class we're going |
|
| 52:26 | times all the way down into trying get some insight what happens mostly at |
|
| 52:34 | process of level and processor and memory . So here's again a little bit |
|
| 52:42 | there Type of devices one has and one can get information about the part |
|
| 52:51 | at various levels in this hierarchy that showed them previous slides. And PD |
|
| 53:00 | is a common acronym that anyone that up being exposed to managing power and |
|
| 53:08 | would get to know and that stands power distribution unit now in terms of |
|
| 53:15 | and our ability to get insights. , most data centers in that for |
|
| 53:25 | , the NSF centers that we're using it also the case with our local |
|
| 53:31 | center at your age, the data that's a data science institute manages, |
|
| 53:38 | don't let us get access to information the pd US or even things at |
|
| 53:47 | individuals survey level because it's a standard comes with every server that has something |
|
| 53:53 | this I P M I for short part platform management into fix right. |
|
| 54:02 | won't let us yet onto that to able to see things for the whole |
|
| 54:10 | . So what we can do is a little bit inside pieces of an |
|
| 54:16 | that means at the processor level. there's something known as Rappel, which |
|
| 54:27 | the one thing we can use and thing that so Joshua demo straight and |
|
| 54:35 | stands for running average part limit and is was designed and the main purpose |
|
| 54:48 | is for essential systems admin or two limits for the power consumption of notes |
|
| 54:59 | clusters. So it wasn't really designed exploring what various parts of the system |
|
| 55:12 | power at various instances in time, it can be used for that in |
|
| 55:17 | limited way. And this was first by until about 7, 8 years |
|
| 55:30 | I think when you have it on slide um, yeah almost 10 years |
|
| 55:35 | when again power became such an issue it needed to be managed actually in |
|
| 55:43 | time during the execution of codes. they came up with this raffle idea |
|
| 55:52 | this slide best gives some timelines and names of generation of infant processors at |
|
| 56:01 | , not particularly relevant but what is um some features of Rappel in terms |
|
| 56:12 | what it can do, but also it does things. So in the |
|
| 56:17 | the first generation power consumption was actually measured at the detailed level that rapper |
|
| 56:26 | do things. It was based on was figured in the design stage in |
|
| 56:35 | of the power consumption for instruction. it early versions of Rappel looked at |
|
| 56:46 | being executed uh, formula for than energy per instructions and then computed an |
|
| 56:54 | for what the part of dissipation would be as a function of the instruction |
|
| 57:01 | that was used. But since a years back, I think that's what's |
|
| 57:07 | 2014 or so now park conversion and is actually on inside the silicon die |
|
| 57:18 | has course and the processors. So other ways of actually measuring the power |
|
| 57:27 | at the various parts of the So that's what Apple does at this |
|
| 57:36 | . This line tells you about the in time. So rappels sample things |
|
| 57:43 | every millisecond and the resolution in terms energy that It has, it's about |
|
| 57:54 | marshal gels and then it cannot do much of the detail. So here |
|
| 58:00 | kind of what done and then I I will just pass it on to |
|
| 58:04 | josh to take over and do the but and using Rappel there two concepts |
|
| 58:10 | called the package, which is kind the whole chip, the whole thing |
|
| 58:15 | plugs into the socket on the board that you can get information about and |
|
| 58:22 | can get the information about the aggregate consumption about all the course and then |
|
| 58:31 | upon which chip from until you have can either get information about say embedded |
|
| 58:45 | or the main memory that the Iraq I think that's cool. Yeah, |
|
| 58:53 | are okay just pointing out that there an issue then what inside you can |
|
| 58:58 | in terms of the resolution are both time and in terms of energy measurements |
|
| 59:04 | uh this is just pointing out because the resolution if you really want to |
|
| 59:09 | detailed and these were done by people the data center in Germany and I |
|
| 59:14 | wanted very careful information about what was on in their measurements and they figured |
|
| 59:21 | that not too kind of make up the limited resolution in both time and |
|
| 59:26 | or rappel. But for that I let's just take over. Okay. |
|
| 59:44 | , yeah, yeah. So I showing where uh that I believe uh |
|
| 60:14 | ? Yes, but lots of Oh, very hard to hear |
|
| 60:30 | So requires I don't know if Okay, that that that's fine. |
|
| 60:46 | , I was coming back but maybe better. Okay, mm. How |
|
| 60:59 | now? That's fine for me at . All right. So, |
|
| 61:08 | So what I was saying is that how to use rappels on stampede |
|
| 61:16 | So first thing again, as you need to be on a compute |
|
| 61:21 | and I'll get to what this rappel program does in a while. But |
|
| 61:27 | , just to give an overview, provides three ways through get energy consumption |
|
| 61:34 | uh, at target level that is some sandwiches. And there are these |
|
| 61:41 | interfaces are either uh, you use , the MSR mode which is more |
|
| 61:47 | registers, but these are required root privileges and unfortunately that's not given |
|
| 61:54 | all the users on these clusters. , the other interface is using the |
|
| 62:00 | uh, interface. A few of Euro were upset. It's the native |
|
| 62:05 | utility for performance analysis. Again, one is not available. The one |
|
| 62:12 | that we will be using is called fs um interface and that basically read |
|
| 62:19 | the energy consumption values for each pocket the memory from one of the locations |
|
| 62:26 | intel rappels updated, uh, everyone . So it's just reading a bunch |
|
| 62:34 | a bunch of files that condense the consumption values now to use uh |
|
| 62:42 | Uh we need to follow the following . So first I have for |
|
| 62:47 | our matrix multiplication going that you got assignment to uh you need to simply |
|
| 62:56 | it as you would normally do using gcc or intelcom pilot. And this |
|
| 63:05 | an executable most special thing there. what you need to do is you |
|
| 63:09 | to use this program that you will called raffle reid dot c now, |
|
| 63:17 | this rattle, read that the program have a call at line number 811 |
|
| 63:27 | for system uh false. And that should have the name of your executable |
|
| 63:34 | you want to measure uh the energy for us and you can change it |
|
| 63:40 | any executable name that you that you have for your program. I hear |
|
| 63:45 | original is one of the examples that just using here. Once you have |
|
| 63:50 | that. And so on line 8 , it's the function that calls the |
|
| 63:55 | interface. So that's why we that's specifically said line 8 11. there |
|
| 64:00 | three other functions that uses uh to functions that uses the other two interfaces |
|
| 64:04 | are not available. Make sure you only the function that you look at |
|
| 64:09 | surface uh interfere. Oh, once you have added the name of |
|
| 64:15 | executable to the system, call in in that uh political program, you |
|
| 64:22 | to compile your reporting agency program. for that the command here, did |
|
| 64:28 | see your optimization flag? The w flags and your output file name, |
|
| 64:36 | of the program, personal name. you also need to link the map |
|
| 64:41 | uh using the yellow flag here. and once you do that, I |
|
| 64:46 | had the executable but yeah, it generate the rappel. Read program. |
|
| 64:52 | , what you need to know is Apple's lead um provides you energy consumption |
|
| 65:00 | at socket levels. And if you simply run the code without any um |
|
| 65:08 | special tricks, so to say, operating system may uh decide to switch |
|
| 65:16 | execution of your program from one sport another photo from 100% to another |
|
| 65:23 | And so to be consistent in terms what um pockets energy consumption you are |
|
| 65:31 | , we will we will use something as a process pinning that I believe |
|
| 65:36 | part of one of the future like . But in very simple terms, |
|
| 65:41 | it means if you tell the operating that they don't move my program's execution |
|
| 65:46 | another hardware played on another another course that it stays on uh one of |
|
| 65:52 | course for the entire execution period. right. And one of the good |
|
| 65:57 | that I usually like to like to while uh doing these experiments, uh |
|
| 66:04 | a command called edge top. And what I would suggest is just have |
|
| 66:09 | console running on the same computer note execute the command h top. And |
|
| 66:14 | may need to uh load the model is again, has the name |
|
| 66:18 | Stop using model load at stop, on. Once you do that and |
|
| 66:23 | the command it stop. It gives a sort of a graphical interface and |
|
| 66:29 | you the utilization or how busy each . And each artwork that is on |
|
| 66:36 | particular uh compute notice it. now, what I'm going to do |
|
| 66:41 | I'm going to use a command from called loomer CPL. And what that |
|
| 66:50 | you to do is to spend your or in your program's execution to uh |
|
| 66:56 | single core or multiple course as you . So here's what we're going to |
|
| 67:01 | is we're going to simply execute our on 40. in general you start |
|
| 67:07 | zero but in this interface is the starts from one but and that you |
|
| 67:12 | uh do that by using the flag dash dash is if you find which |
|
| 67:19 | for physical CPU binding And coloured that my process to uh 40. |
|
| 67:29 | you can you need to also tell that can only allocate mm memory on |
|
| 67:36 | number zero. So things on these compute nodes, you have two |
|
| 67:41 | The only valid options for meme binds zero and one if you give it |
|
| 67:46 | other value is going to give you . So what number one is going |
|
| 67:49 | do is going to allocate the memory on the Focus. zero men did |
|
| 67:54 | as well. Okay. And once have done that you can simply call |
|
| 68:00 | rappel greed and reputable. And so this is going to do is it's |
|
| 68:06 | to call the rapidly program and rappel in turn is going to execute your |
|
| 68:13 | multiplication program that we certified in the told therefore the system call, let's |
|
| 68:19 | ahead and run it. And this how the uh education period looks |
|
| 68:26 | So while it is executing our I'll talk about what we're seeing |
|
| 68:32 | So here the rappel re program when tried to see what the architecture of |
|
| 68:38 | , of the view or the entire looks like. So what it's showing |
|
| 68:44 | is outside the bracket uh your hard ted I lied but it goes from |
|
| 68:52 | to all the way to 95 because have 96 hardware kids um running on |
|
| 68:57 | physical Of course and with two sockets that's 24 cores on each pocket. |
|
| 69:05 | inside the bracket. What you see the socket number. So here you |
|
| 69:11 | uh 40 or hardware fred I should belongs to the uh zero hardware |
|
| 69:19 | one belongs to talk at one and on. And so this is how |
|
| 69:23 | typical Numa architecture would look like. stands for a non uniform memory access |
|
| 69:29 | then I believe it it's going to discussed at some point. And |
|
| 69:36 | What we would notice is when we the execution in the edge stop output |
|
| 69:42 | do I you can see the first is now running at those 200% utilization |
|
| 69:48 | um not you cannot call it utilization at least it shows that it's uh |
|
| 69:54 | performing some work here. So that's you can make sure that your process |
|
| 69:58 | blinded to uh uh to the, the full number of people. And |
|
| 70:06 | believe it should take close to a to finish the execution. Let me |
|
| 70:16 | if there's anything I should have Yes. Uh while it's running, |
|
| 70:21 | other thing is we found the slides the resolution of Rappel is one millisecond |
|
| 70:29 | terms of time. Mhm. So program execution needs to be long enough |
|
| 70:34 | that you don't end up measuring some values. So it should be at |
|
| 70:39 | longer than one milliseconds. And ideally should be at least a few seconds |
|
| 70:43 | to get some good estimations of your consumption. And let me see why |
|
| 70:51 | not finish it When I tested it took 65 seconds and it's been |
|
| 70:58 | than 55. Now, I don't what went wrong. Right, let |
|
| 71:08 | try. Okay, let's finish. mind. Okay. Both. What |
|
| 71:15 | see here is the output of uh energy consumption that was uh measured by |
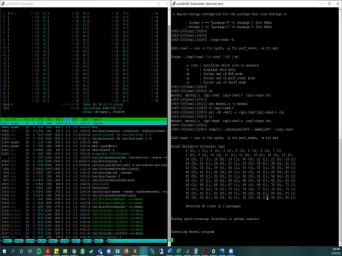
|
| 71:21 | interface. Now, understanding this output a bit confusing because The package-0 here |
|
| 71:32 | the actual socket zero on on your notes. And package-1 is the socket |
|
| 71:40 | on your on these companies notes. , be as I mentioned that Rappels |
|
| 71:47 | uh these uh energy consumption values from set of files And in that particular |
|
| 71:54 | , the socket one is actually listed Um before the before the socket |
|
| 72:02 | So that's why Rappel and was reading socket one value as a zero and |
|
| 72:10 | zero values as package one. So get confused between what this package means |
|
| 72:17 | wanted. Uh the package dash we need and uh what what you should |
|
| 72:24 | here is that because We executed our on Pocket zero, which is packaged |
|
| 72:30 | video. The uh energy consumption is higher than pocket one, presuming that |
|
| 72:39 | was not doing any significant work. though these uh access to leave, |
|
| 72:44 | people know they're not exclusive. We see any other processes running in the |
|
| 72:49 | , top output on the other side it. Similarly, your dear um |
|
| 72:54 | consumption is slightly higher Then the then Dirham Energy for the Socket one. |
|
| 73:05 | , What else I should mention Yeah, I think that's pretty much |
|
| 73:20 | . I mean, I had a question. Yeah. Um, so |
|
| 73:25 | say that the at least the output the raffle, read the one with |
|
| 73:29 | dash and the number. That's the package number, correct? Yes, |
|
| 73:33 | , yes. Okay, compact package zero is the socket zero, package |
|
| 73:40 | one is started one and just I'm my folks. But the rappel found |
|
| 73:47 | files where I treat the energy consumption socket one first and that's why it |
|
| 73:54 | to list pocket one, package So don't confuse this package zero, |
|
| 74:00 | with other package video. So the that number corresponds to the number you |
|
| 74:09 | in the binding statement, correct. just another question, How did you |
|
| 74:18 | to open another terminal in the same note? Uh Yeah. So on |
|
| 74:25 | windows, I just duplicated my depression once you do I live and whatever |
|
| 74:32 | when as soon as you get access your compute notes, just open another |
|
| 74:39 | and just do ssh in that particular note um number Riley and it's uh |
|
| 74:48 | you already have a job running on computer that should allow you to get |
|
| 74:52 | that companies. Not again with another . Thank you. Yeah, on |
|
| 75:00 | here again, you can just simply the command edge top and let me |
|
| 75:05 | make sure that we need edge top . So you need to load uh |
|
| 75:11 | called model for just to uh all load it stopped. That should give |
|
| 75:17 | the top model and then you can the command it stop. So this |
|
| 75:23 | this is uh just a way of sure that what you're telling in terms |
|
| 75:29 | process spinning is actually happening or not uh I guess you will make the |
|
| 75:34 | out. And also you can also if in case you didn't get exclusive |
|
| 75:42 | to the computer knows. You can make sure that if any other process |
|
| 75:46 | running on the on the other coast other hardware as well. Right. |
|
| 76:04 | other questions. Okay. If I'll make some comments. But so |
|
| 76:17 | this the first regarding game, I to go a little bit matrix that |
|
| 76:25 | shows on the right side of the sky like x processor type. So |
|
| 76:34 | talk more about that later when we about most defended codes. But what |
|
| 76:40 | is clear from this table or matrix , is that what is the common |
|
| 76:47 | in order to do load balancing? the threads are allocated to the sockets |
|
| 76:56 | the round Robin way. So you thread zero on South zero and then |
|
| 77:01 | one on one and you go back South zero and then socket one, |
|
| 77:05 | alternate all the time. What it show is that it also the standard |
|
| 77:16 | most common way or default way, that Threads are then allocated two cores |
|
| 77:24 | the same socket In Iran Robin So 1st, Um, downstairs whatever |
|
| 77:31 | labeled or viewed as 40 On Socket . And when it comes back to |
|
| 77:38 | a threat onto that socket, it the Core one. So it goes |
|
| 77:45 | the course. Um so after you in this case, 48 threads |
|
| 77:53 | then you have one core for one for each core. And then a |
|
| 78:00 | Harper 13 is enabled. Then it and start to allocate a second threat |
|
| 78:09 | each core in the same way as did the first. No, both |
|
| 78:15 | hours and sometimes the software provided by vendors allows you to change this allocation |
|
| 78:28 | . So, Yeah. But so can instead of doing things in a |
|
| 78:33 | robin where you are can control if want some threats to be on the |
|
| 78:39 | socket as supposed to an different sockets we'll talk about that later. But |
|
| 78:45 | quite sophisticated tools that industry as and was is providing to control allocation of |
|
| 78:55 | to course. Oh, um, and another comment I guess towards um |
|
| 79:06 | , in that after um things you want to experiment with. Let's just |
|
| 79:14 | what happens if you switch to which to allocate the friend, it's it |
|
| 79:23 | , you know, just switch everything if you get totally different behavior and |
|
| 79:30 | also the case that you run this different times. You may not end |
|
| 79:36 | on the same computer note and then may also show some different behaviors. |
|
| 79:41 | shouldn't be radically different, but it . And in part since these are |
|
| 79:53 | consumption numbers and the energy is um the temperature of the chips and |
|
| 80:02 | temperature of the chips are not the in the same server even and certainly |
|
| 80:07 | the same in different service because of cooling, it can't guarantee that temperatures |
|
| 80:14 | uniform across the cluster. So you get different yourself simply because of um |
|
| 80:20 | temperatures or that because the as well about a little bit more later. |
|
| 80:29 | power management on the nodes um may to run things at different frequencies in |
|
| 80:36 | to maintain certain temperatures which also affects power consumption, any comments from you |
|
| 80:49 | that matter, so yes, that that effect I believe will come |
|
| 80:57 | play when we deal with multi trailer um, when we start utilizing multiple |
|
| 81:05 | um obviously the temperatures going to be higher for the chest and in that |
|
| 81:13 | um I'm aware that intel processors and other processors for MD as well. |
|
| 81:20 | employ that uh technique where they lower frequencies of um of the course. |
|
| 81:27 | you can't expect them to run even the base frequencies that that the report |
|
| 81:33 | the in the process for documentation of , the frequencies can be even lower |
|
| 81:39 | that. Yes um um and as , pointed out the always if it |
|
| 81:54 | freedom, it's potentially dynamically move things and the reason for that even if |
|
| 82:03 | are the single user on the system because it also has an idea of |
|
| 82:10 | ist that's a function of juice and . So obviously the core that runs |
|
| 82:19 | code is dissipation, requiring more power and get warmer and at some point |
|
| 82:26 | may choose to move the threat to other core that is not busy and |
|
| 82:30 | temperature. So that can also introduce in hard to understand measures so that's |
|
| 82:40 | but suggested when you want to get or something, make sure that you |
|
| 82:46 | what to expect in terms of variability try to limit it by forcing things |
|
| 82:53 | be as specific as your camp. . And one more thing not uh |
|
| 83:10 | know I said it earlier but um runtime of your program should be long |
|
| 83:16 | again. And the reason I'm defeating is because for some test cases that |
|
| 83:21 | will get in the assignment, the will be quite small. Um And |
|
| 83:26 | in that if you may need to special so you will need to wrap |
|
| 83:32 | compute part of your programs in a that it runs for at least a |
|
| 83:36 | seconds so that you get some close a close to accurate um Energy consumption |
|
| 83:43 | from brussels and then you get an consumptions for each iteration once you know |
|
| 83:52 | number of iterations. All right. pretty much it. I'll stop |
|
| 84:09 | Yeah. Ok. Yeah. Don't any other companies any other questions. |
|
| 84:16 | There's one question in the chat Regarding assignments. When I tried running the |
|
| 84:24 | events, 40 lb data cache The data misses for interchange matrix multiplication |
|
| 84:32 | higher than that of classic. Uh . These are in terms of the |
|
| 84:40 | being cash. This is not the cache misses. And excellent. Is |
|
| 84:47 | that she's run at several times and happens every time. Especially for them |
|
| 84:52 | them case. Right. Yeah. Yeah, I do. I see |
|
| 85:01 | you're saying. I don't have possible explanation on top of my head |
|
| 85:08 | if you send us your actual at point, I will take a look |
|
| 85:16 | see if I can have a good for what, why that may |
|
| 85:22 | But I don't have one intuitive Or one right now. Sorry. And |
|
| 85:39 | not. They prefer to answer, we'll try to shed some light on |
|
| 85:55 | . So the next lecture, I talk a little bit more in detail |
|
| 86:03 | on the memory system works. And may help explain a little bit of |
|
| 86:11 | numbers, but we'll find out. for those of you are taking an |
|
| 86:20 | class and familiar with cash. It know it already, but I don't |
|
| 86:24 | everyone necessarily know that all the different policies and the consequences of that. |
|
| 86:31 | that's what I wanted to go through and I'll do that next time for |
|
| 86:53 | assignment. Do I need to take high level and low level. I |
|
| 86:59 | most of all of the events that asked can be accessed by a high |
|
| 87:06 | interface of copy. Is that what asking? I don't think we asked |
|
| 87:17 | any uh, events of any native in the assignment. Okay. |
|
| 87:41 | Yeah. Any other questions. Okay. It's not. And so |
|
| 87:57 | and the lecture in the classroom and for those that prefer that. And |
|
| 88:05 | on yes, the university doesn't change mind. That means the kind of |
|
| 88:13 | opening is should be over. So means elections will be held in the |
|
| 88:18 | with zoom access as well going Starting next week. All right, |
|
| 88:32 | you so much. Now I see of you are most of you in |
|
| 88:36 | classroom next |
|