| 00:00 | Hello, everyone. Welcome to to lecture today. We're going to talk |
|
| 00:04 | logistic regression. This is probably the one of the most classical machine learning |
|
| 00:11 | . This is the very basic classification learning algorithm, and I give everyone |
|
| 00:19 | turns or wants to learn. Machine well learns is as their first on |
|
| 00:27 | algorithms. But before I do I just want to spend some time |
|
| 00:32 | explaining the buyers and various variance problem I touched on last week. But |
|
| 00:39 | probably didn't do a good job explaining . So why spend time talking about |
|
| 00:45 | is because if you if you if learn and a chain a motion anymore |
|
| 00:53 | from your opinion that said, Can find that your machine learning model is |
|
| 00:59 | performing as well as you expected the likely you have rain to either a |
|
| 01:05 | on variance problem. It's very important figure out whether you are telling you |
|
| 01:12 | dealing with Spires on various problem because tells you what to do next in |
|
| 01:17 | to improve your motion alone in Remember that last week we also talked |
|
| 01:22 | the different strategies, different things you do on the order to deal with |
|
| 01:28 | and various problems. So let me . Let me use this simple. |
|
| 01:32 | said that you have already seen several on the why access is that. |
|
| 01:37 | is a price on the horizontal axis is the size of house. So |
|
| 01:43 | trying to predicting the housing cops price price based on the side of the |
|
| 01:48 | of the house. In this if we assume if our hypothesis too |
|
| 01:55 | , For example, if we assume this is a linear relationship between price |
|
| 02:01 | on the size, then our machine model will look something like this basically |
|
| 02:08 | line. In this case, it's that we are. We're under fitting |
|
| 02:13 | training data because we get because this line cannot capture um, all the |
|
| 02:22 | information. On the other hand, you receive your machine learning model is |
|
| 02:29 | complicated, for example, here, assume that we use a polynomial model |
|
| 02:37 | two degree for on our mission. mortal will look something it kept. |
|
| 02:46 | feeds data really well because you can can tell that this and yet curve |
|
| 02:52 | all our training data point. So but probably because. But because of |
|
| 03:00 | , this morning probably will not. as well to new that's set in |
|
| 03:05 | case way have to over feed the . Also, in this case, |
|
| 03:15 | we assume this more than it has not too simple linear regression case not |
|
| 03:23 | complex that liking this case where we a problem after the four degrees. |
|
| 03:27 | we simple assume a polynomial moored up to 2 degrees in this modern learning |
|
| 03:36 | that you end up ways will look like this. In this case, |
|
| 03:41 | hope you agree with me that this is probably the best more than that |
|
| 03:46 | we can use to predict how's housing based on the side of house. |
|
| 03:52 | that literature in machine learning community people also a user, I use the |
|
| 04:01 | buyers Hi bear buyers to describe this feeding problem and high variance to describe |
|
| 04:10 | over feeding problem. So here's the most likely in most cases inspires problem |
|
| 04:19 | due to our oversimplified assumptions. For , we assume a linear model when |
|
| 04:26 | through our training data actually were generated a non only highly nonunion model. |
|
| 04:33 | will lead to under feet in the data, meaning that our machine learning |
|
| 04:41 | Mrs some of the important information important , important relationships. Among the training |
|
| 04:48 | on theology and the various problem comes the fact that our machine learning model |
|
| 04:57 | to center Dave probably excessively SEB sensitive small variations in the tree and it |
|
| 05:04 | like black noises. So in this , it will lead to overfeeding that |
|
| 05:12 | , meaning that anymore is too powerful it captures irrelevant or sometimes even you |
|
| 05:25 | it features young training did. This happens. For example, This |
|
| 05:30 | This will happen if we assume a year model when our date actually are |
|
| 05:35 | leaning. It turns out that these things buyers and variance there's a well |
|
| 05:46 | bar bias and variance trade off. what? What does that mean? |
|
| 05:52 | ? What this means is that if increase mortars complexity, for example, |
|
| 05:59 | we increase the polynomial features, increase number of parliament features and the decrees |
|
| 06:07 | parliament features, that's what typically increase various because we are moderates now more |
|
| 06:15 | of capturing a very small variations. date, so the various will increase |
|
| 06:23 | the center. At the same the buyers will be reduced, and |
|
| 06:28 | , if we reduce the more those city. For example, if we |
|
| 06:32 | from parts unknown and agree to back linear regression more the platinum a degree |
|
| 06:38 | . Obviously we variances decrease because because modern art becomes a senior, so |
|
| 06:44 | it becomes incapable of capturing the small variations but the buyer's increases so you |
|
| 06:52 | see that there is any buyers and trade off. In most cases, |
|
| 06:59 | you increase wine, you will, , reduce the other one. It |
|
| 07:05 | very difficult to reduce both buyers and , So this is incoming in any |
|
| 07:13 | . This is very well known as Barrys and Byron Street off. I |
|
| 07:19 | that gave you a better understanding of spires and variance problems. Okay, |
|
| 07:28 | we're going thio fuckers on today's Largest regressions. I'm going to talk |
|
| 07:36 | the basic idea and concepts behind things . I also try to expend, |
|
| 07:44 | and help you to understand intuitively what regarding does also, for those who |
|
| 07:53 | interested in learning more about how to a cost function. Was it about |
|
| 08:00 | ? But feel you're free to escape part because this is not required. |
|
| 08:05 | is beyond the scope of this class for your lab exercise my homework, |
|
| 08:11 | example. You do not need to how to develop cost function. And |
|
| 08:15 | if you work in industry and you with largest refugee on a daily |
|
| 08:22 | And if you, if you are open sauce and library like second learn |
|
| 08:28 | tensorflow. Still, you do not to know how they cost function for |
|
| 08:34 | record. What the back. This purely for those who are interested in |
|
| 08:38 | more about cost function and optimization. , out, I will also give |
|
| 08:45 | the shows how to implement this operation second learn. Okay, so first |
|
| 08:54 | about largest regression is that these easy method remember that last week we talked |
|
| 09:01 | there are two basic categories for machine algorithms. A wise regression. There's |
|
| 09:09 | classification regression, regression always predicts and numerical values on classification always predicts |
|
| 09:23 | , and the category cool numbers like Here, the 123 simply means Class |
|
| 09:30 | or a category one category to cutting . So the first thing I want |
|
| 09:36 | make clear is the largest Russian. seize a classification matter despite the fact |
|
| 09:43 | it is called the largest regression. this name is very, very |
|
| 09:47 | But just keep in mind that this a classification algorithm rather than a |
|
| 10:00 | So here's just a few examples of registry largest triggering a logistic regression |
|
| 10:06 | For example, emails we want to emails you to spam on non |
|
| 10:15 | So basically a yes or no Um, another, um, application |
|
| 10:22 | largest regress. And he's on the transactions we want to classify. Want |
|
| 10:29 | detect if a thief online transaction it's or not again, with this case |
|
| 10:38 | where this is a yes or no ? Yes, it is fraudulent from |
|
| 10:42 | is a fraudulent transaction. Now it not, um, another application using |
|
| 10:49 | class occasion whether patient's tumor is malignant or benign for self driving |
|
| 11:01 | registration is also useful because it Classified data into pedestrians are no the |
|
| 11:15 | problem that I used last week to supervised machine learning. It is, |
|
| 11:21 | is. It can also be be using largest regression again. Here we're |
|
| 11:28 | about whether it's a cat on not so in an application to |
|
| 11:34 | To Johnson's problems. Largest reversing also also has also found, and its |
|
| 11:40 | it's using, for example, sort all the detection. In this |
|
| 11:45 | you might want to predict whether a model sells a particular cell. Your |
|
| 11:53 | is either sort on no. And this week's life exercise, you're going |
|
| 12:02 | classify about 10,000 seismic creases into the is good and bad. So you |
|
| 12:12 | these that largest regression in all these . It serves as a binary, |
|
| 12:20 | fire. So we only have two yes or no or category one Katherine |
|
| 12:32 | . So the largest regression, and is a supervised learning algorithm. So |
|
| 12:37 | just a recap of supervised learning. that for supervised learning. Our training |
|
| 12:44 | said training did set consists of two . The input variable X and label |
|
| 12:49 | why, says LaBelle's why you can that as output variables are the true |
|
| 12:58 | . So she wasn't what what he . Learning out with them trying to |
|
| 13:03 | is to come up with the mapping F that can that can maps this |
|
| 13:12 | variable two out Once, once this functions learned the next time when there's |
|
| 13:24 | new instance, X comes in, can just use the learned F adds |
|
| 13:29 | new data to predict. So for , sir progression the outfit. The |
|
| 13:41 | will always be either zero or one this case for the weekend. Simply |
|
| 13:49 | zero as negative class. For It's not a thought. It's not |
|
| 13:53 | fraudulent transaction. It's not a it's a scam. And all also, |
|
| 14:07 | can understand these category one as positive , for example. Yes, it |
|
| 14:14 | a sword. It is a and it is the fraudulent transactions. |
|
| 14:27 | this is a linear regression model that have already is in several times. |
|
| 14:33 | he also implement these in the notebook . I'm here. I'm using this |
|
| 14:40 | satisfaction prediction as example. So here have one feature one put one put |
|
| 14:48 | one feature, which is the TV capital. In other words, we're |
|
| 14:52 | to predict the life satisfaction H backs on the single feature TDP X. |
|
| 15:02 | here's this zero See the one that more the parameters were trying to learn |
|
| 15:08 | training date. In this case, only have one input variable or one |
|
| 15:15 | . So this is also called linear . For one feature, you're just |
|
| 15:21 | down here that you can understand the very bow as as feature. So |
|
| 15:28 | , if there's wine put very more a means and we only have one |
|
| 15:34 | . So we also talk about general this linear regression for one feature to |
|
| 15:40 | regression for multiple features. The basic is very simple. Also, instead |
|
| 15:46 | having only one people variable here we quite a few input variables X want |
|
| 15:51 | to up to extend each one of represented 11 He could feature one feature |
|
| 15:57 | put variable. For example here, one month the GDP extrude man free |
|
| 16:01 | care three, maybe education, ex and the air quality So on and |
|
| 16:08 | forth. So we have a problem is is to predict life satisfaction. |
|
| 16:14 | on all these features, X one after accent and here see that they |
|
| 16:21 | see the one Sorry, I should put down to about two feet and |
|
| 16:27 | are the more the parameters were trying learn from training. Um, I |
|
| 16:32 | hear multiple input variables correspond into multiple . Oh, that's what I put |
|
| 16:45 | here. So we can We can need more general science on this speech |
|
| 16:52 | acts That is our predictions and X that is our future one next to |
|
| 16:57 | future to 3 53 Accident on the In this is a more primitive |
|
| 17:07 | Turns out that we can use linear using Ze Major expected multiplication to simplify |
|
| 17:17 | morning and summarize it in the more form here, State vector transposed Have |
|
| 17:27 | vector x after years heart. he's defined a visa and plus on |
|
| 17:34 | one vector axes also a m plus by one vector. So for logistic |
|
| 17:46 | , remember that way This is a classifier. So we out prediction will |
|
| 17:52 | yes or no. But Congress, predictions, always will always be is |
|
| 17:59 | zero or what? Oh, making prediction to be exactly zero or one |
|
| 18:13 | out to be really difficult. So a nothing similar thing we can do |
|
| 18:18 | to make sure that I were predicting for within this range, this Ranger |
|
| 18:25 | 0 to 1. But the problem the linear regression problem without foot of |
|
| 18:33 | regression models that this output of linear model it can be anyway view |
|
| 18:41 | It can go from medicine for too, to infinity. For |
|
| 18:47 | Suppose you put the future while you feet here. He's obviously that prediction |
|
| 18:54 | we learn a senior regression model guessing that's the street line on. But |
|
| 19:01 | the output values can be anywhere from Infinity too infinite. So obviously we |
|
| 19:11 | to do something different in order to sure that output always within our |
|
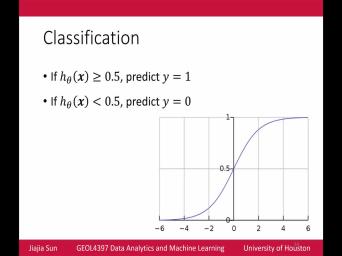
| 19:18 | always for within this rink. So that is where the largest logistic function |
|
| 19:25 | into play. Logistic function is defined this way one over one plus e |
|
| 19:35 | menace X. This is also called function waken. If you plot of |
|
| 19:43 | , this is this is hardly a regression. Looks like first the first |
|
| 19:53 | know, he said. This is smooth function, and also you noticed |
|
| 19:58 | as C input variable X goes to , the ultra value approaches line and |
|
| 20:15 | , if the input variable keeps this outfit buh the Afghani will be |
|
| 20:26 | closer and closer to zero and twins variable is zero Um, the out |
|
| 20:32 | the butt. The out foods value 0.5. A nice thing about this |
|
| 20:41 | regression logistic function is that it can any real number from Madis Infinity, |
|
| 20:48 | to a real number within this So what? No matter and how |
|
| 20:54 | or how small this input Vera Maxie's T X will always be within this |
|
| 21:04 | zero and why? So how do go from largest reversion? It's our |
|
| 21:11 | regression to largest regression. Well, is the on the model we have |
|
| 21:17 | for largest regression. And I also that his output value from this more |
|
| 21:24 | he's it can be anything from minus infinity. Remember, we also we |
|
| 21:35 | talked about largest regret largest a function can map a real number two, |
|
| 21:43 | rule number within this rich. So want to make sure that the output |
|
| 21:50 | always for within this wrench we simply the logistic function to these products |
|
| 22:03 | That is what he was thinking. this is the logistic function. We'll |
|
| 22:09 | more of the function that you saw few slides ago. One property with |
|
| 22:17 | function, that's the output will always within this range, which is what |
|
| 22:22 | we want. Another good thing that this property is that we can easily |
|
| 22:32 | out. Convertible on that is the of X as the probability What was |
|
| 22:39 | reason is that simply reason simply sends parties within this range. So that |
|
| 22:47 | the interpretation in terms, probability just natural thing to do. So, |
|
| 22:55 | example, yes, that's what I what I would I'm here. We |
|
| 23:03 | interpret h of x as the estimated that why you won X So, |
|
| 23:13 | example, I just I have a simple example on email scam detection, |
|
| 23:21 | example Here, my input features, two by one vector. The future |
|
| 23:30 | using its simple is a number of words. If people have found that |
|
| 23:37 | scam emails, they have something in , that is the capers. For |
|
| 23:42 | , if you see something like for also, for example, cash, |
|
| 23:49 | example Amazing. So these are the words that the common to scam emails |
|
| 23:56 | one way to detect scam emails is to counter. To detect the existence |
|
| 24:03 | these and also to count is no of these killers or their many |
|
| 24:10 | There's a long list of the Was amore key words you see from |
|
| 24:17 | list in your email, the more it is a scamp. So in |
|
| 24:21 | case, for example, we trim largest regression based on the input this |
|
| 24:26 | feature and also assume that we are output value from largest yr Ri |
|
| 24:34 | Poland. A two way can simply this outfit value as as that there |
|
| 24:45 | the 82% chance that this email Well, some people don't like |
|
| 24:54 | because if you tell people that there's chance your email use them. That |
|
| 24:58 | make sense to some people. People simply want to know. Eve my |
|
| 25:05 | . If my email spam on just simple yes or no problem. |
|
| 25:11 | that case, my simple thing. can do it just to do that |
|
| 25:16 | me. If the output value from regression is larger or no less than |
|
| 25:23 | off point, pop conned 0.0.0.5, is pretty quiet for a while. |
|
| 25:27 | if the value is less than point . We simply predict Y equals |
|
| 25:40 | So that's pretty much that's that's the idea is behind largest regression. So |
|
| 25:45 | I want to spend some time explaining this what this is and trying to |
|
| 25:53 | you develop intuitive understanding of what the through Britain does. So this is |
|
| 26:01 | we talk about just one second This is how we do the classification |
|
| 26:07 | on largest regression. If the output larger or Yukos and it's like is |
|
| 26:12 | or Laugesen thereupon five, we predict positive class. If the output various |
|
| 26:19 | point 0.5 predicting Y equals zero. again, this is like this is |
|
| 26:30 | the largest, longest day function looks . So let's take a closer look |
|
| 26:39 | this logistic function. Um, my here for you guys is to think |
|
| 26:47 | when this happens. So remember that of X, um defined as t |
|
| 27:04 | transpose times, Max and the as blue line. That is how the |
|
| 27:12 | function Z looks like this easy here can simply can't get similarly we can |
|
| 27:19 | define Z equals equals faith transports packs age. Theater X is equal to |
|
| 27:38 | . So if you look at this closely, you probably will. You |
|
| 27:42 | have already found out that whenever fate X, it's larger. Zero. |
|
| 27:57 | have aged thief ex you cruise for 0.5. And similarly, if h |
|
| 28:09 | eight eggs smolders and meet me that t of transport eggs smaller than upon |
|
| 28:17 | five In other words, eve t the smaller than 50.5, that means |
|
| 28:24 | we are talking about see smaller than . Remember what defines E as 50 |
|
| 28:33 | , safe transport time, blacks. that means state transpose times x smaller |
|
| 28:38 | zero. So whenever this happens, have t of the So we have |
|
| 28:45 | of then faith transpose Times X wanted , um, 0.5, that is |
|
| 28:55 | city. So whenever let me put here and we're ready down. So |
|
| 29:03 | H bags is smarter than on five Predict why, Michael zero equipment way |
|
| 29:10 | saying this is Yves St Transposed X smaller than zero. We predict y |
|
| 29:18 | so that that is what I wrote here. Um, if state transposed |
|
| 29:25 | is equal to all ages and zero pretty like one if data transpose times |
|
| 29:31 | smaller zero Pretty wife was here. what? I it was on |
|
| 29:38 | It's exactly the seam is equivalent to part. Okay, Next we'll Andi |
|
| 29:53 | Thio. Explain what? What this means. So to do that I |
|
| 29:58 | Thio. Here's a simple example So here we have This is our |
|
| 30:03 | is our training set. Come again we used the red crosses as potted |
|
| 30:10 | and the circles as negative class on words I the Red Cross. Of |
|
| 30:16 | one to class wine and these circles to pass you and that we want |
|
| 30:24 | classify, um, this data using regression So in this case because in |
|
| 30:34 | case, we have to put So that's why we have we have |
|
| 30:40 | like this said zero Plus they want wanting to x two. You can |
|
| 30:46 | expressed this thing as stated transposed time were Satan. He's going to faithfully |
|
| 30:58 | Saito wine. I hate it and X because X zero excellent. |
|
| 31:07 | next to relax zero will always be . So we haven't talked about how |
|
| 31:23 | hotter learns it's more the perimeter Um what about that. But assume |
|
| 31:31 | we have implemented largest regression and we We learn we have learned this more |
|
| 31:37 | perimeters. And, uh, we that think that they're all equal to |
|
| 31:43 | three. Some wine equals one. in other words, we predict y |
|
| 31:57 | one. Whenever this is true, can always move without. We can |
|
| 32:11 | move this ministry to the veteran so that becomes x one plus X |
|
| 32:18 | larger than three. Conversely, will Michael zero if Manus three plus X |
|
| 32:39 | last text to smaller than zero. , you can also right this thing |
|
| 32:47 | select different form. Let's move this three to the right hand side, |
|
| 32:52 | becomes X Y Class X two smaller three. So you want to explain |
|
| 33:05 | this means? Let me let me write down Listen creations that to you |
|
| 33:13 | problem Much more familiar ways X one X two equals equals three. This |
|
| 33:20 | simple. If we plotted this up onto these x wax to plan, |
|
| 33:27 | simply is storyline. Passing through is on x one and three annex. |
|
| 33:36 | to these these x one flax next equals three It turns out that this |
|
| 33:49 | space on the top right can be some rice as x one plastics to |
|
| 34:03 | him. Three if you look. you look at what we read on |
|
| 34:11 | , it simply means that we will , Like the one Eve this data |
|
| 34:21 | is located in these half space. was a tough right thanks. And |
|
| 34:34 | , the half space to the bottom that can be mathematically some rays and |
|
| 34:42 | one plus extra smaller than three. is what we have here. So |
|
| 34:47 | also he's 1/2 space. So what says is that will predict y equals |
|
| 34:53 | whenever the state point's located in this space. And we will. So |
|
| 35:03 | notice that this straight line here that the X one plus extra good |
|
| 35:11 | It separates this positive class from this class. So we will, |
|
| 35:21 | terms this tree line as deceiving boundary it is a boundary between this posted |
|
| 35:34 | and negative class. If you don't follow me, please feel free to |
|
| 35:47 | here and spend some think, spend time thinking about, um off these |
|
| 35:55 | here. I guess the important point want to understand What I have done |
|
| 36:02 | is to realize that on base increasing to a street line. And these |
|
| 36:12 | actually corresponding to these cough space to top, right? And these quantity |
|
| 36:24 | to the half space to the bottom and that will help you understand. |
|
| 36:31 | , what I did here. Now let's consider a more complicated example |
|
| 36:44 | hear. I have supposed again and is my training data, and I |
|
| 36:49 | posted class marked highlighted in dressed crosses neck. Next class in it's open |
|
| 36:55 | cups in this case. So this the we also have again, we |
|
| 37:01 | have two features. So this is largest tree regression that we you have |
|
| 37:07 | sin from previous lights. I'm But probably have already realized that these largest |
|
| 37:16 | based on these small there will not able to capture will not be able |
|
| 37:22 | , um, find out the boundaries the positive positive class and Arctic |
|
| 37:28 | Because these theme this model can only linear boundaries like this example. So |
|
| 37:43 | question now is that can we find can we discover? Can we develop |
|
| 37:51 | nonlinear decision Boundaries using largest river got . Well, the answer is |
|
| 37:59 | And, uh, it was a to do that is to adding higher |
|
| 38:07 | degree polynomial features like these X wine X two squared This'll Stroot look for |
|
| 38:18 | to you guys because last time, when we talk when we talk about |
|
| 38:27 | Z remedies for undefeated. One of we can do is to, um |
|
| 38:33 | when we're under feet. Today, , if if you want to phone |
|
| 38:39 | that problem, one thing we can is to add more features, for |
|
| 38:43 | , the higher degree polynomial features that make your learning more than more capable |
|
| 38:50 | capturing Lundeen year behavior. Nonunion boundaries your data. So this is what |
|
| 38:59 | This is what we have from last video here. A similar thing simply |
|
| 39:05 | can simply add more features, more features of high degrees in order to |
|
| 39:14 | the complicated decision boundaries. In this , again, we can rewrite this |
|
| 39:27 | inside thes parentheses as faith transpose where St Symphony teeth of their |
|
| 39:37 | Think wine two and three, beautiful x. Okay, excellent. Thanks |
|
| 39:49 | sorry. We also have X zero excellence merit. And next to square |
|
| 39:59 | . If we have help office function looks like this. Basically, it |
|
| 40:06 | that we will predict. Like was like would want? If Sorry, |
|
| 40:11 | forgot to mention one thing and supposed learning we learned that the model prints |
|
| 40:17 | we will learn are the following 60 minus one state one 0203 minutes |
|
| 40:30 | I'm sorry. State of three Um, he's wanted for is why |
|
| 40:37 | visible with that? That means that predict Y quit one. If this |
|
| 40:44 | is larger or larger, equal to again Yonder took that. Understand |
|
| 40:53 | I will. I will revise this in a slightly different form as a |
|
| 40:59 | X one scrap plus extra square is to our larger than one. But |
|
| 41:04 | probably already recognize that these if I up if I plot up this in |
|
| 41:10 | ex Max too plain, um, correspondent to x one squared X two |
|
| 41:24 | equals one And all this space outside outside this this decision boundary can be |
|
| 41:36 | some rest sex one squared, plus to scratch. Larger than why so |
|
| 41:42 | this case, What we have developed far is to commit some residents as |
|
| 41:49 | falling will predict Y equals one. , um, my dad corns force |
|
| 41:56 | these circum in this case, this that is our decision boundary. |
|
| 42:12 | turns out, turns out that we we can do We can't keep adding |
|
| 42:16 | polynomial features Learn more my more complicated boundaries. For example, if you're |
|
| 42:23 | simple example where we just keep adding polynomial features you this kid, for |
|
| 42:30 | Excellent squared times X two x two one squared extra squared Exline cooked actitud |
|
| 42:37 | this is already the fourth on the of polynomial features. And because of |
|
| 42:43 | higher order putting your features, it turns out that these parts this |
|
| 42:54 | largest regression in this form is capable learning more complicated on boundaries, for |
|
| 43:01 | , something like like these. so next thing I want to talk |
|
| 43:11 | the seal cost function for cost function lunch is through regression. This is |
|
| 43:18 | punk thing because I remember that on or three weeks ago when we talk |
|
| 43:24 | machine learning with talk about what learning . Wait, really talk about cost |
|
| 43:34 | , learning. I mean man, many cases, it's important means that |
|
| 43:40 | want to minimize the cost function. next I want to spend some time |
|
| 43:45 | about see cost function for logistic So So here I summarized on training |
|
| 43:52 | as as this least so where we input variables. First input feature the |
|
| 44:04 | data input data, First label, label, and suppose we have M |
|
| 44:12 | and each one of each one of x I on each one of these |
|
| 44:17 | data. He's eight and buy them one by one vector because we have |
|
| 44:24 | features. Plus, um, plus ex not which is always because equal |
|
| 44:39 | one. So a note is that materials in the fall from slide 25 |
|
| 44:49 | 33 explains how to develop the cost for logistic regression. Again, this |
|
| 44:56 | beyond the scope of this class. you are so please feel free to |
|
| 45:01 | them. And but if you want learn more about cost function as well |
|
| 45:07 | optimization than the following, materials will useful look. So in order to |
|
| 45:16 | a cost function for largest reverie, let's consider the following. So this |
|
| 45:25 | the cost function that we have used linear regression. Right? This this |
|
| 45:31 | a state of X I that is prediction prediction for the ice data. |
|
| 45:41 | why I that the sea label or true answer for the I've data. |
|
| 45:48 | these thing magazine difference between eternal prediction the labels again, As you |
|
| 45:58 | we have this squared and then with these differences over all of our training |
|
| 46:07 | . So this is cause function we been using for linear regression. But |
|
| 46:17 | out that this this cost function is a good one for logistic regression. |
|
| 46:22 | reason has something to do with these comebacks and comebacks function. So I |
|
| 46:28 | to do next. I want to just some time explaining this important |
|
| 46:36 | So this is very important for So what I mean by they seize |
|
| 46:46 | wth the cost function. When it to often, musician came. You |
|
| 46:53 | have to two time. You have types of cost function wise comebacks the |
|
| 46:58 | known comebacks or turns out that there's types of cost function. We have |
|
| 47:04 | different behaviors for example, on the comeback stopped, emit and cost function |
|
| 47:11 | look something like this or just like all this. I don't know why |
|
| 47:17 | is already always happens. So it many, many local minimum. So |
|
| 47:27 | one of this is a local, know, And this gives this is |
|
| 47:30 | is probably the global minimum because it the smallest among all of the local |
|
| 47:40 | . So they see that no commune of the existence of the life on |
|
| 47:48 | local minimum depend young where you start optimization from. For example, if |
|
| 47:59 | if your initial remember that way greedy dissent, we always initialize our more |
|
| 48:09 | Sit. If if Well, if were initialized If our initial mother perimeter |
|
| 48:16 | this place, then you can imagine by implementing the greedy in dissent, |
|
| 48:23 | will eventually end up some somewhere So we will be able to find |
|
| 48:29 | low communion solution. But this is the best solution we want. |
|
| 48:34 | we want we want the best solution , um will come from this global |
|
| 48:42 | . But because of these existence, this money off this local minimum and |
|
| 48:49 | of the greedy in the way How and the Senate works. Chances are |
|
| 48:55 | I'm not chancing. Most likely you end up in a local minima. |
|
| 49:04 | our cost function is contracts, then will look something. Magazines. It's |
|
| 49:09 | a bow shaped, um, cost . Well, good thing about these |
|
| 49:16 | cost function that it has only one any, any minute. Any solution |
|
| 49:24 | end up with these three global So when it does it help, |
|
| 49:30 | has nothing to do with where you your in issue right where you started |
|
| 49:36 | descent from or you can start from because I'm here. You end up |
|
| 49:42 | this global solution. Are you from from here, You and with |
|
| 49:46 | We're also gonna end up in the , um, global minimum, so |
|
| 49:53 | as you're learning rate is not too . So for optimization, if ever |
|
| 50:01 | , we would like to work with cost function. The reason that we |
|
| 50:10 | want to get get stark in La minimum while local human east us is |
|
| 50:17 | is a solution to our problem. it is not the best one. |
|
| 50:20 | best solution always comes from the global . So with that knowledge, he |
|
| 50:29 | a mind. Now let's let me . Let me walk you through the |
|
| 50:35 | we develop a cost function for comebacks function for logistic regression. Now, |
|
| 50:44 | make things simple, let's consider only single training example X and associate |
|
| 50:50 | Why the basic idea for developing cost is that if our prediction H State |
|
| 51:00 | Axe is very is very different from true label, while we want to |
|
| 51:06 | these one prediction heavily in our cost and cum. Conversely, if our |
|
| 51:12 | age data backs is very, very to the true label than we, |
|
| 51:17 | don't want to penalize the critic for other words we want to penalize thesis |
|
| 51:22 | this good prediction as less as I guess you can Simple understands the |
|
| 51:32 | function as a way to impose different for different predictions. So for largest |
|
| 51:42 | and remember that our prediction will always 10 and it turns out that the |
|
| 51:52 | function that having this form looks So let me let me rephrase |
|
| 52:05 | So this is a basic idea for a convict, a cost function for |
|
| 52:10 | regression. It turns out the one of actually implementing this idea is to |
|
| 52:17 | a logistic, usually cost function that has this form here. So now |
|
| 52:24 | know this looks a little bit a bit complicated to you, So let |
|
| 52:32 | explain what this means. So let's just consider the first case when the |
|
| 52:38 | labels want, when the when the answer is one. If that's the |
|
| 52:45 | , if the twenties line the cost social ways on this, why could |
|
| 52:56 | is a menace log of each other's ? Well, we can plot up |
|
| 53:05 | function in this plane in this it would look something like so this |
|
| 53:14 | horizontal axis correspondent to 18 of So the manners log it, |
|
| 53:22 | Um, well, we can figure out by looking at what happens when |
|
| 53:28 | detective actually won. When you With one, this is zero. |
|
| 53:35 | when age state of X, he's to zero. This become positive |
|
| 53:44 | So it would look something like So this is Matt Manners. Lock |
|
| 53:55 | theatre Max. So what this means these at Wednesday's when this prediction is |
|
| 54:15 | . When this prediction is one. means that our prediction is the same |
|
| 54:21 | the transit. With Jessica. It's , you know what in this |
|
| 54:27 | because the prediction is very close to label, so we don't want to |
|
| 54:32 | this prediction. Therefore, we have zero here and Congress. The prediction |
|
| 54:39 | very different from the true answer in case meaning that's the prediction is close |
|
| 54:43 | zero. In this case, the is so different from our our Trans |
|
| 54:49 | with one. So we want to a very, very high penalty on |
|
| 54:56 | prediction. In this case, when one's predicting that one Z, the |
|
| 55:05 | actually goes to infinity so that that's I did. I'm here when the |
|
| 55:10 | , when this prediction is one the of zero and when the predictions close |
|
| 55:22 | zeros cost infinity, so it captures intuition that, um, ive the |
|
| 55:28 | is different from our label. We to penalize this'll any other than have |
|
| 55:36 | . So now that's a case for equal to one. So now let's |
|
| 55:41 | a look at what happens when what happens to the cost or to the |
|
| 55:46 | will invite zero. So when why zero? We are looking at a |
|
| 55:53 | function that has this form, and way we can lock it up by |
|
| 56:02 | the following, if so again, the horizontal axis that is the age |
|
| 56:08 | of acts. So when each state X equals zero, then this cost |
|
| 56:22 | zero. And when a state of you one, this is cost |
|
| 56:37 | Log one minute. State, state X. This is gonna be |
|
| 56:46 | So, um, it's something that like this infinity. So when this |
|
| 56:58 | this is true, this is our true label zero. When our prediction |
|
| 57:03 | zero, that means that our prediction matches our labels and we don't want |
|
| 57:08 | any and it cost or any penalty this prediction. Therefore, we have |
|
| 57:15 | a penalty zero. And when these one When's when's the actor answer is |
|
| 57:22 | zero. We want Panelist this prediction so. So that is essentially what |
|
| 57:29 | cost function does. It penalizes prediction when the prediction is different from the |
|
| 57:36 | , and it penalizes the prediction much heavily if the prediction is similar to |
|
| 57:43 | label. So this is a this out to be the cost function that |
|
| 57:49 | have developed for calling for largest Um, Waken turns out we can |
|
| 57:58 | rewrite this cost function in a more form on that looks like this. |
|
| 58:04 | this equation is exactly the same as swine. Remember that this is this |
|
| 58:18 | only the cost function for one single example for multiple. For many, |
|
| 58:25 | training examples, we will just simply them up. So this part is |
|
| 58:33 | same as this part. But for training examples way need to some Some |
|
| 58:43 | has a cost over all the training . I guess if you want more |
|
| 58:51 | , we should always we should also see superscript i above accent. So |
|
| 59:03 | is what, um that easy final for the cost function for the largest |
|
| 59:14 | . A good thing. I'm positive this is convex, meaning that there's |
|
| 59:19 | one solution. The whatever is a you end up with. That is |
|
| 59:24 | global minimum solution. That is the solution. Best solution. Okay, |
|
| 59:31 | this is the cost functions as you saw And remember that learning is all |
|
| 59:37 | minimizing this cost function So bye. this by minimizing. This is the |
|
| 59:44 | of this cost function. We can off a 10 the optimal motor |
|
| 59:56 | I notice that this cost function is because every part every component in this |
|
| 60:03 | function is a differential function. So this car function is defensible, their |
|
| 60:09 | very straightforward to calculus Ingredient so So this is the greedy Inter have |
|
| 60:15 | cost function with respect to well, than primitive state. Um, and |
|
| 60:23 | see houses. Credence is defined it find us in pass one by one |
|
| 60:31 | . Well, because because we can ingredient easily. Therefore we can we |
|
| 60:37 | play catch grading descent or slow Good, good and decent. I |
|
| 60:40 | about mini batch gradient descent to train largest regression model. While that stringing |
|
| 60:52 | that second part of the machine running important part of motion on Islamic |
|
| 60:57 | So once they learn is completed, will have a tenancy learned more the |
|
| 61:04 | fate you want to watch while next when the new data comes in, |
|
| 61:12 | did acts comes in. We can predict, um, on this news |
|
| 61:19 | this new live acts by calculating by this age data backs where these things |
|
| 61:29 | is Seymour the printers with current, have learned from the training face. |
|
| 61:36 | , next, the implementation of logistic using second learned. So to do |
|
| 61:42 | , I'm going to come open Demonstration the jukt a notebook. So |
|
| 61:54 | going thio my azar notebook and walking a very simple example of largest |
|
| 62:13 | So if you go to my No, no account. Um, |
|
| 62:18 | you click this lack of exercise Week on there is already a joke notebook |
|
| 62:24 | largest regression. So in this I just used the example, Data |
|
| 62:42 | , called areas State Said to illustrate this whole how you can implement largest |
|
| 62:49 | using secular. So this arrested said is a very femurs. Public dissent |
|
| 62:56 | motion running this'll arrested said, contains sample and pad Oh, Len thing |
|
| 63:03 | values from 150 iris flowers for different three different species the Tosa versus collar |
|
| 63:14 | on Virgin Eka. So this is picture of these three different Aris |
|
| 63:22 | In this case, without our our task is to train a lot |
|
| 63:27 | regression or a binary classifier to classic into Virgin Eka or non Virgin eka |
|
| 63:36 | based on two features. Petulant and . With, Um, the first |
|
| 63:41 | you want to do is to report pi array that would have you. |
|
| 63:45 | let me restarting Clea Clea R output that so that you can set it |
|
| 63:52 | cleaner and you can see what each of the code dust wait. You |
|
| 64:00 | to impulsive vampire E as number. also want to import this Ari states |
|
| 64:07 | . So here's what you can do impart the absent from second learn imported |
|
| 64:16 | and Aires equals this says Start, , Carrie's So this is how you |
|
| 64:25 | at every state said. So let's ahead and run it. Okay, |
|
| 64:31 | the resistance as we sing our If you want to take a look |
|
| 64:36 | everything, that's that you can simply Aris and run it. So this |
|
| 64:40 | how the distance that looks like it's little bit messy. But if you |
|
| 64:49 | has look at all the information here , you can you can recognize that |
|
| 64:55 | arrested said, is the dictionary. that the dictionaries always is one of |
|
| 65:01 | other amongst python did types, and dictionary always consists off a few a |
|
| 65:07 | of key the repairs. That is I wrote down here in this |
|
| 65:11 | Arrested sent consist of five key battle . And if you want to find |
|
| 65:16 | what keys are included in this, said, you can clicks this cell |
|
| 65:23 | and run it. So we have keys data target talking names on this |
|
| 65:33 | and future names. Description K Just a few sentences describing that they said |
|
| 65:40 | state of Qi that active contents the is array matrix with one drop, |
|
| 65:49 | instance, and one column for In this case, we have four |
|
| 65:54 | . The pad Oh, and several . Wait, so we have four |
|
| 65:58 | . The Target cake contains the wasti labels and future names. Cake |
|
| 66:04 | , and these are the names of on target names packed. It contains |
|
| 66:10 | names of the actor targets, so not Let's take a closer okay, |
|
| 66:19 | that each case corresponding to so you . If you want to find out |
|
| 66:24 | what's the target value is you just Aires on square bracket is tight so |
|
| 66:32 | will give you the value Correspondences, , touch, kid. So in |
|
| 66:39 | case, you notice that is a . The values correspondent to these key |
|
| 66:47 | are simply one Simply zeros ones and . Again, this values just discreet |
|
| 66:56 | values. It simply means class zero one class to what you want to |
|
| 67:02 | what each class. What What targets class expected correspondent to. You came |
|
| 67:12 | on this coat areas, talk It actually tells you that class wine |
|
| 67:18 | to save Tosa class too. Class Zero Correspondence that talks a class |
|
| 67:24 | is mercy collar. And plus two the emergent Nika. And if we |
|
| 67:31 | to find out, see Fisher So this is this is the |
|
| 67:37 | Names in the names of features in garrison said we have four features several |
|
| 67:43 | separate with had tow lines and better . Here is the description of the |
|
| 67:52 | set that you can treat. You to learn more about It was active |
|
| 67:58 | , active training, data input, middle input. Um, data looks |
|
| 68:05 | this. So this is the you consider this matrix that has 150 rose |
|
| 68:12 | four columns because we have 150. better way Take the battlements on 150 |
|
| 68:21 | . And we have four columns because have four features. So next thing |
|
| 68:26 | me to do on the next thing want to do is to pray. |
|
| 68:30 | opinion, Dayton. In this we want to use a paddle lands |
|
| 68:34 | patter ways to make predictions that correspondent this data array actually see, |
|
| 68:43 | third and fourth column of the things so that is what you see |
|
| 68:47 | I just assigned the third and fourth columns from this delivery to this numerical |
|
| 68:57 | ax. And this is our, this is the target. This is |
|
| 69:05 | target of fury. Too sensitive the . So we convert all the |
|
| 69:13 | remember that labels are with the labels it. Average students that are simply |
|
| 69:18 | , ones and twos. We're We have a, um we just |
|
| 69:25 | his, um, So essentially, this this lanco does is to convert |
|
| 69:30 | true and enforce just converts all these values into zeroes and ones that we |
|
| 69:38 | that will serve as our labels the . So if you want to |
|
| 69:44 | Second, learn to trim the largest model again way we need to import |
|
| 69:49 | more do so that so that we use it in our workspace. The |
|
| 69:56 | to do that is to simply right this coat from second learned doctor the |
|
| 70:00 | modern. Because Lena regret largest regression to the category linear more than from |
|
| 70:07 | and dot William or the importance of regression and then feel less Korean. |
|
| 70:17 | this one prepared data import largest regression the training party is very, very |
|
| 70:26 | if you use in second the theory second packages training part. So this |
|
| 70:31 | regression, that is what has just imported from second learn. And don't |
|
| 70:36 | about this practice instead of a few that a user can cast pacifying your |
|
| 70:42 | to really taters. Is this regression due to their spacing problem? But |
|
| 70:48 | , don't worry about it. I this'll am code. I'm justifying my |
|
| 70:57 | regression over them. I want a weapon. I want the largest |
|
| 71:02 | um, algorithm with this two So and I name my largest regression |
|
| 71:11 | them as log on this contract. they seize my, um, largest |
|
| 71:18 | over them Now I'm with that I'm ready to do the training part |
|
| 71:24 | it. Very, very easy on on it. The training parties down |
|
| 71:32 | . Wait. This is the name my largest regression classifier. Start feet |
|
| 71:39 | followed by Z input variable and doubtful . You run it and that's |
|
| 71:46 | That's see, that's That's all you to do in order to train a |
|
| 71:51 | river. Modern without foot here just you what you're more. The parameters |
|
| 71:58 | so many of you don't don't don't to worry about is because the default |
|
| 72:02 | primitive relatives are humanity's is good for purposes If you want to find |
|
| 72:08 | the learns more the premises from within thing is it there? Oh, |
|
| 72:13 | is essentially the intercept. You just the You just write down the name |
|
| 72:22 | these this regression classifier thought intercept on skull Run it ! And so that |
|
| 72:29 | the moral parameter Save the state a learned from largest regression. And |
|
| 72:36 | if you want to find other all other equivalents, for example, it |
|
| 72:39 | to three in this. In this , we only have two features, |
|
| 72:43 | we won't have to. The one two the way to the finals these |
|
| 72:49 | is to using the coat here. think this is the name of my |
|
| 72:56 | Regan classifier Thought co you feed on , Oh, yeah, on the |
|
| 73:03 | . What you found, too. you want a summary statistics for your |
|
| 73:09 | regression, for example, if you to find out the overall accuracy of |
|
| 73:12 | predictions from largest regression, you can call this method called Scott. So |
|
| 73:20 | this case, the prediction accuracy's 92 6% which is not bad, since |
|
| 73:28 | haven't says where were mostly using the default more the printer matavz against. |
|
| 73:37 | that's that's it. That's the premium . And you want to. If |
|
| 73:44 | want to predict, you can call method of social awaits largest regretting, |
|
| 73:48 | predict, um, printed. You use your predict or predict on the |
|
| 73:55 | . Probable. That will give you really, um, really longer value |
|
| 74:02 | this syringe from 0 to 1, this is a new data that you |
|
| 74:07 | to make a prediction on. So part of code to civilization okay, |
|
| 74:21 | you. Yes. So this is data. All the train goes and |
|
| 74:29 | . That is our training data. these death black line, that is |
|
| 74:34 | decision boundary and all these street line street, different colors that it's the |
|
| 74:43 | lines for the predictions. Okay, that's it for implementing, implementing just |
|
| 74:53 | in secular and very easy, very . For the training part, this |
|
| 74:58 | all you need to do. Largest you in the name of your different |
|
| 75:02 | dot feet and or the tribune or mathematics or the optimal Asian part is |
|
| 75:08 | care of by this simple coat. , so that's all for today. |
|
| 75:16 | you for attention on. If you any question, you can send me |
|
| 75:20 | or you can ask questions in the , |
|