| 00:00 | trick clerk. Yeah, yes. today I will continue to talk all |
|
| 00:10 | memory. Uh, just cut to point of talking about main memory last |
|
| 00:16 | , but most of the time talking cash. So today, more about |
|
| 00:23 | main memory behavior. And as you seen through the lecture that despite this |
|
| 00:34 | for the had dynamic or ram random memory, they actually the memory is |
|
| 00:41 | like random access. And that's why can get very different performance, depending |
|
| 00:47 | higher access memory. Because it is , as the name indicates, |
|
| 00:53 | I want you to be aware of and understand why that is, and |
|
| 00:57 | the magnitude off performance impact that may . And then I hope to get |
|
| 01:03 | talk a little bit. Baron Energy and I will stop leaving about 20 |
|
| 01:12 | or so for suggest to do a off profiling and particular power measurement tools |
|
| 01:23 | we have access to. Um, there are other tools that way, |
|
| 01:30 | , do not have access to severe toe pretty much one mhm so now |
|
| 01:42 | dynamic and memory, or ram in phone form or other. So the |
|
| 01:52 | economic Graham and S from static and the second one is Rahm on |
|
| 01:59 | slide on the right hand side. the kind of design that is used |
|
| 02:04 | cash is. Where is the The design is used for your main |
|
| 02:10 | so the objectives of different. So main memory, you want something that |
|
| 02:16 | hold a fair amount of data that cheap. And that's why one s |
|
| 02:23 | to come up with design that is involving one transistor in one capacitor. |
|
| 02:29 | it's a one transistor cell, so quite small, and there's a little |
|
| 02:36 | the bottom left hand corner. There in indication what it is for. |
|
| 02:41 | has recently current that says that just one bit dynamic random access memory doesn't |
|
| 02:51 | more than 0.0 26 micro meter so it's incredibly small. On the |
|
| 02:58 | hand, the extreme cells they typically six transistors instead of one, and |
|
| 03:04 | reason is that it is, retaining the information, whereas the Iran |
|
| 03:12 | leaks information and child talk about them bit. So SDRAM cells are considerably |
|
| 03:19 | , more or less on the About 10 times as large. |
|
| 03:24 | it's also the designed Thio for So we want cash is to operate |
|
| 03:30 | the cooperate off me course on the logic ale. Use comparatives, decoders |
|
| 03:40 | what not so all the operates at same clock rate, whereas the memory |
|
| 03:45 | are considerable, so slower and I talk about those things. But there |
|
| 03:51 | just for general education in terms of the memory technology is has evolved and |
|
| 03:58 | it is today on, and I put in on it just for I |
|
| 04:03 | general education. So today it's in 10 to 50 nanometer range that the |
|
| 04:10 | being used to produce the ram and to human hair, it's about in |
|
| 04:18 | lateral dimension about 2000 times smaller or more depending upon stick your hair you |
|
| 04:24 | . So that means on just a section of human here. Today, |
|
| 04:28 | kind of fit hundreds of thousands, not millions of transistors or bits. |
|
| 04:34 | talked to Iran give some idea off the technologies and here is just another |
|
| 04:41 | like showing more or less the same in terms of the big density on |
|
| 04:46 | right hand side of the scale that you're gaps close to or the quarter |
|
| 04:53 | , a billion bits in the square on today's chip on the other ball |
|
| 04:59 | bars say base officials typical ship areas they are in the order of about |
|
| 05:06 | square millimeters on bond. Well, were talking about processors. If you |
|
| 05:11 | , the processor chips today tends to fairly large in the 6 to 800 |
|
| 05:16 | millimeter range, so these ships are smaller, and the reason for that |
|
| 05:23 | to get ties, yield and low . Yes, for general ads. |
|
| 05:29 | now here's the way how random access is organized. So it's actually |
|
| 05:37 | like the matrix visible and columns and cross section off these rows and |
|
| 05:46 | That's where you have a bit. off some flavor either one transistor dear |
|
| 05:53 | or six transistor static or Esther And then the roles, the typical |
|
| 06:01 | lines and the columns particularly known as lines and the one row then basically |
|
| 06:11 | a block of data. And I'll more about how these things works in |
|
| 06:15 | next several slides. But it's important remember that this is kind of a |
|
| 06:21 | organization. There is just a micro what the chip might look like. |
|
| 06:26 | it can very much see the highly and ordered arrangements off memory bits |
|
| 06:36 | And it was just a little bit text. And since I don't use |
|
| 06:40 | textbook for anyone to read up on micro photograph off and I think a |
|
| 06:45 | Samsung chip that that's a few years by now. So today, 20 |
|
| 06:53 | notes our feature sizes and silicon is used. That state of the |
|
| 06:59 | um, half a little bit bigger half of that size and just for |
|
| 07:06 | . So you have some measures. are for static graham cells, and |
|
| 07:10 | have some chip area for basically wanted on this thing and, as you |
|
| 07:15 | see and it's more than a factor ton larger than your the Iran |
|
| 07:22 | So now a little bit about the of the Rams. Since it has |
|
| 07:27 | matrix organization to get what you want out of it or be able to |
|
| 07:33 | it, you need thio have both always call him address. Now, |
|
| 07:40 | way things are organized, remember these are small and footprints like, you |
|
| 07:47 | , 6 to 7 millimeter squares and can't fit too many pins for data |
|
| 07:56 | clocks and power and all the things want. So for that reason, |
|
| 08:02 | tryto economize on pin studies. External huh pin should be not taking to |
|
| 08:10 | the early days it literally wasp ins . There other ways off getting electric |
|
| 08:18 | between the memory chip and the circuit , but just think of it as |
|
| 08:25 | mechanical piece that carries on signals. since the footprint is small, the |
|
| 08:34 | decided thio use the same quote unquote for both rows and columns addresses, |
|
| 08:41 | that means you can't give them both the same time. So when it |
|
| 08:47 | typically, they gave their grow address . And then you give the column |
|
| 08:53 | , and it turns out that the things are organized in many columns, |
|
| 08:58 | you can then for a given the , provide many different column addresses to |
|
| 09:05 | this. If the columns that you and I'll cover that a bit |
|
| 09:09 | But there is a process necessary to read or write the information, so |
|
| 09:17 | one need Thio as it's known, the particular role. And the reason |
|
| 09:25 | that is that again, power consumption a big concern on, and I'll |
|
| 09:32 | more about that towards the end of this lecture. So things that are |
|
| 09:39 | actively being kind of used are in form of low power states and their |
|
| 09:45 | low power states, and again that cover that also in the future. |
|
| 09:50 | the point is that to actually be to read or write, you first |
|
| 09:53 | to activate some, and that takes . And then you do the operation |
|
| 10:00 | wanted. Either you're either you're and then one has to kind of |
|
| 10:05 | the states, and that's known as charge. And then there's yet another |
|
| 10:10 | . So the first four is kind what needs to happen related to read |
|
| 10:17 | write operation. The refresh is a thing, and that doesn't need to |
|
| 10:24 | too closely associated with reads or But it's something that needs to happen |
|
| 10:30 | , as I mentioned earlier, the are leaky, so they forget the |
|
| 10:35 | on. You don't want that to , so at some intervals, one |
|
| 10:41 | to basically restore the information that it before it has disappeared. And that's |
|
| 10:47 | refresh. There's a little bit more just showing again this dynamic ground picture |
|
| 10:56 | the sets of operation and needs to . That's sort of the police charged |
|
| 11:01 | Thio. Activate a bit line and get used, the word addressed and |
|
| 11:09 | get the word line and then you basically the coordinates off a bit. |
|
| 11:14 | then you, um, this when act to it both of this bit |
|
| 11:20 | word line, then the charge and capacitor gets shared with the bed |
|
| 11:26 | And at the end of the bed , there's what's known as sensors or |
|
| 11:31 | amplifiers that are incredibly sensitive that can miners changes in the kind of voltage |
|
| 11:41 | effectively the transistors, not transistors, electrons that comes off the capacitor when |
|
| 11:50 | decline is activated. So it, said, down to you know, |
|
| 11:57 | to hundreds depending upon the technology, these features are very small s appointed |
|
| 12:06 | before, so the number of electrons the transit on the capacitor is in |
|
| 12:13 | order of tens to hundreds on in final technology. So you're kind of |
|
| 12:19 | almost accounting individual electrons to figure out state capacity ahead. Um, |
|
| 12:30 | So let's see what happened here. coming back? Not a little |
|
| 12:36 | um, how the operation works As mentioned that typical models you give zero |
|
| 12:45 | and once that firmly, kind of through this process of activation and off |
|
| 12:52 | road, then you can issue several access requests for that role without |
|
| 13:02 | You don't have to repeat the role as long as you stay within the |
|
| 13:07 | road. So, however, if want Thio, switch to no |
|
| 13:16 | then you basically need to close up active low and activate, you |
|
| 13:25 | wrote and then you can read it . That means that when you go |
|
| 13:30 | one role to the next role, is a time penalty or delay or |
|
| 13:37 | degradation compared to staying in the same . So all this is just something |
|
| 13:46 | much saying what I already said in off, if you're in an open |
|
| 13:51 | , you just keep adding column addresses long as you access things within the |
|
| 13:57 | column. On the other hand, you need to go to another, |
|
| 14:01 | there is a penalty. So here , um, kind off the, |
|
| 14:11 | , time aspect are the Iran. the Rams do you have a |
|
| 14:19 | time and the cycle Time has thio does account for the faces associated with |
|
| 14:30 | . We're accessing or writing information into deer, so that's why cycle times |
|
| 14:37 | much larger than the access time. there access time is associated with. |
|
| 14:47 | you are in a column on, go from accessing data MBA in one |
|
| 14:52 | to another column in the same That is the first thing that is |
|
| 14:57 | access time, whereas again the cycle has to account for all the |
|
| 15:05 | And it's important to not confuse the Am cycle time, which is an |
|
| 15:14 | concept, and not confuse it with actual clock. Greater is being used |
|
| 15:22 | the memory itself. So the cycle is much longer also than the clock |
|
| 15:32 | and now something I want you to familiar with, because if you ever |
|
| 15:37 | to configure things or understand the performance detail, there are a number off |
|
| 15:48 | aspects of the Iran money's too be with, and they have these |
|
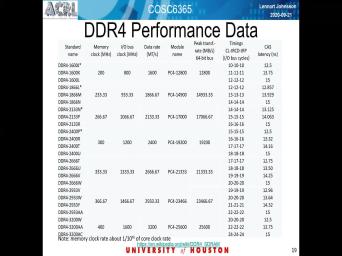
| 15:56 | and it typically quoted, that's a of numbers with hyphens between them and |
|
| 16:05 | the T cast number. As it there, it's the number of memory |
|
| 16:10 | cycles needed to access a certain You know, talk more about these |
|
| 16:18 | on the next three or four so but I want you thio kind |
|
| 16:24 | be familiar with t cast. Our is when you switch from the road |
|
| 16:32 | or need to get a new then also said there is delay after |
|
| 16:35 | get the road address before it Yet there access to columns. Then |
|
| 16:42 | is the priest charged time. And there is also the minimum duration for |
|
| 16:51 | or dealing with the role. Because need to go through these steps before |
|
| 16:57 | , you need to activate it, hopefully we'll read it and then you |
|
| 17:01 | to close it. And so there a minimum time before you can jump |
|
| 17:07 | another road. So here's a little of a diagram trying to put these |
|
| 17:13 | in context. So there are city there's when you start a new role |
|
| 17:22 | before you can actually deal with the there is a certain amount of cycles |
|
| 17:27 | needs to happen. Then for once That's all they're. All is |
|
| 17:34 | Then you can access information in the off the road, and there's a |
|
| 17:40 | cycles and associate ID with each All the column access is you |
|
| 17:47 | and the writer is a little bit . And then there's also showing here |
|
| 17:53 | minimum time to T. Ross for direction off euro access. And if |
|
| 17:59 | all when you're all happy and done the rope, then it's the pre |
|
| 18:05 | to kind of restore on, make ready for another role. So the |
|
| 18:13 | slide is just trying to now give a little bit off kind of state |
|
| 18:20 | the art type memories and understanding what things means and what they are as |
|
| 18:28 | as the characteristic. So I think mentioned that before they they are the |
|
| 18:33 | data rate. That's the current standard been around for many, many years |
|
| 18:38 | , the digit after the the after are the number four and keeps changing |
|
| 18:42 | the futures Azaz Well, not the on the specifications or standard, according |
|
| 18:52 | , the Silicon technology available. So think now this five is actually the |
|
| 18:59 | is agreed on, but most server policing products out there, they still |
|
| 19:05 | within the three or four. Then the dash comes in another number. |
|
| 19:11 | it says here, 1600 on the and 3200 towards the bottom. And |
|
| 19:17 | not going to get into the letter follows after these things or that |
|
| 19:21 | But the number that follows is the off the or data transfer speed, |
|
| 19:33 | should say, and that typically measured transitions for second. And that corresponds |
|
| 19:47 | so cock cycle as you know It goes up and then goes |
|
| 19:51 | So clock cycle has two transitions, oclock, period. So if you |
|
| 19:58 | at the I o bus clock, is on the top. It says |
|
| 20:04 | and the empty seconds is 1600. it's 800 megahertz memory bisque lock |
|
| 20:13 | It's elected, whereas then in each period you communicate two bits. Either |
|
| 20:24 | read or you're right, but you one bit when oclock races and you |
|
| 20:28 | one bit when it falls. So why the data rate is twice the |
|
| 20:34 | grade off the memory bus. But there is another memory clock. |
|
| 20:42 | That is important. So that is internal clock off the memories chip. |
|
| 20:49 | sucks. It's not the external thing the bus. And as you can |
|
| 20:55 | , the internal clock is considerably lower the memory bus or are your bus |
|
| 21:01 | . In fact, it's a factor four in this particular standard. So |
|
| 21:09 | clock and if you could think of memory clock compared to the CPU clocked |
|
| 21:15 | we talked about that tends to be the 2 to 4 gigahertz range, |
|
| 21:21 | the memory chip clock is about 10 slower, then what the CPU or |
|
| 21:32 | unit cocks are. And, then there is a columns, that |
|
| 21:41 | name, and that is what you were fined. For a team that |
|
| 21:48 | when you have a this memory you're sticking to the circuit board for |
|
| 21:52 | server or your PC, and that then maps into the width of the |
|
| 21:59 | bus that temperate trees today 64 So that's why that number comes from |
|
| 22:07 | we moved or the writer says and that's where these, um, |
|
| 22:14 | teas, the columns Leighton See and RCD and the AARP shows up here |
|
| 22:22 | just three of the four numbers in case. So that actually tells how |
|
| 22:29 | , external or memory or the IOS memory bus cycles is associate ID with |
|
| 22:39 | column access. That's the first number to look at the top. It |
|
| 22:43 | 10 memory bust cycles is what it to get one column entry out on |
|
| 22:50 | . Similar is to delay or 10 . After you initiated or start a |
|
| 22:57 | row, I access until you can the column access. So the most |
|
| 23:04 | part, perhaps in terms of is definitely the right hand column. |
|
| 23:10 | if you look from top to bottom the uh, memory clock column, |
|
| 23:17 | , um, improves. Depending upon speed rated memory you get by a |
|
| 23:22 | of two from 200 to 400. , on the other hand, when |
|
| 23:28 | look at the number off the day in the second, so last column |
|
| 23:34 | the right, you see, the the internal clock is, the higher |
|
| 23:39 | number of clock ticks it takes to the stuff out So the net effect |
|
| 23:43 | that in terms of physical time, of the speed of your memory, |
|
| 23:51 | Leighton see is pretty much to and that has not changed over a |
|
| 23:57 | long time as a show on the slide. So if you look at |
|
| 24:03 | bottom left diagram, you can see the Leighton See has pretty much been |
|
| 24:12 | the same level of about 59 seconds many generations. In fact, it's |
|
| 24:18 | the time access. I'm sorry about , but it related to time in |
|
| 24:24 | time, not processing times. So I come to that why This is |
|
| 24:31 | memories in terms of actual physical agency gotten any faster in terms of the |
|
| 24:40 | delivered to the memory bus. It gotten faster, and that is |
|
| 24:45 | too hard. In fact, you list inside your memory chips. So |
|
| 24:55 | the basic building blocks off the DDR hasn't gotten much faster over time. |
|
| 25:04 | when increase the bandwidth by having parallelism the memory, So this is what |
|
| 25:13 | cover next. Any questions so I should think, huh? Nothing |
|
| 25:23 | the chat. Okay, and if , I'll talk a little bit. |
|
| 25:28 | sit. There is part of this the memory, so this is can |
|
| 25:35 | it's very busiest line in a bit a shock. A. You think |
|
| 25:38 | memories being pretty simple? There was simple matrix I showed you in the |
|
| 25:42 | of how things have put together a in columns. But in order to |
|
| 25:48 | to keep up improvements and processors, the clock rate for them has also |
|
| 25:57 | of stabilized around and arrange to 2 4 gigahertz. And there's reasons for |
|
| 26:02 | that I will also come to. then, when has got many |
|
| 26:07 | So the capability to process data on processor piece of silicon as increased tremendously |
|
| 26:17 | the years. So to try to memory to keep up it has gotten |
|
| 26:23 | lot off structure. So I'm using video or three just kind off one |
|
| 26:31 | generation old, because new ones are more complex than this one. So |
|
| 26:38 | the principle is the same. So you try to buy a piece of |
|
| 26:44 | , it has a number of things and it reads so on top |
|
| 26:49 | says one gigabit. So that means memory die has one billion bits of |
|
| 26:55 | on it, and then it has particular organization. And I think I |
|
| 27:01 | a little bit about that when I about them so that they were times |
|
| 27:05 | times 83 times 16 as the number bits that it comes out in a |
|
| 27:13 | cycle off the memory died. So this is tells you how this one |
|
| 27:23 | disorganized it's this organizes 1 28 megabits a right. So so, |
|
| 27:32 | Now the the they are standard three specified that every chip, regardless with |
|
| 27:43 | vendor is needs to have eight and that's again for part of the |
|
| 27:48 | is that is necessary to keep Then we had the times eight that |
|
| 27:53 | will find here. That's the width the data past that comes out off |
|
| 27:58 | stack off memory erase and then get to the pins or external connections off |
|
| 28:07 | particular, um, the around Then this. This In this |
|
| 28:15 | it's, um, as I said 28 columns and that's you can find |
|
| 28:22 | this, uh, bank things that it has basically 16 K rose in |
|
| 28:29 | columns and then the third dimension in case is 64 bits in each one |
|
| 28:35 | these memory. That and you'll see it's 4 64 bits. It's related |
|
| 28:43 | what's known as the first rate that here. So it's also specified in |
|
| 28:53 | DDR three standard that they should have burst mode off eight. So that |
|
| 29:01 | out of the memory array that operates at, uh, a quarter off |
|
| 29:10 | external memory bust cycle. So that's of factor for you need. But |
|
| 29:16 | , on the external memory bus, do to transitions per clock, which |
|
| 29:22 | don't do internally. So that means got another factor of two. So |
|
| 29:27 | you access the memory banks in each of those clock cycles, you need |
|
| 29:35 | get 64 bits in order for the eight bit, while oh, to |
|
| 29:41 | up with the 8 ft by wide eight bits. Yeah, white, |
|
| 29:46 | , data path. Since that does eight times eight transfers within the same |
|
| 29:55 | as the bank is operating in one cycle, you can also see how |
|
| 30:00 | rolling column addresses are figured in this . So there was 1 28 columns |
|
| 30:07 | the bank, So that means there's business to take the column. And |
|
| 30:12 | there is 14 bits to address the . So this is kind of the |
|
| 30:20 | things are. And then there is bank control logic that decided in which |
|
| 30:28 | they actually lives. So I didn't , but I showed them. If |
|
| 30:35 | look at the slides from last lecture I think it's in the slide deck |
|
| 30:39 | today to, even though I don't it, that the memory controller needs |
|
| 30:46 | provide the rank it needs to provide bank he needs to provide the role |
|
| 30:51 | the column addresses to each other on is now. The dominating shouldn't say |
|
| 31:00 | . But the more state of the , because DDR three is cheaper and |
|
| 31:05 | so many times. If that's good , um, that's being used. |
|
| 31:10 | four is organized not as one set eight banks, but it has two |
|
| 31:18 | four sets, uh, four banks . And it's the thing is, |
|
| 31:24 | you stay within their banks, it's of soul, but you can switch |
|
| 31:30 | banks relatively fast, and there is little bit again. How the addressing |
|
| 31:37 | in this case that now you As I said, there were groups |
|
| 31:46 | four groups before banks, each so to bitch for the group that us |
|
| 31:50 | two bits for the bank news. , it's pretty similar to the |
|
| 31:55 | Are three a little bit off the issues with that? And that |
|
| 32:04 | if the bank and a role I say it's also kind of refer to |
|
| 32:11 | a page. So I specific. you stay within the page, you |
|
| 32:16 | access things at very good, On the other hand, when you |
|
| 32:22 | to go to another roll, things slow. So that's what happens is |
|
| 32:31 | going between banks is fast, like on the DDR four. So in |
|
| 32:38 | case, if you do bank switching rose switching and you get much lower |
|
| 32:44 | , so this is what it's the . So if you had, like |
|
| 32:50 | this stream benchmark, it has tried . The compile asl e things up |
|
| 32:56 | the knowledge of how memory accesses, , access penalties are so they lay |
|
| 33:05 | out so you can stay within rose successive address addresses or access is so |
|
| 33:11 | what, in this case for this DDR three memory that's the peak most |
|
| 33:16 | 66 gigabytes per second. Thank Once the DVR 10 33 memories should |
|
| 33:23 | put up on the slide. Where if you go to the same |
|
| 33:31 | And they know row addresses for every than yeah? Don't get the benefit |
|
| 33:41 | kind of bank into leaving, so gets reduced by a factor of |
|
| 33:47 | Because of the eight banks in the , there are three memories, so |
|
| 33:53 | a big difference in performance. And when you did your guts. You're |
|
| 33:59 | likely to stay within the same roll bank on switch between different roles in |
|
| 34:07 | banks. And that's why you get worse performance in the cups as part |
|
| 34:11 | it. The other parties caches and is a little bit exercise off taking |
|
| 34:18 | modern DDR four with the 2.667 make a transfers, uh, per |
|
| 34:29 | notions. So here's the way it on and take a duel Salt conserve |
|
| 34:36 | , and it has eight memory Per Sokka. So this is kind |
|
| 34:42 | in a and e type scenario And then there's 64 bits wide memory |
|
| 34:52 | , and then you converted the bits the volume by eight. And then |
|
| 34:56 | have the transition rates in terms of memory bus. And that means that |
|
| 35:02 | peak memory bandwidth for this particular configuration will stop the Server eight memory, |
|
| 35:09 | per socket and that 2667 um, a transfer right now. So here's |
|
| 35:20 | I guess what I just said, different parts of it. So now |
|
| 35:25 | you so happen, the successive addresses to access is not on alternating |
|
| 35:33 | but on the same subject than you half of the memory bandwidth. |
|
| 35:40 | if it's someone channel, you need factor of lose another factor of eight |
|
| 35:44 | it's only on one memory channel. if it is in the same |
|
| 35:50 | you lose another factor of eight trusting in present. So they're too |
|
| 35:57 | Cases different by more than two orders magnitude. So data, how data |
|
| 36:06 | laid out in memory and how you data relative to are things are in |
|
| 36:14 | is incredibly important. And though programming do not have explicit commands for how |
|
| 36:21 | lay out data. Ah, Sometimes people actually do tweak it by |
|
| 36:31 | their race. Um, because, know, ah, what they want |
|
| 36:37 | of their A. And they know memory architectures, otherwise, function still |
|
| 36:44 | the access order. The compiler is to figure it out, but it |
|
| 36:49 | not figure it out. So later , when I talked about compiler and |
|
| 36:55 | more on the software, I'll sort highlight things one can do to help |
|
| 37:01 | compiler figured out to do so. promised I'll say a little bit about |
|
| 37:12 | I guess I should stop. Maybe a second year. Uh huh. |
|
| 37:18 | if there are questions. Oh, . So no. So since memories |
|
| 37:32 | a problem, why two people not anything about this gap showed some slides |
|
| 37:43 | in this cartoon before and they saw . When I talked about the memory |
|
| 37:49 | right at the clock grades for the chip itself is in the order 2 |
|
| 37:55 | 400 megahertz. Not in the order you gigahertz. So why not design |
|
| 38:01 | all you get comparable clock rates? , it has to deal with both |
|
| 38:09 | desire to keep things dense and cheap the sea most technology and here is |
|
| 38:18 | the reason for it. So the technology is essentially the charge. Transfer |
|
| 38:30 | basically move buckets of electrons around, either you store them that bucket or |
|
| 38:37 | used thio turn transistors on and So hopefully you remember something. I'm |
|
| 38:47 | everybody has had the basic physics. course about that no lost arm |
|
| 38:53 | Kercher slows and etcetera. So wires resistance. And those that come pastor |
|
| 39:03 | used for story information, so they on memory. The transistors are in |
|
| 39:10 | , actually, that's the same So there gets turned on and |
|
| 39:14 | depending upon the charge on the plates the capacitor. So you have a |
|
| 39:21 | simple R C circuit. And so time Thio charge and discharge this capacitor |
|
| 39:36 | on the product of their assistance and capacity and solve these two things. |
|
| 39:41 | you get basically first order differential equation can solve, and it basically got |
|
| 39:48 | exponential, uh, decay so or and then ramp up off the charge |
|
| 39:55 | the capacitor. Now the resistance is proportion to the length that should be |
|
| 40:07 | intuitive as well as the cross section the, uh, resistance on the |
|
| 40:14 | . The fact that the wire is resistance. It has for more capability |
|
| 40:19 | has to move electrons comparative thin So the resistance is basically the length |
|
| 40:28 | by a cross section, the with the height of the thickness of the |
|
| 40:36 | . Right on the comm passions is to the area on the plate, |
|
| 40:43 | there, capacitor and inversely proportional to distance between the two plates of the |
|
| 40:51 | . That's the age to now as scale technology talked about things being, |
|
| 41:01 | know, to the state of the today, seven nanometers. And it |
|
| 41:05 | to be 10 14 20 etcetera. the thing that gets you more transistors |
|
| 41:11 | a diet is because that ability to transistors and wires with increasingly small dimension |
|
| 41:20 | improved. And that's dependent on a factor that put the S in this |
|
| 41:24 | here. So if you assume that reduce all dimensions except the chip size |
|
| 41:32 | in this case is forsake comparison, everybody likes soul. Basically, you |
|
| 41:39 | to get the information out of the so somehow it needs to cross the |
|
| 41:44 | . So that's why I kept L in this case. But otherwise the |
|
| 41:50 | the area off the capacitor and the and the thickness of wires and the |
|
| 41:56 | distance with same scaling factors everything ships the chip. And if you plug |
|
| 42:02 | in in this formula is what you discover. It's that the time constantly |
|
| 42:09 | that tells you how quickly you can things is actually increasing. Or if |
|
| 42:15 | make things half size, in they are see constant doubles. So |
|
| 42:24 | why I just even keeping the clock , the same as you scale feature |
|
| 42:31 | down. It's a momentous challenge because simple basic laws of physics, unless |
|
| 42:39 | change the physics, which they do terms of how the material is being |
|
| 42:45 | , would cause things to get not faster. So this is the |
|
| 42:50 | reasons why both processor clock rates has kept growing that they used to do |
|
| 43:01 | the early days of Moore's law, they have stabilized over the last |
|
| 43:06 | Plus, and same thing that the creates internal to the memory is |
|
| 43:14 | um, increased. So that's the reason why things are the way they |
|
| 43:22 | , and you should not expect things get fixed any time soon. |
|
| 43:30 | two more comments and then I will talking about memory. Uh, so |
|
| 43:37 | off I mentioned earlier or last lecture terms off memory integration that yeah, |
|
| 43:46 | for servers is that you have this models. You stick in the socket |
|
| 43:51 | the circuit board, and then you to push signals across the circuit board |
|
| 43:57 | the sockets that are relatively power hungry make things slow. So now that |
|
| 44:05 | can get a lot of transistors and and also started to, not only |
|
| 44:12 | it's Trump's for cash, but also this forgettable memory d ram on the |
|
| 44:20 | of time. So recent generation of power and some also of Intel's processor |
|
| 44:29 | has the same sort of single cell your arm technology or design on the |
|
| 44:38 | of, and you can then also people do. But I'm not going |
|
| 44:44 | cover that in this course. They to move processing into the memory to |
|
| 44:50 | things close and get performance up. then there is also something new as |
|
| 44:57 | say, actually in terms of silicon , the first new thing that happened |
|
| 45:02 | 25 years, and they came into about two years ago in that is |
|
| 45:08 | as three d X Point. I not go into capped about that. |
|
| 45:13 | I just want you to be aware it. And the next slide is |
|
| 45:18 | of a nice summary. Where is horizontal axis you have the Leighton see |
|
| 45:28 | with different forms of Mary Mary? , technology and design. So for |
|
| 45:37 | else in L three's, you used same design. What you use different |
|
| 45:40 | principles because off cost performance tradeoffs and a logarithmic scale on the horizontal axis |
|
| 45:51 | time on, then they vertical access you sort of the relative notion off |
|
| 46:04 | slow things are. Um, now guess the next few slides since simply |
|
| 46:14 | that I will do quickly that them the most common thing for servers, |
|
| 46:19 | you have these thoughts on the circuit that I talked about several different |
|
| 46:23 | We have the ranks that is the of memory ships that matches the memory |
|
| 46:30 | , and you can have several ranks the same game to put. They |
|
| 46:33 | Thio four ranks, Um, and also the things that memory channels for |
|
| 46:42 | reasons mostly tends to be limited Max eight ranks the bank, regardless |
|
| 46:49 | how they distributed among dims. Then was this other fascinating integration for integration |
|
| 46:58 | that it's not being used for DP and high end GP use, I |
|
| 47:03 | say, and has also been used some high in service where you get |
|
| 47:09 | stack memory integrated in the same Look at the ESPN type memory, |
|
| 47:18 | them with memory, and then I mentioned in the normal technology. Then |
|
| 47:23 | went through a little bit. The issues on this side also gives you |
|
| 47:29 | the bottom, um, energy aspects didn't talk about too much in terms |
|
| 47:36 | me, the processors a little bit telling you how much part of the |
|
| 47:41 | and the processor lecture. And here's little bit in terms off the energy |
|
| 47:49 | for memories, all various flavors. part of the reason for its B |
|
| 47:55 | memory is not on Lee. The aspect that it's, um, can |
|
| 48:01 | wider and better integrated and give. , I am access bandwidth, but |
|
| 48:07 | also significantly lower power in terms off as you perfect and against the bottom |
|
| 48:18 | , take hold. Memory at the highest level is that Iran is not |
|
| 48:24 | access by enemies. And to get good performance, one needs to be |
|
| 48:30 | of that. And we're talking about bit. Bob can do at the |
|
| 48:36 | code level to help compilers. perhaps, hopefully the right thing in |
|
| 48:42 | of active order access is, the layout they have a fixed truth |
|
| 48:48 | . So that's not something they Eso this concert is the fat |
|
| 48:58 | This is what I said. So I was going to switch the power |
|
| 49:02 | energy. But I'll take questions and then I'll make a couple of remarks |
|
| 49:11 | then I let suggest to the Then I will continue here Next |
|
| 49:16 | If there's no time left after So any questions? Mhm s. |
|
| 49:33 | I just, um, again, of us have talked about. It |
|
| 49:37 | just to create an awareness off the and the high variability in performance off |
|
| 49:45 | memory architectures, both respectful caches and and how cashew associative ity matters and |
|
| 49:56 | the cash replacement policies matters and how uh right policies matters that in chemical |
|
| 50:03 | huge difference. And even the physical memory that one typically thrown don't pay |
|
| 50:11 | to its structure, its structure and organization across memory channels, etcetera as |
|
| 50:19 | huge impact. So that's why there's lot of emphasis are in compilers and |
|
| 50:31 | , colder and how you're right. code to try to get good usage |
|
| 50:38 | memory, no questions. And why you take over then and do the |
|
| 50:45 | before I dive into power? But should, I guess, or you |
|
| 50:51 | talk a little bit about Rapolas an in before you talked it what it |
|
| 50:55 | . Maybe that's the easiest. sure I can do that. So |
|
| 51:02 | honest. So this time before I switch screen. So that's why far |
|
| 51:08 | important time. This rapid is a to at the chip level to you |
|
| 51:14 | insight into power consumption. But for let so, yes, takeover. |
|
| 51:24 | is my screen visible? Yes. , great. Thank you. Uh |
|
| 51:34 | . Right. Eso this tool that Johnson just mentioned it's called Rappel. |
|
| 51:39 | stands for running average power limit. , little bit background on it so |
|
| 51:45 | was not originally developed. Doesn't means measure the power, but it was |
|
| 51:52 | designed thio run it on the processors said their power consumption limits in different |
|
| 52:00 | , which I believe professor will talk detail later on. But it was |
|
| 52:04 | a tool to limit the power consumption processors by reading registers that hold energy |
|
| 52:12 | and power consumption values off the But we can tweak it a little |
|
| 52:18 | . And people did. We get , use it for power consumption |
|
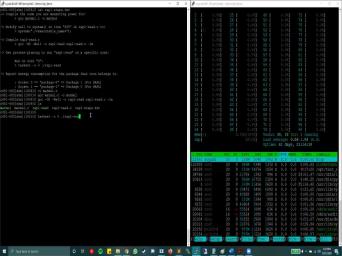
| 52:25 | Uh, so the way you can it is by using this code, |
|
| 52:33 | is freely available on the Internet, , which is called the rapid reed |
|
| 52:38 | C. I think this code it goes in the processor and the file |
|
| 52:49 | mainly and reads those specific registers that the value for power consumption almost |
|
| 52:57 | and it's written in a generic way it can work with different processor |
|
| 53:02 | So we'll utilize this apple green dot to measure power consumption for some sample |
|
| 53:10 | . Now on the left, just have our console on stampede to |
|
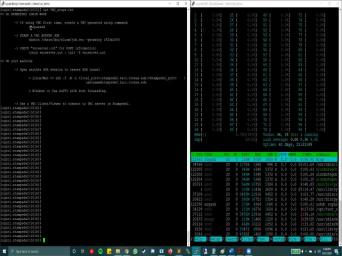
| 53:15 | on a computer Note eso the steps you need to follow Our are as |
|
| 53:21 | So when you need to use rappelled dot c, you don't need to |
|
| 53:26 | changes to your coat. So here just have a simple madam all dot |
|
| 53:32 | program that we eso for our second and as off noise again, I |
|
| 53:40 | just a classic manimal that will be So the first step that you need |
|
| 53:47 | do here is just go ahead and compile your cord as you would do |
|
| 53:53 | other intel compiler or GCC Uh, once you've done that, the next |
|
| 54:00 | that you need to do is you to come to this rapidly dot C |
|
| 54:06 | and around line number 800 or And so you will see a sleep |
|
| 54:14 | If, uh, here something like for 15 minutes, second or |
|
| 54:22 | something similar. But we you need just comment that out. I'll just |
|
| 54:26 | it for now and replace it with Call. The court that you will |
|
| 54:31 | provided will likely have all these Are these calls already in? So |
|
| 54:37 | you need to do is just provide executable name off your program in this |
|
| 54:44 | called. And that's all you need do in this rapidly dot C |
|
| 54:49 | So you compile your code you provided executed building inside the system called. |
|
| 54:59 | thing that you need to do is need to compile this rappel read program |
|
| 55:05 | you can use this. Uh, on here, toe. Compile it |
|
| 55:12 | you will see you. Have you an executable called apple? Read. |
|
| 55:16 | , the way this works is what will compile. Raffle Reid Zazi program |
|
| 55:23 | Tazi program, uh, will run programs that execute table in turn. |
|
| 55:30 | if you see on the top and bottom off this system, call here |
|
| 55:36 | the apple re dot C program. measures the power consumption for this section |
|
| 55:41 | the code. So this the section the top, it starts the power |
|
| 55:45 | and the bottom stops the power So happily dot c Don't your parents |
|
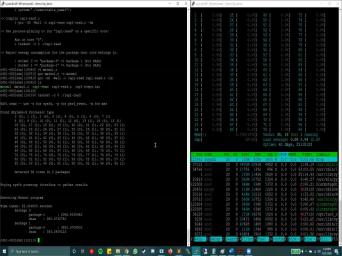
| 55:50 | program on your behalf now visualize how are working, Uh, and to |
|
| 55:59 | sure that the program runs on the or socket, which he wanted to |
|
| 56:03 | on. We will use a package Edge Top and you can load it |
|
| 56:10 | module. Load it. Stop command stamping too. Um, yeah. |
|
| 56:18 | then just go ahead and run the edge top. Now, this command |
|
| 56:24 | very helpful That so remember, you 96 threads because there's hyper threading on |
|
| 56:35 | compute nodes. You have two each with 48 threads on. So |
|
| 56:41 | sockets with 96 threads So you can the usage off each of these, |
|
| 56:48 | , hyper threads using this edge top . Now, since we're still using |
|
| 56:55 | threaded program, we would want our to run on a single thread. |
|
| 57:01 | for that, we can use the , uh, dusk set and give |
|
| 57:10 | parameters finest C zero. So what means here is we want our program |
|
| 57:17 | run on core zero. Um, I d zero. And we'll see |
|
| 57:22 | that looks when the gold runs and go ahead and provide the executable |
|
| 57:30 | Now why we are using Tusk said does said what it does. It |
|
| 57:34 | . It pins your program to the court that you mentioned here. So |
|
| 57:38 | is called process spinning, and the why we need to do that is |
|
| 57:45 | rappelled read it only reports the power for at the socket level, it |
|
| 57:52 | not provide power consumption at corps level even much final level. The best |
|
| 57:58 | can do is at socket level, travel read. So that's why we |
|
| 58:03 | to make sure that our program runs the course that we wanted to and |
|
| 58:07 | we can distinguish between the outputs, , measure to get the correct our |
|
| 58:14 | readings. So what I'll do here I'll just go ahead and run this |
|
| 58:19 | . And as you see, since ran our program on court number |
|
| 58:24 | it's, um, utilization just went . Now, while this program is |
|
| 58:31 | notice here that this is the organization rappelled read, I found about the |
|
| 58:37 | and the processes that are president on particular note. Now the notation here |
|
| 58:43 | the number outside the bracket. It's core number and number. Inside these |
|
| 58:50 | is the socket number. So we two sockets, so we have socket |
|
| 58:54 | socket, 10 and one and so . So as you can see, |
|
| 58:59 | operating system has, uh, generate a mapping off physical course toe these |
|
| 59:06 | or logical course in an inter lived . Court number zero goes to socket |
|
| 59:11 | . Court number one goes to socket . And so on. Now, |
|
| 59:19 | . So the execution just finished. now what? How do we read |
|
| 59:24 | output that was generated by Apple? remember, we bend our program to |
|
| 59:30 | zero, which was part off socket zero, but this thing is a |
|
| 59:37 | bit confusing, so let's see So the package hyphen zero was the |
|
| 59:45 | in which those files are where power readings are written for socket zero and |
|
| 59:54 | hyphen. One is the directory um where the power consumption readings was |
|
| 60:00 | for socket one. However, the . When it went inside the directory |
|
| 60:05 | read those files, it found package one first. And that's why it's |
|
| 60:11 | . That one is back in and it named on the sock and |
|
| 60:17 | directory as package one. So we that our core zero belongs toe socket |
|
| 60:23 | . So we'll take these readings as you can see, because our |
|
| 60:29 | ran on socket zero. This is energy consumption for just the processor part |
|
| 60:38 | the mother board. So only the the chip, Uh, that contains |
|
| 60:44 | the 24 course. So this is consumption off all the 24 course, |
|
| 60:48 | since we used just one will take as three energy consumption for just 11 |
|
| 60:55 | . The reason you see, dear um, energy consumption lower than |
|
| 61:02 | one that the socket that we did use is because the matrix matrix size |
|
| 61:08 | really small. Leonard, if I it again, you'll see here in |
|
| 61:11 | edge top output, that memory You pretty much remained close to |
|
| 61:16 | So most of the transaction were uh, from caches. But if |
|
| 61:21 | run a large enough problem which will quite a lot of time to |
|
| 61:26 | you will see a much larger difference the diagram consumption off the socket that |
|
| 61:32 | ran on and the socket that was idle for this whole time. |
|
| 61:40 | yeah, that's mostly that's my most travel. So does anyone have any |
|
| 61:47 | about it? Just a quick somebody , goes and reads these files that |
|
| 61:58 | the energy consumption, and it runs program and reports the energy consumption towards |
|
| 62:04 | end. Yeah, and it's in next assignment. You will use |
|
| 62:14 | So that's right part of what I . So you have to cover |
|
| 62:19 | So you have questions. Please ask this point, so rappel can and |
|
| 62:24 | talking about measure a couple of things measures then started ship power on it |
|
| 62:33 | also measure the memory power the Iran separately. And so that's why when |
|
| 62:42 | do a rappel diamond first you should sure that again used to compute |
|
| 62:46 | and she used it exclusively. And you should, um, then make |
|
| 62:54 | that you've been in a particular Yeah, painting to core is the |
|
| 63:01 | important part because we're using single thread rappel only reports that socket level, |
|
| 63:06 | you can see here. So we two sockets and it's a border for |
|
| 63:10 | sockets on. For now, the said command would do for us because |
|
| 63:20 | just need to paint it toe just zero, since we're just dealing with |
|
| 63:24 | threat. But when we moved to , MP and multi threaded programs will |
|
| 63:29 | a different command that's called Numa That gives you much more granularity on |
|
| 63:35 | you can put the threads for your on which physical seaview on which logical |
|
| 63:41 | views. And it also provides the to on what socket you want. |
|
| 63:47 | . Allocate the memory, but that's the later part. But here you |
|
| 63:51 | can only use tasks. Tasks set you scored. Zero. Okay, |
|
| 64:03 | if there's not any questions, I'll to the second part of the |
|
| 64:08 | which involves using of batter broth, is the G y based profiler. |
|
| 64:22 | in assignment to all of you uh, the people Off, which |
|
| 64:29 | a command line based, uh, is the command line based profiler now |
|
| 64:42 | Assignment three, we will provide you a couple of codes that you just |
|
| 64:48 | to compile, and then you would thio. Choose the events from |
|
| 64:54 | Whichever events you like, you feel would provide you insights into what those |
|
| 65:01 | are doing. So based on your from assignment to you, will choose |
|
| 65:05 | poppy events and profile those codes and us if you think it's a compute |
|
| 65:11 | problem or if it's a memory bound . So in that case, you |
|
| 65:15 | generate profiles using, uh, how , just like for the assignment |
|
| 65:20 | But you will use the G Y profiler, which is the paragraph eso |
|
| 65:29 | to or like They need to go a log in note to do |
|
| 65:39 | Yeah, so you can, simply run para prov instead off by |
|
| 65:47 | if you have X 11 forwarding with ssh connection. But with my experimentation |
|
| 65:54 | year as well in this year as , the X 11 forwarding on stampede |
|
| 65:59 | is really slow, and the rendering barrel prov takes a really long |
|
| 66:04 | Eso to deal with that. You use V and C to connect to |
|
| 66:10 | to the stampede to cluster in a forwarding mode. And then you can |
|
| 66:16 | fire proof, and it's much faster compared to X 11 forwarding. So |
|
| 66:21 | are a few steps that you need perform. First step is to set |
|
| 66:26 | DNC password on stampede, too, make sure for these steps you need |
|
| 66:31 | be on the logging notes, since nodes do not have are not connected |
|
| 66:35 | external Internet eso. The first step will do is just that you're BNC |
|
| 66:42 | , which, according to stamp itu's guide, you should be different than |
|
| 66:47 | log in password. Just go ahead set any other password. It asked |
|
| 66:55 | view only password. Just set it the same as above. Really |
|
| 67:01 | Uh, so once you've said this stampede to already has this, |
|
| 67:08 | batch file defined in their shared So what do you need to do |
|
| 67:14 | just go ahead and run this, , submit this batch file using as |
|
| 67:19 | command. You can also provide, , the resolution in which you want |
|
| 67:24 | DNC session to run later on by the hyphen geometry flag. Uh, |
|
| 67:32 | yeah, so just use that submit this job on the patch off |
|
| 67:42 | , and it's output would come out a file called the N C server |
|
| 67:46 | out eso just to read that you use this command, touch me and |
|
| 67:51 | server dot out till and so And when you read that file, |
|
| 67:56 | will see that we got a logging and a BNC port as 5901 and |
|
| 68:03 | on and all this information. So this message that you're BNC server is |
|
| 68:09 | running on the stampede to cluster. step you need to do if you |
|
| 68:15 | using Lennox or a Mac based, , laptop, then you can just |
|
| 68:21 | ahead and use this command. Ssh Toe this, uh oh. This |
|
| 68:27 | . Give the local port and stamp to port that you just got, |
|
| 68:30 | it's very likely the same. 12155.2155 , so this is to create a |
|
| 68:38 | from your laptop toe the sweet and several that we just started. So |
|
| 68:43 | for Lennox and Mac for Windows. you're using Pootie, you can just |
|
| 68:48 | putting with port forwarding to create a . So to do that, just |
|
| 68:54 | another party session. Uh, goto and Donald's, uh, check these |
|
| 69:05 | in the forest option here. Use source sport that you see here for |
|
| 69:11 | logging note. DNC. So that's at it here and for destination. |
|
| 69:17 | want the same port on your local as well. So 12155 as local |
|
| 69:24 | go ahead and add it. So , during this whole, uh, |
|
| 69:32 | , you need to keep your old open. You don't You should not |
|
| 69:36 | it. And with those settings, go ahead and log in to stamp |
|
| 69:42 | to again. And as soon as log in, our tunnel will be |
|
| 69:51 | . So that's that's all you need do here. Don't close the console |
|
| 69:55 | well. Once you're done, just can use any VI nce view our |
|
| 70:02 | for me I downloaded this weekend. viewer client Uh huh. To connect |
|
| 70:10 | your BNC server that's running on stampede . So just go ahead and make |
|
| 70:14 | new connection again. Provide the same address. So 12155 You might get |
|
| 70:23 | different board address, uh, when try to do it and for different |
|
| 70:28 | session. So don't worry if it out a little bit different to just |
|
| 70:34 | a new session on BNC viewer and click on it should have worked, |
|
| 70:44 | think on the local host you did instead of 12155 Why is that |
|
| 70:49 | Yeah, my bad with me. it again quickly. So 12155 |
|
| 71:09 | let's try it again. Okay, the tunnel is open. Let's try |
|
| 71:27 | again. Create a new connection. Let's see. Yeah, so it's |
|
| 71:42 | a encrypted connection, So just go and continue. Now it will ask |
|
| 71:46 | the password to put the password that entered using the V and C password |
|
| 71:51 | E was good and do that. what that's going to do is it's |
|
| 71:56 | to open a BNC session. so let me go to a directory |
|
| 72:02 | there is a profile for a So this is from our previous |
|
| 72:08 | where I showed you use use off . Let's just go into any one |
|
| 72:13 | these directories where we have a profile that was generated using town. And |
|
| 72:18 | , instead of doing people off, can just do para prov. We |
|
| 72:25 | to do model low down. Then will work because paragraph comes as a |
|
| 72:32 | off now, and as soon as do it, it's going to take |
|
| 72:36 | second, and it's still a little when you use it. It might |
|
| 72:42 | a while to render things but it's better than X 11 forwarding. So |
|
| 72:49 | you can see this is the profile single precision operations for our matrix multiplication |
|
| 72:56 | that we generated earlier. Uh, , I m c s. That |
|
| 73:02 | is a little bit buggy s so can ignore that from now s. |
|
| 73:07 | , this is just simply if you click on node zero here, it |
|
| 73:10 | open another window that will show you detailed metrics for your program. So |
|
| 73:17 | is again similar to what you guys have seen as an output for single |
|
| 73:21 | offs. So here you see the precision office for classic Matt Malfunction and |
|
| 73:29 | other functions as well. If you to go ahead and try, |
|
| 73:34 | more functions off paragraph, you can three D visual visualization as well for |
|
| 73:40 | for this metric, just from windows three D visualization. Open that on |
|
| 73:47 | will. You can visualize thes profiles three D as well. It may |
|
| 73:52 | look very well over the Internet. be a little buddy, but here's |
|
| 74:01 | function. As you can see, classic Matt model would be here, |
|
| 74:06 | the single precision knobs here. So , clicking with right click. You |
|
| 74:11 | move this whole graf with left You can oriented as whichever way you |
|
| 74:18 | it, so you can play with . Uh, there's lots of other |
|
| 74:26 | , and this you can feel free play with it. Uh, |
|
| 74:33 | on when you will use, let's say open and be or any |
|
| 74:40 | threaded program that then you will likely lots and lots off Mawr bars. |
|
| 74:47 | , for things is just a single program. So you see no. |
|
| 74:51 | only. Let's say, if you eight threads in your program, you |
|
| 74:54 | see no zero to note seven and on. So it's a It's a |
|
| 75:00 | rich tool. It's just a little by using it through stampede to but |
|
| 75:05 | free to play with it. It's more intuitive than the people off the |
|
| 75:10 | line profiler on. That's pretty much . So many questions. Not a |
|
| 75:19 | but a comment. I think Tak like a portal where you can do |
|
| 75:23 | the DNC sessions online in the Web E. I don't know if it |
|
| 75:27 | be any better or any worse. , just Yeah, okay. I |
|
| 75:33 | aware of it. I'll check it . If that's the case, then |
|
| 75:36 | see what steps are. Wow. you. Any other comments? |
|
| 75:54 | so in that case, I'll stop . Okay? Thank you. So |
|
| 76:00 | guess sharing my screen again? Uh huh. From cover a couple more |
|
| 76:13 | before time is almost up. So is I will repeat what I'm doing |
|
| 76:19 | , and it's just sitting getting your set for the next lecture. So |
|
| 76:24 | related to rappels of why the last years I've included issues about power since |
|
| 76:34 | is, um, an important I was a on everybody's mind whether |
|
| 76:43 | design process of chips or memory chips servers or whatever it is industry you're |
|
| 76:50 | or you're actually using stuff. And a zip's. So you have said |
|
| 76:54 | rappel waas initial design thio control the consumption in data centers. So here |
|
| 77:02 | kind of the reason that, um scale things matters a lot. So |
|
| 77:10 | took a rule of families that the power consumption during the course of a |
|
| 77:17 | costs about a million dollars. So means if you look at it the |
|
| 77:22 | companies Andi other hosting companies that are large data center. They spent millions |
|
| 77:31 | it's not tens of millions in a data centers in terms of Google and |
|
| 77:35 | and these others. They spent this hundreds of millions of dollars every year |
|
| 77:39 | utility bills for electricity and cooling. this is just showing a little bit |
|
| 77:47 | you don't think of data centers as basically predominant, predominantly plumbing. |
|
| 77:53 | yeah, on the left side is see that and impressive pictures in terms |
|
| 77:59 | number of servers and Brazilian servers. rarely show you the plumbing that it |
|
| 78:04 | actually operated take a century after having middle column. Um, the other |
|
| 78:12 | why they things has become important is sends pretty much a decade back. |
|
| 78:21 | cost off power and calling during the of the system exceeds the cost off |
|
| 78:30 | actual system itself. So I know lifetime cost of ownership, fire and |
|
| 78:37 | dominates, and that's clearly why you , the Internet companies and others have |
|
| 78:43 | a lot of efforts in trying to the power consumption as so does. |
|
| 78:49 | know, Intel Andy and the Chip from their hands and just just saying |
|
| 78:56 | yes. Park may have increased depression the total cost of ownership. |
|
| 79:03 | yes, they have grown over But it's not. The full reason |
|
| 79:08 | it is so. In another part if one looks at the total energy |
|
| 79:13 | , electric energy consumption off anything Thio, the information and communication technology |
|
| 79:21 | city for short, shared a significant of the total energy. And it |
|
| 79:27 | out that the data center part, is kind of servers and disks, |
|
| 79:33 | an increase in fraction off that increase . So it's part of the reason |
|
| 79:38 | it has become very big issue and the last few years. Since this |
|
| 79:47 | something about 10 15 years back, one is clearly there is environmental |
|
| 79:53 | among other big uses. For this is just showing a little bit |
|
| 79:58 | evolution off a surface temperature. It's bit cold and should try to find |
|
| 80:03 | new one, but it's pretty And here's the correlation between some of |
|
| 80:08 | emission part course, not Data center not the only ones, but again |
|
| 80:13 | centers are in. Computing is an part of the total energy consumption. |
|
| 80:22 | a little bit off comparing energy consumption observer compared to your car, so |
|
| 80:27 | might be curiosity item. So the has taken notice. So you look |
|
| 80:35 | the big consumers again, like Facebook and others. What they |
|
| 80:40 | they try. Thio do clean power they do hydro electric car and wind |
|
| 80:45 | . The large degree and they locate data centers come close to where there |
|
| 80:51 | , um, plenty of electing hydro power or, for that matter, |
|
| 80:57 | recently, or whether it can get at, um are discussed by locating |
|
| 81:05 | in cool climates like this Facebook Data . And I think I will |
|
| 81:13 | That's an environmental concern, but part the reason that I'm going to get |
|
| 81:18 | next and this how power consumption related computing effort of the work that is |
|
| 81:25 | done and over bunch of years back made the point that typical service did |
|
| 81:35 | have energy proportional computer and power. yes, part I went down with |
|
| 81:39 | workload, but nowhere in proportion to workload. And that's what I want |
|
| 81:45 | talk about next picture. So time up so I will stop and take |
|
| 81:52 | . If there are questions, If now stop the recording, it |
|
| 82:05 | |
|