| 00:02 | Okay. So today, what my is to give you the aspects uh |
|
| 00:15 | of the aspects of the platforms you're on now and in the future that |
|
| 00:22 | important to understand whether they're cold you're uses the resources well or not. |
|
| 00:32 | it's gage tourists the elements of processor that are important for understanding resource use |
|
| 00:47 | mm Okay. So that's the way kind of organized. It's respect to |
|
| 00:56 | types uh Cpus the first in the , as I mentioned at the beginning |
|
| 01:04 | the of course the first lecture that trying to understand what's important for conventional |
|
| 01:17 | server. Cpus then look a little closer at GPUS or accelerators but for |
|
| 01:29 | that will only be on GPS but trying to understand a little bit more |
|
| 01:38 | for a long time it was that so called X 86 Type architectures for |
|
| 01:47 | instruction set. The story way back Intel had the models processes labeled something |
|
| 01:56 | and that instruction set is then run only by Inter but also by MD |
|
| 02:01 | a few others, but because of becoming a prime the same constant. |
|
| 02:13 | number of things started to happen in in recent years that there is a |
|
| 02:18 | of architectures and in particular architecture is for being energy efficient. Has now |
|
| 02:27 | entered into the general sort of computer , not just in the mobile computing |
|
| 02:34 | . So I'll give a bit of on these things and and generals platforms |
|
| 02:43 | processors have become what's known as heterogeneous try to bring that up just to |
|
| 02:48 | you an orientation of what's out there try to assess the thing that you |
|
| 02:53 | be using and getting assignments. So I said a few times already, |
|
| 03:03 | high performance, as far as I'm is synonymous with high efficiency and you're |
|
| 03:09 | um kind of getting high performance or to have good resource efficiency, that |
|
| 03:19 | you need to understand what capabilities are the platform you're using as well as |
|
| 03:25 | also have to understand both the application the code. They are not synonymous |
|
| 03:32 | you have an application in mind and find some algorithms for it and then |
|
| 03:37 | call it up and several different steps their choices once even from given |
|
| 03:46 | your sources of algorithms and their choices you produced the code. So one |
|
| 03:51 | to understand Both consumption of the bottom the top 10 No one is working |
|
| 03:58 | . Mhm. So the things are to stress today is kind of this |
|
| 04:05 | bit of laundry list on this Uh It's important to understand the degree |
|
| 04:14 | perilous that exists even in a single or single processor, which is kind |
|
| 04:22 | more than the number of course is to it than that. We'll bring |
|
| 04:27 | up as I talk about the various today. Uh There are things to |
|
| 04:34 | attention to when one looks at the of the various processors is what's shared |
|
| 04:43 | what's not and what's private for the and it's typically has to deal with |
|
| 04:51 | parts of the memory anarchy but and buses that feeds and will stay in |
|
| 04:57 | that are shared. Another important whether it is has some form of |
|
| 05:06 | instructions of the instructions Uh typically called instructions uh with an extra part and |
|
| 05:16 | V a like w very long instruction has a little bit more flexibility than |
|
| 05:21 | instructions, so they're not identical or synonymous. Another thing that is usually |
|
| 05:33 | need to look at the kind of of description, a little bit on |
|
| 05:37 | marketing materials. Sometimes it's often hard come by the fact that because of |
|
| 05:48 | is such an important role in modern , most of them have firmly under |
|
| 05:55 | the clock frequency. So you as I mentioned, I think last |
|
| 05:59 | you don't have full control um by , uh I thought frequency is being |
|
| 06:08 | so I'm trying to understand whether the is making good use. One also |
|
| 06:14 | to understand what's going on under the to some degree and then there is |
|
| 06:20 | memory system then as I mentioned is weakest part of the system. |
|
| 06:25 | And depending upon applications, different aspects the memory system is critical. So |
|
| 06:34 | insee to the various levels in the hierarchy, there is the bandwidth issues |
|
| 06:40 | there's also it's just like cash line that are important and how when there |
|
| 06:50 | capacity conflict mrs Howe But the rules for kind of writing or replacing what's |
|
| 07:00 | in the cache. And then there other things that is known as cash |
|
| 07:05 | selectivity that has to deal with how places in a given cash that the |
|
| 07:13 | item can be written to today. will mostly mention these attributes of a |
|
| 07:25 | and I'll talk more in a later about some details of the memory hierarchical |
|
| 07:32 | system. And then we also need pay attention to the data paths that |
|
| 07:39 | available for moving data around between caches to of course in the same |
|
| 07:51 | So I guess that still be hard ask I guess and figure it out |
|
| 07:57 | in this virtual environment that And we're to know how many of you are |
|
| 08:04 | with these concepts and for many these kind of new. So I don't |
|
| 08:09 | how to do that. Maybe you suggestion can monitor to some degree or |
|
| 08:19 | figure out. Next lecture will be to face again. So maybe they'll |
|
| 08:24 | it at that time. It's hard . Okay, so this is what |
|
| 08:29 | going to try to point out when talked about various processes in the next |
|
| 08:35 | side or today. It's a preamble try to uh condition you what I'm |
|
| 08:43 | to focus on but this is just cartoon and hopefully most of you have |
|
| 08:50 | in one form or another before. well I can't do best to illustrate |
|
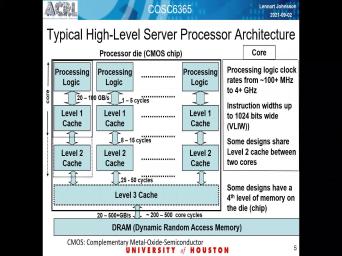
| 08:58 | yes in each process there's tend to a collection of course that has some |
|
| 09:06 | of processing logic that are floating point , integrate units and compares com pretenders |
|
| 09:14 | branching logic and all kinds of other . Instruction decoders basically complete computer in |
|
| 09:24 | in terms of all being able to and make use of instructions and reference |
|
| 09:33 | . Then there are some piratical caches so today is when it comes to |
|
| 09:42 | process is definitely the most I think of them have 3 11th of cash |
|
| 09:46 | there included in the process and they're part of the same piece of silicon |
|
| 09:54 | the data rates between the different levels cash and my memory where is quite |
|
| 10:02 | bit. And so does the latency the distance in terms of processor cycles |
|
| 10:10 | , where data lives and talk in about that when I talked about various |
|
| 10:18 | . Um but uh you can see it's in this case mm if you |
|
| 10:31 | at the for a single core which kind of a column in this cattle |
|
| 10:40 | the the data right between The functional of processing logic and the level one |
|
| 10:48 | is nor less the same as the rate to main memory. Typically a |
|
| 10:58 | bit less so but if you look the numbers in terms of gigabytes per |
|
| 11:06 | they will notice that it doesn't take cores to need access to main memory |
|
| 11:14 | the main memory, then that becomes limiting factor. It's like and there's |
|
| 11:21 | numbers on this line is kind of course if you don't have any data |
|
| 11:26 | use, they basically such a right the memory And it's also about two |
|
| 11:34 | of magnitude or the country more. . Between the agency or the distance |
|
| 11:42 | terms of compute cycles to the main compared to level one cache. So |
|
| 11:51 | are fire, quantitative numbers are The best to try to understand how |
|
| 11:57 | work they need on data without being . Brand was limited the way we |
|
| 12:03 | about in terms of the real fine in the last match. So there |
|
| 12:11 | more or less a similar picture. reminding your terminology that registers are they |
|
| 12:18 | closest to the execution units and the units, ADDers, multipliers, uh |
|
| 12:28 | unit. They all operate on data registers. Register files sometimes gone. |
|
| 12:36 | those are basically a single cycle away . So you can grab things out |
|
| 12:43 | registers and put data back in registers a single cycle. And that also |
|
| 12:51 | to bandwidth between the register file and collection of registers and the functional businesses |
|
| 12:57 | high in order to try not to to be able to support to functional |
|
| 13:05 | . But then as you move away the ability to move data has produced |
|
| 13:18 | and in front of it discussed, wiring complexity. We'll talk a little |
|
| 13:26 | more about that I guess some slices come but there are 10s of thousands |
|
| 13:35 | or more wires on a single piece silicon. So then tend to be |
|
| 13:42 | ones that defines the cheap area. the logic. Yeah. And then |
|
| 13:51 | is different levels of cash and I'll a little bit more about that on |
|
| 13:58 | next side. The one thing that wanted to end if you look at |
|
| 14:05 | of the sub folders on the cash say that as I mentioned last time |
|
| 14:10 | , when I talked about stream that processors don't strictly follow this notion of |
|
| 14:19 | move from one level of cash to next level of cash etcetera from main |
|
| 14:24 | to the execution units and then back cash policies sometimes are not helpful. |
|
| 14:34 | actually her performance and for that reason are many architect as a way of |
|
| 14:42 | caches and sometimes that's called us non stores. For instance, if you |
|
| 14:48 | to write things back to memory and caches, other things that some |
|
| 14:58 | you know, perhaps not everyone is with some of the main memory that |
|
| 15:07 | called Iran for dynamic random access it's by no means random access and |
|
| 15:14 | talk about that in a subsequent lecture the design of those, the main |
|
| 15:20 | do something called double data rate designs then it's followed by a number that |
|
| 15:28 | kind of the generation of the design specification or standard for this double data |
|
| 15:34 | memories. So today's recent year PCS server processors that used to be R4s |
|
| 15:46 | wants to three and there's still some it around and take reasons depending upon |
|
| 15:53 | what the market is for processors to an older memory technology And there is |
|
| 16:01 | some indeed er five standard but it not yet been support it but I |
|
| 16:07 | towards the end of the year news that are coming out are expected to |
|
| 16:12 | engineer fine but not yet in production beyond that just played a disk in |
|
| 16:21 | and they're not deal with this can storage in this cost. Mhm So |
|
| 16:30 | is uh just a little bit again the same pictures before but something I |
|
| 16:39 | encouraged everyone to do and try to performance. Follow the data, where |
|
| 16:46 | it start and where does it end ? So and for pretty much most |
|
| 16:54 | , data starts in main memory or in any part in the cache hierarchy |
|
| 17:00 | to start somewhere else. And if a real time of steaming processors main |
|
| 17:05 | , maybe someday I input but and the results obviously the registers are not |
|
| 17:15 | end point for the results but it to come out of the system |
|
| 17:23 | Mhm. In most applications it is case that there is more input data |
|
| 17:30 | there is output. data. That's this kind of read errors are the |
|
| 17:37 | words and my graph here that and as a simple example that there's more |
|
| 17:45 | being read and written just thinking about matrix vector multiplication where you have to |
|
| 17:51 | Y and X. Um why? the results. That's the thing here |
|
| 17:56 | right back to memory or some other of output and that is can be |
|
| 18:05 | there Largest. So if you have taking us may take 30,000 3000 and |
|
| 18:11 | have a million elements But why? just 1000 elements of it's not just |
|
| 18:18 | small factor that can be a huge in terms of the amount of of |
|
| 18:22 | to be loaded compared to what's Mhm. So many, some mentioned |
|
| 18:34 | time a lot of processes kind of designed to do very well for matrix |
|
| 18:43 | . Of course not everything is made operation but has been a core operation |
|
| 18:51 | on and it still is in and you look at machine learning and many |
|
| 18:56 | types of applications, it still is that tends to have more important than |
|
| 19:05 | data. Mm So as the black is the capabilities and the red things |
|
| 19:14 | , especially pointing to the needs rather the capabilities of systems where the capabilities |
|
| 19:23 | the black errors is the function of trade off, what's costly and what's |
|
| 19:32 | and the assumption that many applications somehow an option for data reuse. So |
|
| 19:41 | you design your algorithm picked algorithm as . And the realization or implementation of |
|
| 19:49 | in terms of software is such that can make effective use for memory. |
|
| 19:54 | always stay down. So that's why point is to try to get all |
|
| 20:00 | pieces to work. So the performance kind of ideally determined. I say |
|
| 20:07 | level one cache and not finding memory that's again the roof flying and these |
|
| 20:13 | intensity we talked about last time where place at all and there is some |
|
| 20:25 | basically how things works as I mentioned that registers pretty much all this and |
|
| 20:32 | of the architecture. So it's just cycle away. Just take 1 2nd |
|
| 20:36 | move data from for two registers and functional units. And there is usually |
|
| 20:44 | wiring to be able to move all operas needed for an instruction from the |
|
| 20:55 | file to functional units and back. all this data path can be operated |
|
| 21:01 | parallel. So one can, if isn't registered, one can operate functional |
|
| 21:11 | , kind of full speed full But the other point I tried to |
|
| 21:16 | out here that means that data rates the ability to move data is quite |
|
| 21:27 | in a way on modern processing So it's in order 10s of terabytes |
|
| 21:33 | second at the innermost level if one a function units and what any that |
|
| 21:45 | I said, that means 10s of of wires and we also know that |
|
| 21:56 | process soon, I think I showed pictures, you know, I'm a |
|
| 22:00 | the board if you haven't seen them and when you buy a processor |
|
| 22:06 | into the MD or somebody else, something that maybe if it's a big |
|
| 22:11 | , maybe an inch by an inch little bit more. But you |
|
| 22:16 | they realized it's sort of sure 10s thousands of connections on that kind of |
|
| 22:23 | area. So it's just not feasible bring everything out for mechanical reasons. |
|
| 22:32 | , so in order to try to with all kinds of limitations on the |
|
| 22:40 | , cash is exists and has been existence for a long, long |
|
| 22:45 | What has happened over the years? , that's got them more and more |
|
| 22:48 | them in terms of um not sizes , but ah, hierarchy, that |
|
| 22:55 | different scopes. So as I there's typically three levels of cash on |
|
| 23:01 | on Pcs today and they Level one designed to be pretty much as close |
|
| 23:11 | functional units as the register's not sometimes it's just a single cycles between |
|
| 23:16 | one and register file, but sometimes a couple of seconds. And as |
|
| 23:22 | get 11-11 3 then they come further . The reason is also that The |
|
| 23:33 | one by being designed to operate at speed. They also tend to both |
|
| 23:40 | more power and take a bit more per bit than the other 7 - |
|
| 23:50 | , 3. So it's again a off based on properties the technology being |
|
| 23:57 | to implement Cashes wire one has this enough just to one level of |
|
| 24:06 | Another thing to the bandwidth is a that in terms of the process of |
|
| 24:11 | and I will talk about later is one is to look at the with |
|
| 24:16 | data path and the rate at which operate. So typically and most of |
|
| 24:24 | chips today, different parts of the piece of silly can operate at different |
|
| 24:30 | frequencies and that means that different levels cash may operate different clock frequency is |
|
| 24:39 | buses or the data path on the may operate the different clock frequencies that |
|
| 24:45 | caches or the functional units. So needs to pay attention to not only |
|
| 24:56 | some buses but also the data right operates that in order to actually understand |
|
| 25:03 | feasible and whether resources were used or and um uh because that's all |
|
| 25:15 | that's main memories several 100 cycles So this is kind of a bit |
|
| 25:23 | recall and didn't talk much about you know, it was on the |
|
| 25:26 | in last lecture but just to get perspective on things and 11 can look |
|
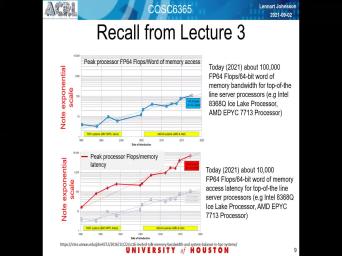
| 25:33 | it from the bandwidth perspective, that the upper graph, we can look |
|
| 25:38 | it from the latest perspective that is lower graph in this slide and it |
|
| 25:46 | , and this line was done not long ago, but john Mcalpin, |
|
| 25:53 | is not the university of texas in and he is generally known as Mr |
|
| 25:58 | and he was the one that first up with the idea of the memory |
|
| 26:04 | stream that has become widely used even , many years after he came up |
|
| 26:10 | the idea but the artist slide is terms of state of the art processors |
|
| 26:20 | doesn't quite sure how in some sense or what the capabilities are in terms |
|
| 26:30 | processing or functional units on a chip the ability to feed the chip. |
|
| 26:37 | this has here's a fit, take recent generation of inter process is that |
|
| 26:44 | is 83, to that is the that was released this year, You |
|
| 26:50 | do about 100,000 floating point operations in time it takes just to get one |
|
| 27:00 | work out of memory that gives some also how hard it is or well |
|
| 27:08 | to use memory hierarchies and what it of an application or the computation in |
|
| 27:14 | to be actually sustain the performance close the functional units can do on a |
|
| 27:23 | . So for most applications, as mentioned, day before they end up |
|
| 27:30 | memory band was limited, it if you look at the agency, |
|
| 27:37 | not quite as bad and the bottom is the red line is really looking |
|
| 27:43 | the number of floating point out for you can do in the time it |
|
| 27:47 | too rich even data item from memory that hasn't changed much since john mcalpin |
|
| 27:53 | graph. And the lower curve is just for reference putting the upper blue |
|
| 27:59 | on the same rest. But this again takes perspective on again what it |
|
| 28:08 | both been picking algorithms if it's possible the application you have and then watch |
|
| 28:14 | what the code does in terms of realizing what's possible. Yeah, so |
|
| 28:22 | little bit more and then I'll stop a second and asked if that |
|
| 28:27 | So here is, you know, to this simple stream trial age or |
|
| 28:33 | you do in the matrix spectrum. matrix multiplication is kind of in the |
|
| 28:40 | instruction ambassador multiplying and out. Mhm if we try to work it out |
|
| 28:46 | it takes in terms of again moving . So the theme is consistently that |
|
| 28:54 | bandwidth and or memory system is the part. Mhm And so here is |
|
| 29:00 | of just putting some numbers to that . So suppose this takes, you |
|
| 29:05 | , three loads and one story A and C needs to be loaded and |
|
| 29:09 | you store see once it's no results then you also need an address for |
|
| 29:14 | and simplicity and seven supermoon assume matters also 64 bits like for 64 bit |
|
| 29:22 | addresses may I mean the sixth form today uh so it that it |
|
| 29:29 | that's an example. It is everything making it. So that means |
|
| 29:36 | 56 points um for cycle to do single operation. So in that case |
|
| 29:48 | if you run something at 2.5 gigahertz it is fairly typical. Some processes |
|
| 29:55 | faster as you will see today and mean it was well And some of |
|
| 30:00 | may actually four GHz for a little more than that even so it's by |
|
| 30:05 | means the worst case. So this kind of a single threat needs, |
|
| 30:12 | doing this operation. So now if think what a single processor chip can |
|
| 30:23 | And if you have 256 threads running the same piece of silicon, that |
|
| 30:29 | you need about 36 terabytes per second order to sustain uh the ability to |
|
| 30:36 | this instruction on the top. So if you look at typical service and |
|
| 30:47 | they use so called dual in line modules of dims, we'll talk more |
|
| 30:54 | that in a later lecture but that's of a memory module you used and |
|
| 30:59 | onto the motherboard and This now they four us again the fourth generation of |
|
| 31:07 | double data rate memories and the 3200 you the cop grades of that memory |
|
| 31:14 | again we'll talk more about it later it means that this is kind of |
|
| 31:19 | top of the line memory module today is supported by pieces or servers And |
|
| 31:24 | can do 25GB per second. So basically More than three orders of magnitude |
|
| 31:33 | . So if they try to support functional units directly from main memory at |
|
| 31:42 | terabytes per second, that would mean it would actually need 1400 memory modules |
|
| 31:48 | this type for a single processor So that's obviously not realistic in the |
|
| 31:57 | place to get that many memory channels a single processor chip. And if |
|
| 32:07 | multiply it out, I mean 64 times 1400. So that is right |
|
| 32:13 | to 100,000 wires, you would need get out of the processor. So |
|
| 32:17 | doesn't really work. Mhm. So also says in order to actually again |
|
| 32:25 | it. We'll need to have applications has potential for data reduce and then |
|
| 32:30 | to figure out hard to realize that . But there's also another aspect that |
|
| 32:36 | critical and that's the other part that the energy consumption. So the energy |
|
| 32:45 | for this type of memory module is what doesn't sound like much five pickled |
|
| 32:56 | Corbett. But if you were to that and operate that these 36 terabytes |
|
| 33:01 | second, what it means is The would consume about 1004 kW. So |
|
| 33:10 | again not realizable in any way see use or can be a parliament far |
|
| 33:19 | but this is I would say 4, 5, 6 times even |
|
| 33:25 | power hungry. She presumed wounded. in the end it's just not |
|
| 33:34 | Uh so on, no stop after slide. So this I just give |
|
| 33:42 | little bit of comment in terms since talk why it's necessary to use |
|
| 33:49 | His soul. You don't need to about the whole slide the scandal cut |
|
| 33:54 | bottom lines or a rose in this little table that says islam. That |
|
| 34:00 | kind of cash so and the best of castro versus if you were to |
|
| 34:07 | to go to main memory so it's the factor of 100 plus in terms |
|
| 34:14 | energy consumption difference between using cash is using main memory. So that's again |
|
| 34:24 | an energy perspective it's necessary to make , use our caches as well as |
|
| 34:31 | a performance perspective and I can stop and see if there's any questions and |
|
| 34:40 | will switch to talk and give you process for examples. Okay, so |
|
| 34:56 | move on to talk about processor examples here is just a little bit of |
|
| 35:04 | recent generation of processors and the last our community to us. So the |
|
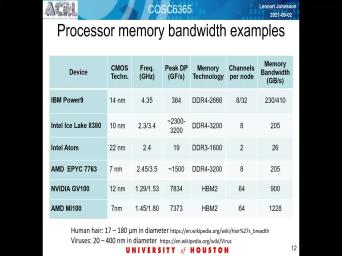
| 35:19 | guess things I wanted you to pay to here is I guess the memory |
|
| 35:25 | that these processors chips support. So top of the line ones they support |
|
| 35:36 | eight memory channels today and they Use DVR four memories or 34, 30 |
|
| 35:46 | version of and that's the fastest they to support and that means to get |
|
| 35:53 | 200 gigabyte per second per psychotic and bottom ones are at the DP US |
|
| 36:11 | the thing for them, it is the fact that of Between depending upon |
|
| 36:19 | models use 4-6 times the memory band such a gap on a CPU the |
|
| 36:27 | in the middle intel atom just put there as an example of something that |
|
| 36:36 | typically designed for mobile processors are that used in cell phone risks in some |
|
| 36:46 | , still used in cell phones. they don't have many much of memory |
|
| 36:50 | and memory language it and they also a lot cooler. So they said |
|
| 36:55 | want to do what processors were as rest of them runs it maybe a |
|
| 36:59 | of 100 once the other thing I I should comment on on this flight |
|
| 37:05 | in terms of memory technology is something most of them says they are and |
|
| 37:11 | version and then there's HP N that for high bandwidth memory that will also |
|
| 37:17 | about subsequent action when I talk about more in detail, but these are |
|
| 37:26 | a different way of being integrated with processors and that allows for the higher |
|
| 37:32 | that is giving the name to the . Right. Um Yeah, so |
|
| 37:43 | this is a little bit kind of summer a little bit, but I |
|
| 37:46 | talk about in terms of the number threats. Again, a level of |
|
| 37:49 | listening to have in each processor. today there's tens of thousands of no |
|
| 37:57 | of threads. Sorry that for typical processors where it's in the several thousands |
|
| 38:12 | in the case of GPU s but also needs a limited type of primary |
|
| 38:20 | and GPS because they are this simply . So things needs to be |
|
| 38:27 | you need to have application in which can the organizer, single instruction operates |
|
| 38:36 | data at the same time. This not necessarily the case in a sip |
|
| 38:43 | that has the w so yeah, flexibility and what you can do in |
|
| 38:48 | single instruction. Um so now too and questions meanwhile, thanks. So |
|
| 39:10 | first example is for I would say the most ambitious and complex and feature |
|
| 39:23 | processor out there today. That is IBM power series of processors. They |
|
| 39:32 | lots of features in them and they That's awesome teacher, which course. |
|
| 39:42 | that means it doesn't tend to have very high core count on a single |
|
| 39:50 | of silicon because each one its core requiring a fair amount of realistic. |
|
| 40:01 | one thing again, coming back to path and is one important aspects of |
|
| 40:06 | processors and what you can do with . Um kind of a little graph |
|
| 40:14 | in the middle. This shows you weakness of the data pass in this |
|
| 40:20 | between the level two and level It doesn't say it's between level one |
|
| 40:24 | the way IBM does it for this the include the level one in what |
|
| 40:33 | label core. So it's inside that of silicon. So but it's says |
|
| 40:42 | mhm ability to move data from L to L one is 256 bits white |
|
| 40:54 | a stability from to write things from 1 to L two Is only 64 |
|
| 41:00 | . So it's a factor of four terms of the ability to load data |
|
| 41:05 | Store data between L one and L between L two and L three is |
|
| 41:11 | of balanced and I think it depends yeah, application, they have been |
|
| 41:17 | what they see as important. So this case obviously came to the conclusion |
|
| 41:26 | it was okay that between L two L freedom may be fine to have |
|
| 41:32 | much the same capability for loads and But when it comes to L 3 |
|
| 41:38 | make memory it's again, 2 to . I shouldn't say again, it's |
|
| 41:44 | to 14 to one and two to three. 2-1 is kind of common |
|
| 41:49 | most processes but this social little bit this case. So the market that |
|
| 41:57 | targets for this tip is most transaction or database processing. Uh No so |
|
| 42:11 | for the scientific and engineering type computation . So you don't as well as |
|
| 42:21 | the internet type applications so you don't many power type architectures. Yes but |
|
| 42:29 | or google or Microsoft for that Mm Other things to pay attention to |
|
| 42:37 | terms of um the cash is is ice. So in this case the |
|
| 42:46 | one is 32. Tell avoid most the process that have separate Instructions and |
|
| 42:54 | Cache at that Level one. But level two there tend to be um |
|
| 43:02 | er or unified. I said sometimes so data instruction share down to use |
|
| 43:09 | they tend to Have their own one and 32 kilobytes. The sephardic |
|
| 43:17 | Size for L. one data and caches. So when you come to |
|
| 43:24 | . two as I mentioned the tend be bigger. So for this case |
|
| 43:29 | too is 512. So considerably bigger the 32. So So that is |
|
| 43:40 | 16 times bigger. So it's noticeable . The other thing that is somewhat |
|
| 43:48 | for this architecture is That the cash sites that means seven amount of data |
|
| 43:55 | that is moved together between the cash and the main memory. That is |
|
| 44:03 | as a block of data that is of atomic. And in terms of |
|
| 44:07 | stuff around 128 fight is a bit than the most common is 64 |
|
| 44:17 | And one more thing to point out as I mentioned in terms of the |
|
| 44:23 | , it's what's known as associative No and then maybe you know where |
|
| 44:29 | off but if you don't it's a of places to which a chara fine |
|
| 44:37 | and be assigned in the cash. in a four way cash it means |
|
| 44:48 | cash line taken from memory can be in one of four places in |
|
| 44:54 | It cannot go in an arbitrary So in terms of associative itty of |
|
| 45:01 | is there are at one extreme direct caches that means There is a 1 |
|
| 45:08 | one correspondence between location and cash and memories. You can only go in |
|
| 45:14 | place. So if you need to something that means that whatever is in |
|
| 45:21 | location uh oh maybe over it. if that's allow otherwise that thing first |
|
| 45:29 | to be stored the memory before you load the data, new data that |
|
| 45:34 | to go in that place. And the other extreme is the fully associated |
|
| 45:40 | language case whatever comes from memory can stored in any place in the cash |
|
| 45:50 | then there's different cash policies and I will talk about that later in |
|
| 45:54 | of when you have a choice where you choose to store the data and |
|
| 46:05 | things? So in this case it's power hungry processors on this consent, |
|
| 46:11 | known as the T. V. . That is a thermal design power |
|
| 46:16 | is the participation that the processor is to be able to sustain. It's |
|
| 46:27 | necessarily as I mentioned last time, maximum power that the process that will |
|
| 46:35 | use and that needs to be cool of the TDP is a common number |
|
| 46:43 | it's important to realize that is not for the maximum power consumption of the |
|
| 46:50 | . Okay, that's in the As I mentioned last time that one |
|
| 46:55 | the computer vendors that we both come from mate and I think that's and |
|
| 47:07 | guess one part, one more comment this ship is that as I |
|
| 47:14 | I've been targeted, I don't know processing or database applications. So that |
|
| 47:21 | memory bandwidth is particularly critical. Um for that reason the in fact, |
|
| 47:29 | the chip itself has a channel is memory but then they actually made kind |
|
| 47:35 | a buffer memory if you like. replicates each one of the memory channels |
|
| 47:40 | the processor chip four times. So fact it has a little of 32 |
|
| 47:50 | to main memory. So that also you can have a lot more main |
|
| 47:58 | on the single processor than most other can. And when you read things |
|
| 48:04 | this systems, that means you have better chancellor cashing things in main memory |
|
| 48:09 | in most other designs. So here an inter skylight now. So I |
|
| 48:19 | to probably not spend as much time each one of the new other processes |
|
| 48:24 | try to allergic to things and just out some differences. So Skylink is |
|
| 48:30 | one that is being used on stampede . It's not the most recent generation |
|
| 48:35 | mental that the slide on that but um this is what you come |
|
| 48:41 | you, so it has 28 so that is kind of more than |
|
| 48:47 | a little bit more than a number course on the IBM process I asked |
|
| 48:51 | about Yeah, the other is instead forgot to mention on this uh IBM |
|
| 48:59 | but we'll go back and bring it now and that is up here in |
|
| 49:04 | corner that says there's a little bit confusing terminology in terms of threads when |
|
| 49:11 | comes to processors, uh and it's because slightly different mechanisms used to handle |
|
| 49:21 | threads on a single core. So call it simultaneous multi friending or S |
|
| 49:28 | t. Um and the course on IBM system is basically designed to Be |
|
| 49:42 | to manage four threads concurrently within the court. Well, actually I |
|
| 49:54 | Um Yes, so for now, good enough. So On the other |
|
| 50:06 | , if you look at the more instructions that type architectures, which is |
|
| 50:13 | the power crosses surrounds, it runs own instructions. Um So for the |
|
| 50:20 | that originated by internal way, way . Um the comment thing is that |
|
| 50:28 | are designed two be capable of managing threads, that's the same time and |
|
| 50:38 | call it high preferably and so there's M D. But the mechanism for |
|
| 50:46 | the friends are different and that's partially the different terminology is fair. So |
|
| 50:52 | doesn't confuse the different mechanism. We need to get into the mechanism and |
|
| 50:56 | of course, but things to be of that, both the chips on |
|
| 51:04 | too as well as stampede to are to manage to threats for court now |
|
| 51:14 | admins can configure whether they enable hyper for now and now. I do |
|
| 51:24 | remember about to ask my man remember many times size, turn off the |
|
| 51:34 | of hyper spending and the reason is back to an earlier flight today, |
|
| 51:43 | everything in the core is kind of private to the core nor replicated for |
|
| 51:53 | threats and most things are in fact between the threats operating in the same |
|
| 52:02 | . So that means if you have than one thread then threads compete for |
|
| 52:09 | same resources and may in fact the performance from the uh improve performance. |
|
| 52:18 | hyper threading is good when kind of for instance, memory to deliver things |
|
| 52:26 | maybe one of the threads has stuff so it can proceed then there is |
|
| 52:33 | really contention for say functional units and have with it. Multiple threats may |
|
| 52:41 | win. But for many well designed als, that's not the case. |
|
| 52:50 | multi threading loses. So I think the past for bridges, one final |
|
| 52:56 | correctly, Pittsburgh turned off multi threading maybe the stampede you had enabled |
|
| 53:07 | is that correct? Yes. Until threading enabled british doesn't right. I |
|
| 53:14 | know for bridges to what the status , I think it or it still |
|
| 53:22 | a hyper turning off but just this point to be aware of again, |
|
| 53:29 | you try to understand cold and cold , this notion of hyper threading and |
|
| 53:35 | one shouldn't make the mistake and believe when you use more than one |
|
| 53:41 | the performance doubles and I asked shouldn't great because so many resources are shared |
|
| 53:49 | then maybe contention for the same resources you enable more correct. Um the |
|
| 53:57 | thing I didn't comment so much on the, on the IBM process is |
|
| 54:03 | notion of very long instructions. Word our Cindy features, which is something |
|
| 54:13 | you can do basically you have kind similar to what's the case for Gpus |
|
| 54:22 | there replication of a floating point units allows you to do in a single |
|
| 54:31 | many same mouth ads in the same . So you get the very wide |
|
| 54:39 | that then if they application is such the code is such that you can |
|
| 54:46 | them into a single instruction than you close to the peak performance average and |
|
| 54:54 | there is and things just considered in case the level on caches are very |
|
| 55:02 | to the IBM power ship. They a little bit more believe level two |
|
| 55:09 | and and so on and it's also Power intensive chips so it's about 200 |
|
| 55:19 | peak um or TDP the thermal design um the other thing that is importance |
|
| 55:32 | so this chip has six memory channels the next generation ship after this the |
|
| 55:41 | increased to eight. Remember the power eight channels that was kind of the |
|
| 55:47 | age as skylink or even a little older. They already had a more |
|
| 55:53 | more on the memory bandwidth team and the processor level and for comparison I |
|
| 56:02 | the the main competitor to into in of running similar instructions um they were |
|
| 56:11 | sir had more memory channels and better with the memory than many other |
|
| 56:18 | Now there's this more comfortable but for long time intel got a lot of |
|
| 56:24 | for not having enough memory bandwidth, processors. The other part wanted to |
|
| 56:32 | attention to this particular sign is the left hand part and that goes back |
|
| 56:39 | this notion I had mentioned earlier on that it is firmware that controls the |
|
| 56:48 | on the chip. So what the left hand graph um intend to tell |
|
| 56:56 | is that Well one used this very instructions and the chip consumes anticipate more |
|
| 57:09 | and that the power dissipated is related the clock frequency. So in order |
|
| 57:15 | to overheat the chip, if you to make use of all the resources |
|
| 57:20 | the chip, it gets clocked out there's nothing you can do about it |
|
| 57:29 | and someone up let you kind of their ship. So they tried to |
|
| 57:34 | you from being too ambitious and trying squeeze performance out of your processor. |
|
| 57:39 | in this particular case, if you to use all the course and using |
|
| 57:46 | full extent that is RAVX five felt , the co operators about half of |
|
| 57:52 | it otherwise would be. So if just have a single thread in a |
|
| 57:56 | core, the clock right? Maybe the more than twice that of before |
|
| 58:03 | used Every X five films instructions. , so here is just a little |
|
| 58:12 | more an additional comment on this slightest to just be a little bit more |
|
| 58:20 | than the previous picture of the fact there is nowadays so many course on |
|
| 58:28 | single process of die that's using kind just a single bus and have every |
|
| 58:35 | talking to a single bus doesn't So each ship today has a network |
|
| 58:41 | it and it's most common today with number of course that are on the |
|
| 58:47 | that fair list, simple in some to the emotional and more sophisticated network |
|
| 58:55 | issues that tend to use to the . So this is just pointing out |
|
| 59:02 | that is the case and the other to make here in terms of the |
|
| 59:06 | level cash, that is the NlC this cash. It's basically, each |
|
| 59:11 | has a little bit of it even it's shared things from an access point |
|
| 59:21 | all of course. But it also that some pieces on the third level |
|
| 59:27 | closer to record than others. So means that the access time To the |
|
| 59:32 | level cash is not uniform on the . So it depends on the relative |
|
| 59:40 | between data and the court that once data on the doctor. Mhm And |
|
| 59:49 | a little bit just to understand that of designs. A fairly complex and |
|
| 59:54 | just so it's a little bit of data path in this case they level |
|
| 60:01 | and the steps of doing instruction the and breaking it down into what they |
|
| 60:06 | on my crops. And some people always in the architecture community kind of |
|
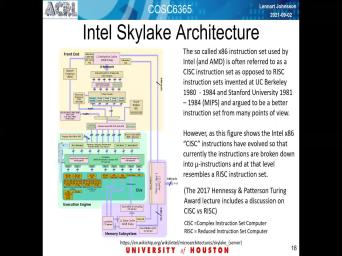
| 60:13 | a not the war but tussle about I should have a complex instruction set |
|
| 60:22 | a simple instruction set known as risk risk now has gained a lot of |
|
| 60:28 | over in recent years that then tend have a much more limited instructions that |
|
| 60:35 | that means it takes perhaps more instructions to get the particular operation done in |
|
| 60:42 | complex instruction set. But it also that the architect and potential can be |
|
| 60:50 | . So what kind of intel has over the years that has been an |
|
| 60:54 | of assist constructions that the kind of now the Microsoft's, that is more |
|
| 60:59 | risk instructions. So they break down complex instructions into risk like instructions before |
|
| 61:06 | get execute. And I would also if you haven't already done that. |
|
| 61:16 | a very useful. Things is not detailed about to get the big picture |
|
| 61:22 | what happens to listen to the triggering lecture given by john Hennessy and the |
|
| 61:30 | a few years back, it's, think that you were earliest on some |
|
| 61:34 | otherwise deceased. The finding by googling here's a little bit how things are |
|
| 61:41 | put together and the west means to as you can imagine. And that's |
|
| 61:47 | of the way things I've put together this stampede pra notes and then there |
|
| 61:54 | higher, you know, socket but as I mentioned before, the |
|
| 62:00 | sockets are by far the most but there are also in particular |
|
| 62:06 | when you have need for lots of but then in an old touch, |
|
| 62:11 | tend to do four socket or eight configurations but and then I also put |
|
| 62:21 | just a little bit for reference uh most recent survey process that there are |
|
| 62:29 | this year. Um I don't know it's fully object but it's supposed to |
|
| 62:34 | available before the end of the year least. Um and the things that |
|
| 62:40 | predominantly has done, they have upped core comes like everybody else on this |
|
| 62:46 | compared to Skylight. Now there are course, not quite the double of |
|
| 62:51 | 28 course but significant more. They design them to do the two threads |
|
| 62:57 | core if you choose to You still this five forward find instructions, they |
|
| 63:07 | a little bit of data size for data cache but the instruction gas is |
|
| 63:13 | the same as previous generations and amount memory is more or less the same |
|
| 63:19 | core. Right Then they have a , they increased from 6 to 8 |
|
| 63:25 | channels and they're also Increase the support data rate for the memory to this |
|
| 63:31 | 200 memory But it's also more fire business that around 200 it's not going |
|
| 63:37 | closer to 300 T. V. . Um So then just uh talk |
|
| 63:46 | little bit on the am decide the competitor 10 until it's not as widely |
|
| 63:56 | because they have had if you misfortunes the the years they were serious competitors |
|
| 64:03 | then they made some missteps and almost out of business and then they came |
|
| 64:08 | and then it started to become competitive I made some mistakes again and again |
|
| 64:13 | went out of business but now when kind of generation on their architecture that |
|
| 64:20 | as theirs and of course they are competitive and gaining a lot of |
|
| 64:26 | So at this point as well worth familiar also the D and d processors |
|
| 64:36 | now if you use clouds and some context um pretty much all the cloud |
|
| 64:44 | now also allow you to choose between instances that runs on intel or run |
|
| 64:53 | AMG tend to be the, if johnson an AMG processor it's likely cheaper |
|
| 65:01 | you then if he runs on an on their long story about that. |
|
| 65:07 | part of the reason for this difference cost is that am they would say |
|
| 65:17 | have been leading or pioneered sign designs later than has been come adopted by |
|
| 65:27 | I already mentioned that have led in of emphasizing memory bandwidth, they have |
|
| 65:34 | led in terms of focusing on power energy consumption so they have always been |
|
| 65:43 | power than intel cpus there are many changes differences too but one that has |
|
| 65:49 | them to the price competitive is that tended to have get the core account |
|
| 65:59 | by using what's known as chiplets that now becoming common industry. So they |
|
| 66:07 | have a piece of silicon in their often doesn't have a large number of |
|
| 66:14 | honest but they put a bunch of of silicon that repeats the modest number |
|
| 66:21 | course on it or in the same . So in fact what you're getting |
|
| 66:29 | a high core count processor but because piece of silicon they're using smaller, |
|
| 66:38 | get the higher yield so that means cost per core is lower. So |
|
| 66:44 | can in that case be able to on price. There was, you |
|
| 66:49 | see in this case things are very . They actually have had in this |
|
| 66:55 | slightly higher in this case the larger cache. Oh but there are kind |
|
| 67:00 | in the same boat podcast you see and they have been trailing a little |
|
| 67:06 | in terms of the with some instructions In this case they have to 56 |
|
| 67:16 | wide instructions was half as wide, half as many things can be done |
|
| 67:21 | a single instruction but they have trying some sense to make up for it |
|
| 67:26 | they have more coarse um there are and end so it's a complex scheme |
|
| 67:32 | figuring out how to stay competitive but can also see that um compared to |
|
| 67:41 | it lower power dissipation. Mhm and is just for your reference uh data |
|
| 67:52 | the I am the processes used in too. So um the so it |
|
| 68:06 | to the internship, I guess one I should point out is they have |
|
| 68:10 | fact a little more level three cache intel has so they have more memory |
|
| 68:17 | the die then even though they also a higher cork are but like the |
|
| 68:26 | , it's the same in this case participation. So let's see so shoe |
|
| 68:35 | examples has said things have gotten interesting terms of diversity things converge for a |
|
| 68:42 | long time. Everything became kind of until because of stumbles by and they |
|
| 68:48 | above all everything was kind of there instructions that the X- 86 that is |
|
| 68:54 | run by MD processes but those processes power hungry. So the mobile community |
|
| 69:04 | the end use either of them. used arm processors that have been designed |
|
| 69:12 | be very power efficient and this is the most recent but I think fairly |
|
| 69:21 | of what you can get in today arm and arm is not building their |
|
| 69:27 | processes. They design processors and the the designs, so Samsung and apple |
|
| 69:34 | that better. Um, and many have used arm processor designs and building |
|
| 69:45 | processor chips. Right? So as can see in this case they are |
|
| 69:50 | even though they are designed for being energy efficient. It's not that they |
|
| 69:54 | skipping on the size of cash is fact even larger. Level one Cache |
|
| 70:00 | than was on the very sophisticated Power or 9 processors. And the same |
|
| 70:08 | with level two Level 3 Cache is by no means sub standard. It's |
|
| 70:13 | that the focus has been different and other features that they don't have but |
|
| 70:20 | of No a couple of 100 watts this case this particular one is like |
|
| 70:27 | . Cool. It's one and a of 10 actually 40 or 50 less |
|
| 70:36 | than the other ones. So that caused a number of companies to try |
|
| 70:42 | figure out how to use this design compete with intel and Andy And that |
|
| 70:49 | happened in the last 5 10 years power became such a constraining factor for |
|
| 70:57 | . So amazon they went off and their own process suits using the or |
|
| 71:06 | using the arm designs. And this just example of using the designs you |
|
| 71:15 | in the previous sign and putting together system using those kinds of processors and |
|
| 71:20 | other components that armed folks design and amazon made a piece of silicon and |
|
| 71:30 | it together and actually making a complete . So today if you use amazon |
|
| 71:37 | can also opt to have your virtual run on what amazon called the graviton |
|
| 71:44 | it's the core of it is armed and then there again cheaper given them |
|
| 71:53 | using the N. D. Instances amazon. And there is just another |
|
| 72:02 | that also based their chips on arm they uh in this case here 60 |
|
| 72:09 | and I'm not going to go into details but a number of companies that |
|
| 72:14 | out trying and playing around with using marvel which is the company time they're |
|
| 72:20 | designed then this is yet another companies that actually build their own silicon that |
|
| 72:30 | with the arm designs. But unlike amazon that you can only use on |
|
| 72:37 | , they don't sell their chips, just use it for running right their |
|
| 72:44 | . But parents to start up founders from into a few years ago, |
|
| 72:50 | about the five year old company that this year released their first processor And |
|
| 72:57 | first release have 80 course, that's a high core count. CPU And |
|
| 73:04 | you can recognize decisis of caches and and numbers are similar to the ones |
|
| 73:09 | had before and again they use eight channels to get to memory. |
|
| 73:17 | and this is a little bit the , I want to say something about |
|
| 73:21 | used to so before I have a minutes left today. So, but |
|
| 73:26 | is a summary in terms of a of course most of them use |
|
| 73:35 | has the ability to have two threats socket. So, and I am |
|
| 73:43 | up to this before or eight threads depending upon its a bit, it's |
|
| 73:49 | flexible design. So you can figure course as the atomic versions, so |
|
| 73:55 | speak or you can gang two of together and treat them as if they |
|
| 73:59 | a single court. But in the , What the chip can do is |
|
| 74:04 | threats. Mm hmm. And the terms is the 32 arithmetic operation is |
|
| 74:12 | you used to say the x fight version and the powers and the course |
|
| 74:17 | pretty much this summary, you know about um, the DP us. |
|
| 74:24 | this is the Gpu that is on ranges too, I think there is |
|
| 74:33 | more release from envy their past the that is installed in the bridges to |
|
| 74:42 | but this is still quite typical and not far off from what the most |
|
| 74:49 | edition from a *** is, they a few different versions depending upon when |
|
| 74:54 | target ai or machine learning work clothes more floating point intensive work clothes but |
|
| 75:01 | point of this, I want to what this slide is uh that the |
|
| 75:09 | of threads or that means the number parallel instruction streams this was just before |
|
| 75:16 | of being in the tends to lower is now and the little thousands to |
|
| 75:24 | thousands but there is the restrictions that threads need to have a lot of |
|
| 75:32 | . So one needs to be able use this Cindy feature. So you're |
|
| 75:40 | have one instruction like mouse pad and you have lots of options on |
|
| 75:47 | Then you can make good use of of the GPS um so what else |
|
| 75:57 | want to stress and this one is thing that I had them in early |
|
| 76:04 | that there is a difference and part the, that was a popularity or |
|
| 76:12 | of Gpus is that they have higher bandwidth and CPU safe to use today |
|
| 76:20 | I said had to play up to 64 Bit White Memory Channels. So |
|
| 76:29 | is uh What 512 bits wide data to main memory persecuted. Where is |
|
| 76:43 | Gpus tended to have more bits and particular now when they have started to |
|
| 76:50 | this high bandwidth memory They have like chosen this slide there's 4000 bits of |
|
| 76:57 | 96 to be precise. So it's factor eight wider data path to the |
|
| 77:04 | . But it also means you don't these things out and use modules on |
|
| 77:10 | motherboard but it actually has to be a single packet. So you never |
|
| 77:17 | out on their motherboard and then you get This considerably how your bandwidth that |
|
| 77:24 | 5-6 times higher than what you see the CPU but it also means you |
|
| 77:32 | kind of restricted in the size of memories. So yes your gang memory |
|
| 77:37 | but you lose in the sights of memories. So Typically what you see |
|
| 77:42 | up to 32 um gigabytes of memory is on there and the political service |
|
| 77:52 | So the bridges to seemed to use think and what 2 56 um Uh |
|
| 78:00 | . Server for the regular memory for extreme memory that may be a few |
|
| 78:08 | . So it's a huge difference in of the memory. So that |
|
| 78:14 | And another aspect of the G U. S. Is there actually |
|
| 78:18 | designed to need a CPU to run they are kind of in a touch |
|
| 78:25 | and they're not self contained. So means the problem usually starts and ends |
|
| 78:30 | the CPU and then the CPU and no need to talk to each other |
|
| 78:35 | solve the entire problem because the memory too small on the GP. And |
|
| 78:41 | I have for comparison the competitor to and number one competitor is A. |
|
| 78:50 | . D. And the again have or broaden their activity now that terrorists |
|
| 78:58 | doing well and have some money. used to be dominating I would say |
|
| 79:04 | terms of the game market whereas NVIDIA on went after this server and scientific |
|
| 79:13 | data center market and now Andy is to do the same and this is |
|
| 79:19 | release from last year that is fully with the recently and envy their releases |
|
| 79:29 | in terms of floating point performance and much anything else. So it's good |
|
| 79:35 | know about the same the chips to my time is always up. But |
|
| 79:41 | I wanted to just mention that the things that I'm there, internet companies |
|
| 79:50 | done in particular google's and has been uh designing their own service for a |
|
| 79:56 | time then even if several years ago they started to thank you for designing |
|
| 80:03 | own silicon and they instead of using US for machine learning they design what's |
|
| 80:13 | as a tensor processing unit. Tpu that has pieces of functional units are |
|
| 80:25 | helpful in getting good performance from machine . And again matrix multiply is one |
|
| 80:30 | the core operations. So there might multiple units on their TPU chip and |
|
| 80:36 | graph up into the right tend to the performance and it's a real flying |
|
| 80:42 | . You see this land dick term then you see the peak performance when |
|
| 80:45 | get to being compute found and then get compute bond. This is a |
|
| 80:52 | scale on the vertical axis. So kind of be deep used by an |
|
| 80:59 | of magnitude more for machine learning and . So I think that's why I |
|
| 81:05 | to point out and this is coming the point that in order to get |
|
| 81:11 | energy efficiency and that's what's behind a of and now many efforts in doing |
|
| 81:19 | processors is that you're getting game orders magnitude in both performance and energy efficiency |
|
| 81:25 | tailoring your designs to your work. and without that I think I will |
|
| 81:31 | skip the last few slides today because time is up conceive and take some |
|
| 81:35 | . This is just given the the of one process we worked with in |
|
| 81:39 | group that shows a different width of data passed on a particular processor and |
|
| 81:46 | the different clock rates for the different that is being used in the system |
|
| 81:52 | with that I think I just stopped and this is something that's josh worked |
|
| 81:57 | also shows this heterogeneous processes that has common in the mobile market where you |
|
| 82:03 | different pieces of silicon that are tailored particular functions like crypto engines and display |
|
| 82:10 | and are your engines and um it's of more floating point and so you |
|
| 82:17 | different types of processors and here is of a snapdragon and you can see |
|
| 82:21 | have the GPU has a display process D P U. Is a vector |
|
| 82:27 | of CPU and has a digital single sp and I said to you so |
|
| 82:35 | , that's other things to also be of. You don't we want deal |
|
| 82:39 | that in the class except attach processor the firm in terms of the GPU |
|
| 82:46 | if you end up working in something to mobile processing, you end up |
|
| 82:52 | the chips that has different functional units has different instruction sets and programming becomes |
|
| 82:58 | more complex than what we deal with the class. Okay, sorry I |
|
| 83:03 | stop there. So any questions. bro. So again, this was |
|
| 83:30 | translucent and to both get to details details are important for understanding performance for |
|
| 83:38 | assignments are going to do plus give a little bit of what's out there |
|
| 83:43 | generally used in other contexts and focus the elements. Again, our |
|
| 83:51 | it's important. Unfortunately it's not just thing. Mhm. Okay, so |
|
| 84:13 | yeah. All right. So when has not been and have few |
|
| 84:21 | I see your username rick, I make sure that happens right now after |
|
| 84:27 | , you know that added sugar access . Yeah. So I'm sorry if |
|
| 84:36 | missed your email earlier, but I seen it. Okay. Yeah. |
|
| 84:52 | . I'll stop sharing screen. I will stop referring |
|