| 00:04 | Okay, so today that's no collection the three on Here is support. |
|
| 00:14 | will talk about So, um, talk a little bit. Developed three |
|
| 00:23 | bench months. And the reason for about this particular, uh, once |
|
| 00:31 | that they're very commonly used. But all, that's Savan. Wait, |
|
| 00:38 | , I have asked you to work in the first assignment. So after |
|
| 00:44 | about this particular benchmarks on, then will talk about something that is known |
|
| 00:51 | the roof line model, for I of tried to capture or seven summarize |
|
| 00:59 | . And then we'll talk a bit the buggers and that will be done |
|
| 01:05 | a way that talk to a few . And then so Yash will demo |
|
| 01:13 | , and I'm sure everyone is. developed code has done debugging but, |
|
| 01:18 | , militants. The first thing that to mind is to use print f |
|
| 01:23 | , try to convince you that there ways for doing debugging than usual in |
|
| 01:27 | death, and it's worth investing the in using the Littles. So that's |
|
| 01:33 | justification for the last point. no doesn't want to. That's |
|
| 01:46 | So in terms of benchmarks, so one thing that you're asked to do |
|
| 01:53 | the first assignment and that suggest Emerald to get specifics off the hard |
|
| 02:01 | using yanking at information the processor in of read caches and as well as |
|
| 02:10 | terms for the memory attached to the . Softer and generations and all of |
|
| 02:17 | that gives you when it comes to hardware, the capabilities of the |
|
| 02:22 | But that doesn't necessarily give you a idea hard. The hace Soto understand |
|
| 02:29 | lot more about behavior. The common of doing that is to use, |
|
| 02:35 | , benchmarks or specific workloads that hopefully something of what you really interested in |
|
| 02:44 | of the system or the coat. again, Norman remind you, wanna |
|
| 02:51 | , And the first lecture is that will problem you mentioned many times over |
|
| 02:57 | the course that to get good one needs to understand the application algorithms |
|
| 03:04 | and the hardware and the benchmarks again a tool to try to get you |
|
| 03:11 | get the necessary insights to get the performance. So the very simplest on |
|
| 03:19 | obviously to have run nothing on the . You're storing it down and then |
|
| 03:26 | put it necessarily mention, compute compute capabilities but basically eating onto power |
|
| 03:34 | that that consists. The system consumes nothing. And as it turns |
|
| 03:39 | um, traditionally, that has been significant port, part of the power |
|
| 03:45 | door on associative energy during the time use it. Over time, things |
|
| 03:50 | gotten a lot better, but it's not a trivial part of it |
|
| 03:55 | Power and energy consumed for computing, idle benchmarks is kind of a classic |
|
| 04:00 | , and it's become more important over . As, uh, Karen energy |
|
| 04:06 | has become more important. And this of sort of mentioned three kind of |
|
| 04:13 | of benchmarks. Something called micro benchmark a kind of or cardinals that one |
|
| 04:21 | and, um oh, the micro so many off them. And here's |
|
| 04:26 | mentioned for ah on of it. will be used in the first assignment |
|
| 04:34 | that stream gabs and dee gym, I'll talk about each one of |
|
| 04:38 | um, in the next few Then there's other benchmarks that is kind |
|
| 04:44 | synthetic, and they try to may certain types of workloads and the most |
|
| 04:52 | known ones are physical spect benchmarks, they come in a few different |
|
| 04:58 | The assessed respect CPU benchmark and we're point benchmark, and then their energy |
|
| 05:03 | power benchmarks. We're not going to them in class in part because, |
|
| 05:10 | , it was not free run. this is Standard Performance Evaluation Corporation expected |
|
| 05:19 | the charge funding. But manufacturers enders like this P i. D M |
|
| 05:28 | . And everybody else. They came use him to tell customers about how |
|
| 05:34 | systems performed, so they're commonly And you often, if you read |
|
| 05:38 | literature and look things up, they tend to see a lot of script |
|
| 05:42 | leader. Then there's another group off that are kind of more application |
|
| 05:51 | Target now hold applications because that becomes cumbersome because whole applications maybe hundreds of |
|
| 06:01 | of lines of code, and it not always be practical to do benchmarking |
|
| 06:06 | them. So one of the common for scientific engineering computer Haitian is an |
|
| 06:12 | benchmark, uh, put together by , and it s a typical compute |
|
| 06:22 | computer algorithms like the one that does bite mouth with normals. Degrade called |
|
| 06:29 | Fourier transform Germinal Sorting and Konica Grady methods. So there's a bunch of |
|
| 06:35 | in there in the nest suite of . And then there are other benchmarks |
|
| 06:40 | the par sick for doing your memory and more horsey bio applications and embedded |
|
| 06:49 | . And again, there's loss of . But for this class, I'm |
|
| 06:53 | Dude was streamed Upson deejay. So talking about Stream The stream is really |
|
| 07:03 | , designed to assess the capabilities of main memory system not just and originally |
|
| 07:13 | just designed for her. Even a core on a single knows, but |
|
| 07:20 | at the time it was first that was the typical processor that you |
|
| 07:27 | . Since then, it has evolved deal with off the court systems on |
|
| 07:31 | that and use open MP and it a cost a type version that uses |
|
| 07:38 | . P I. And we'll talk NPR stands for message passing interface. |
|
| 07:43 | you haven't heard about it before, it's a programming paradigm, used |
|
| 07:49 | open MPs, a program empire down for programming love to court systems, |
|
| 07:55 | we will talk about that too much . Um, so and it's the |
|
| 08:03 | just stream. So it's designed for mimics or capture memory system. Access |
|
| 08:13 | in colds that's mostly male have very memory accesses. It was kind of |
|
| 08:22 | best case scenario in many ways, when I say nice case in |
|
| 08:28 | it's accessing memory locations in sequential order after the other. So it's also |
|
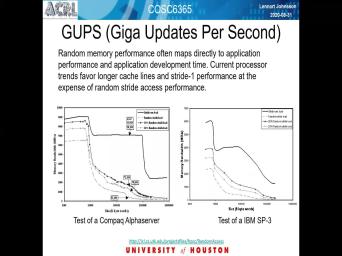
| 08:39 | a Stride one access the graphs on right. Inside is kind of just |
|
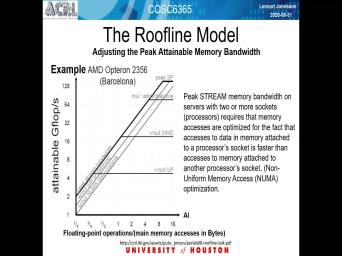
| 08:46 | . For y Stream is important benchmark is widely used is the upper right |
|
| 08:55 | one with a kind of blue jagged at the notes. A number of |
|
| 09:01 | point operations that the typical processor can for word off memory access and the |
|
| 09:10 | axis is time, and it started in 1990. And those upto close |
|
| 09:17 | today not quite so this slide was if you four years ago on oven |
|
| 09:23 | by the designer off the stream benchmark much help in. So the main |
|
| 09:30 | of that side is that it shows number of floating point operations that processors |
|
| 09:39 | do for word all memory access on first one can think of that as |
|
| 09:47 | a great thing that you can do lot. The computations per we're access |
|
| 09:53 | . That is true if your application very heavy on compute, but it |
|
| 10:01 | out most applications are not. They not that many floating point operations per |
|
| 10:06 | item. So this is, in , a problem. So many applications |
|
| 10:13 | therefore what part it, but it memory bandwidth limited. So this is |
|
| 10:20 | shows that over these last over the , capturing that case or so, |
|
| 10:29 | , the capabilities of processor have grown lot faster than capabilities of memory systems |
|
| 10:34 | ice in the order of 100 or so no point operations per memory. |
|
| 10:42 | data item from memory that you can on the red lines of the lower |
|
| 10:49 | Tang graph really addressed this moral Layton . And it turns out that the |
|
| 10:55 | benchmark is very sensitive to memory. . See, that means the time |
|
| 11:00 | takes to get a data item from effectively measured in terms off. See |
|
| 11:08 | , capability or cycle time it. in that case, as you can |
|
| 11:16 | today, it's in the order off 1000 floating point operations that can be |
|
| 11:26 | out for the time it takes to one day there by tomorrow. |
|
| 11:33 | So what is the stream benchmark? the stream benchmark isn't searingly simple, |
|
| 11:41 | it just has four different operation that packaged up in the stream Benchmarks. |
|
| 11:49 | known as Copley Skated some or sometimes called and try it. So |
|
| 11:55 | does his totally trivial thing, reads out of memory and writes it back |
|
| 11:59 | memory. The scale. Read I remember Erin there a on a |
|
| 12:04 | and scale every item with constant and it back. And so these particular |
|
| 12:13 | were justified with what was very common the time for scientific computing. Which |
|
| 12:21 | do you find a difference type methods having very regular tech quids. So |
|
| 12:26 | were very common array operations in application at the time. So just try |
|
| 12:32 | pick out things that we're embedded in colts. So and loaded, then |
|
| 12:42 | Zander in the middle column or third and the fourth Column is the number |
|
| 12:49 | bites involved, and this assumes never or 64 bit entities or eight |
|
| 12:57 | So for carpet, you read eight for B and you're right date price |
|
| 13:02 | a So that's your 16 vice now to scale its assumes that the constant |
|
| 13:08 | stored in registers, so that doesn't incur in a memory traffic. And |
|
| 13:14 | only to be in a full still and try that has three year raise |
|
| 13:20 | A, B and C, and that's three times eight bites. So |
|
| 13:24 | 24 bites and then and this list number of floating point operations. Seymour |
|
| 13:32 | Turns out that system is in um, structurally and cold voice. |
|
| 13:38 | simple. But if you want to good performance, it turns out that |
|
| 13:41 | is a challenge for many assistance. how come such a simple things like |
|
| 13:49 | something from memory about reading it in writing it back out? That that's |
|
| 13:55 | to get good performance for? Of , it doesn't do any arithmetic. |
|
| 13:59 | if you go cat arithmetic, there's that you can't get them here, |
|
| 14:05 | for the important performance since you don't anything, but it ought to |
|
| 14:10 | run very well, respect the It's just reading things since streaming it |
|
| 14:14 | and streaming it up right. it turns out to be on. |
|
| 14:20 | why use that, Tom? And come back to that in future lectures |
|
| 14:25 | well. But one of the problems there is no data Regence. So |
|
| 14:33 | of you I'll talk a little bit it. The most are familiar with |
|
| 14:38 | that today's processor all had Josh is . In fact, several levels of |
|
| 14:44 | is, and so that's supposed to you. But it only helps you |
|
| 14:51 | there is data regions. So when no Dana, use everything in |
|
| 14:58 | cash, Meese and then in caches, hurt brother than helps. |
|
| 15:05 | that's one of the part. And is said, um, and that's |
|
| 15:09 | the latest Do you remember the Red . On the previous size graph, |
|
| 15:15 | said You can do about 1000 or South but arithmetic operations for each memory |
|
| 15:24 | or getting the time it takes to to date item out of memory. |
|
| 15:28 | why I got a day to see the problem. Andi, when you |
|
| 15:33 | cash Mrs all the time, then get exposed to the late Inti. |
|
| 15:39 | is a further kind of several the some ways in how caches tend to |
|
| 15:43 | on most processes out there. They something called and right allocate policy. |
|
| 15:50 | what that means is, for each you want to write something. The |
|
| 15:55 | . If it's a cash basis of cash there isn't already in cash, |
|
| 16:01 | it has to read that particular cash from memory first. Then it updates |
|
| 16:07 | cash line, and it writes it . So in that case, |
|
| 16:12 | it's not simply right. It actually and write operations, so that further |
|
| 16:19 | the performance. And then there's is see how the main memories architected that |
|
| 16:26 | cause what's known as the Iran More memory page fault. It's not virtual |
|
| 16:33 | . It's actually has to deal with the the Our memories for main memories |
|
| 16:37 | structured. We'll talk about the horrible the insistence with double date every |
|
| 16:43 | Ah, but it's just at this another that there many issues why things |
|
| 16:48 | hard and here's an example. Just how things may play up. They |
|
| 16:57 | somewhat old processor, I admit I trying to update the slide, but |
|
| 17:01 | didn't manage to find any recent data trust Birthday. These are trust person |
|
| 17:08 | the sense that Ah, each one these data is vetted. I was |
|
| 17:16 | by the vendors themselves. So it's some competing vendor that publishes the number |
|
| 17:20 | somebody else or some themselves and make look bad. But as you can |
|
| 17:26 | , if I look at the bandits this puts stream is trying to measure |
|
| 17:32 | something that is very expensive and very process of that power serious the process |
|
| 17:41 | this case, that part seven. only managed to get 30% of the |
|
| 17:46 | memory. Bandits running the stream bench some not even quite a third. |
|
| 17:53 | of the more vanilla inter processors like In this case, I think it's |
|
| 17:58 | hassle processor than me find so the does quite well, but they have |
|
| 18:05 | in the chip. 10. Circumvent use of cash. That's the way |
|
| 18:11 | got this very good performance of 85% peak. And then the last one |
|
| 18:18 | a couple of example for a digital processor by T. Either I work |
|
| 18:24 | students on for some time, and you just used the vanilla compile C |
|
| 18:30 | for this predictor chip got also less 30%. But if unused, other |
|
| 18:36 | to bypass the chip, then you get close Teoh under percent of memory |
|
| 18:43 | . But it says again, if don't do much, then one should |
|
| 18:48 | expect to get much more than a of the peak member of the memory |
|
| 18:53 | just Vanilla compiled Seiko Here's Justin example what it may look like. And |
|
| 19:00 | think this is, uh, also the assignment website that think they're examples |
|
| 19:09 | addition to on the slides for the . Um, but so in this |
|
| 19:16 | , what, um, stream benchmark said it has all four tests in |
|
| 19:22 | , and it reports the best observed in an average time, but also |
|
| 19:28 | minimum and the next time for running . And it runs each benchmark a |
|
| 19:33 | of times in order to get the . And this is something that we |
|
| 19:41 | against mention and right in the you need to repeat their timings more |
|
| 19:48 | once in the instruction stream. It it for you, but in other |
|
| 19:52 | , they may not be the so you need to repeat things to |
|
| 19:56 | sure you get, um, some well, sensible numbers, because occasional |
|
| 20:04 | happens in the system there fairly So he will not not like to |
|
| 20:09 | the thing time every time. And there are tires and just do it |
|
| 20:14 | you may be on that, can't in one of these out lawyers you |
|
| 20:17 | not trust. Um, here is little bit of example is said on |
|
| 20:25 | first slide off stream that is designed do the main memory performance. And |
|
| 20:32 | why the race sizes needs to be , so that when you run the |
|
| 20:39 | today, I will end up in memory and all the data will be |
|
| 20:43 | . Something memory. But this light is for this peace peace chip from |
|
| 20:49 | Instruments. If they raise our sufficiently that the fit in the cash |
|
| 20:55 | then he'll surprise to get much better . So, as you can see |
|
| 21:00 | the left side of this bar, is from the data fifth in the |
|
| 21:07 | one cache and you run it for L one cache. Ah, you |
|
| 21:12 | in this case 120 gigabytes per second this particular chip for a copy and |
|
| 21:18 | and not quite the same s o the other ones. And I'm not |
|
| 21:23 | in tow wine. So the point this, slightest, essentially, to |
|
| 21:27 | you what happens as data and gets further away in some sense from the |
|
| 21:36 | . And then there's in the You have things with little, |
|
| 21:39 | whether it's hit their mission. Level . And if you go towards the |
|
| 21:44 | inside still very low one and one little ones. That is significant. |
|
| 21:51 | happens when you run effectively stream. , naively on. And in that |
|
| 21:59 | , you get Mrs In. Both one and l two cache is and |
|
| 22:04 | what they have on this chip. no a three cash level three cache |
|
| 22:08 | that particular chip. So this is thinks Mrs all the time, which |
|
| 22:13 | typical for ST and the right inside post. The bargain toe the right |
|
| 22:21 | stood there right, is when you're using the cash and manage data so |
|
| 22:28 | your own. But as you can in this case, it's about more |
|
| 22:34 | a factor of 10 difference. The the best way of managing data and |
|
| 22:40 | one. And it's even much worse it comes to Navy using no see |
|
| 22:48 | for stream and the best scenario in with a that close to the |
|
| 22:57 | the guts benchmark. It's also memory , but it's actually a benchmark that |
|
| 23:04 | much more tuned to trying to capture application or what or the behavior of |
|
| 23:11 | applications are more dominating today. Run date I accesses are not very nicely |
|
| 23:19 | , and it's jumping around quite a . And main memory eso, the |
|
| 23:28 | benchmark, is walking through memory and doubly. So what? This kind |
|
| 23:35 | graphs basically shows you kind of a . If you look at the left |
|
| 23:40 | graph in particular, Uh, that that basically, if they raise gets |
|
| 23:47 | , ah, and first to have cash behavior there may be in |
|
| 23:54 | But then, once you drop out the different levels of passion, eventually |
|
| 23:58 | end up in Maine memory black on other, these peace line that showed |
|
| 24:03 | and the performance dropped significantly what you noticed when you do your assignment? |
|
| 24:12 | ihsaa. Not only do you see same drop in performance as things and |
|
| 24:19 | gets further further away from the processor the main memory, but that the |
|
| 24:25 | access behavior is so performance is much . They may be more than an |
|
| 24:33 | of magnitude and maybe two orders of lower then if you have regular |
|
| 24:40 | So that's why these two benchmark money a said. The best case. |
|
| 24:46 | it's not the worst case, but is kind of more trying to capture |
|
| 24:51 | typical application than the worst case being . And certainly not to this |
|
| 24:58 | a little bit off some words about guts benchmark and the next time you |
|
| 25:05 | show what it actually does. But the same thing again. The age |
|
| 25:10 | should be large enough that they recites main memory to properly assessed a main |
|
| 25:17 | system. And it also points out real and is structured as a real |
|
| 25:23 | right, and I think that's maybe soon on this particular slide. So |
|
| 25:28 | done as a 64 bit work and then it grand demises the addresses |
|
| 25:37 | are used for stepping through the memory updating the value at that location and |
|
| 25:47 | it back and then getting random is another address. And this is kind |
|
| 25:54 | the scheme they don't have. I plan to go through exactly. The |
|
| 25:59 | budget can control exactly how you randomize access to it and how this step |
|
| 26:06 | the memory. So this is just function. Ah, like copy scale |
|
| 26:11 | sector. So it just randomly updates locations. And, um, |
|
| 26:22 | it was also like it is single benchmark, but has also been |
|
| 26:29 | Teoh, we must have processes, this is pretty much saying but I |
|
| 26:34 | before and there is a little called and I think they're called examples again |
|
| 26:45 | the power cord wraps either. So have put their So here's a little |
|
| 26:54 | so yes, this So what? doesn't directed airport the bandit that you |
|
| 27:03 | . Um, so you have one to get a little bit of do |
|
| 27:07 | little bit of work to figure out the actual bandwidth is that you get |
|
| 27:12 | it reports the time it takes to the updates. But the benchmark is |
|
| 27:21 | eight byte data types. So you how many up this has happened? |
|
| 27:28 | know, the number of bytes for update, and that in involves both |
|
| 27:35 | in a store. And so it data that means 16 vice for each |
|
| 27:40 | you update something and then you have time. So since you know the |
|
| 27:45 | of ice and you know the you can figure out what the Ben |
|
| 27:50 | this in terms of bicycle second. this is the way than you can |
|
| 27:54 | it to the stream benchmarks. Because know no r t convert time in |
|
| 28:01 | per second. This is the third you're supposed to do, and the |
|
| 28:10 | is an acronym for ah, very library function that is, in most |
|
| 28:22 | , mad flavor. Is there also domain libraries and stands for double position |
|
| 28:29 | the D and D for general Matrix . So it's and it's, |
|
| 28:38 | also it what's known as it dens multiplication. So that means it's a |
|
| 28:45 | that has enters in every room column every rope somewhere, and what it |
|
| 28:52 | is simply do you matrix product on scale is for the person off a |
|
| 28:59 | constant and then is a Times B as it to another Matrix C. |
|
| 29:09 | yes, the typical free nous it and most the gym implication. Just |
|
| 29:18 | what's typically No, no saying a algorithm, and we'll talk more about |
|
| 29:22 | later. But just for now, it is standard matrix multiplication, no |
|
| 29:30 | multiplication. And the reason for including , it's is that when the cold |
|
| 29:40 | well structured, this cold ends up CPU limited throughout the memory bandwidth. |
|
| 29:48 | something other to workers says the memory for, you know, best case |
|
| 29:53 | and more typical access. And this to assess the compute capability small in |
|
| 29:59 | memory system. Oh, you and against Here's a little bit just |
|
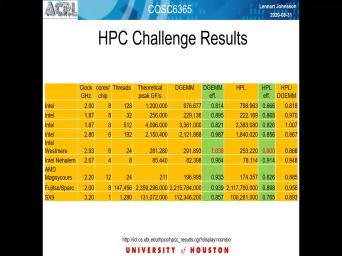
| 30:07 | example of it and it Time. I think the cesium benchmarking and computes |
|
| 30:13 | number of floating point operations per Ah, it produces. And this |
|
| 30:23 | is again a little bit old. , the point is off in the |
|
| 30:31 | on this sliders In column This is , Andy, Jim Efficiency and, |
|
| 30:41 | , I for this particular test, r. Simon. The interesting part |
|
| 30:49 | the green Dejan column. This is gym efficiency that shows the fraction off |
|
| 30:56 | performance that Ah was there something from the benchmark? And this comes from |
|
| 31:03 | HBC Challenge benchmark site and have Israel the bottom. And it's, |
|
| 31:10 | shows you the for a number of processors, you can get 90% of |
|
| 31:19 | . And as the red one here's you can even get more than |
|
| 31:24 | out of the processor, which is there. Not true, and we'll |
|
| 31:32 | more about. The reason for that the reason is, most of the |
|
| 31:35 | when people run this benchmark, they look the clock frequency of the |
|
| 31:44 | And then when the report the efficiency that is based on the capability of |
|
| 31:53 | chip, they used a normal frequency not the actual car frequency used when |
|
| 32:00 | benchmark was run. So that's why you have processes that have turbo mode |
|
| 32:06 | is dynamically controlled, in fact, processor may have run that the higher |
|
| 32:13 | rate, then the actual ah nominal clock great published. So in that |
|
| 32:20 | , you actually have the higher capability this chip them, the one you |
|
| 32:25 | infer from the highest published nominal conference terrible So, um and in your |
|
| 32:38 | you will run things without, um able or lasting there. Clark rate |
|
| 32:47 | the processor so you don't? In , no, you can actually. |
|
| 32:52 | , um, query the processor. can see what conference has actually been |
|
| 32:58 | . A supposed it an Amilcar and then you could do a better |
|
| 33:01 | . But otherwise is good enough for assignment. That computer efficiency based on |
|
| 33:07 | , they non terrible mold. Highest . All right, so I was |
|
| 33:18 | for a second and ask if there questions related to the benchmarks or the |
|
| 33:24 | one. Oh, see? I see in the race hands. I |
|
| 33:49 | know. If so, you should in the race stands. No. |
|
| 34:04 | , yes. Can you confirm to verbally. So Okay, I will |
|
| 34:24 | then. All right. Um, the next topic today was these roof |
|
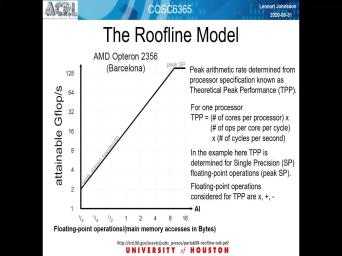
| 34:39 | model, and I was already or model that waas, um, |
|
| 34:49 | forward by Dinklage UC Berkeley. and that's can put about popularity as |
|
| 34:56 | way of find to capture, what may be limiting your performance and |
|
| 35:08 | , um, typical so years with lawyer. And this is a reason |
|
| 35:16 | calling it the roof line model. , so is this two lines and |
|
| 35:22 | line to the left like and then roof, the horizontal line towards the |
|
| 35:33 | . And what is the capabilities on vertical axis? And in our |
|
| 35:40 | will like when they proposals of them talked about it, too. They |
|
| 35:45 | kind of focused on floating point, they could as well be integer operations |
|
| 35:50 | any upper other operations functional off the unit that you're interested in and horizontal |
|
| 35:59 | on something that then trying to relate work that is, ah, the |
|
| 36:08 | for the vertical access relative to the references used. So the athletic intensity |
|
| 36:18 | our cases will be the number of point operations per bite off memory |
|
| 36:26 | So underlying this model is this cartoonish with a processor and memory, and |
|
| 36:32 | most systems has pointed out before is the memory system tends to be the |
|
| 36:38 | part. So that's what one get behavior. So when there's a lot |
|
| 36:45 | arithmetic in this case for a bite some point, the functional units in |
|
| 36:52 | process of will be the limiting not the memory system, But if |
|
| 36:57 | don't have many arithmetic operations, poor reference, then the memory system is |
|
| 37:04 | limit. So that's kind of what and I'll for a little bit more |
|
| 37:12 | they tell about this to flame along next several sites. So here is |
|
| 37:19 | over the arithmetic intensity and for some . So start from the left side |
|
| 37:31 | , where the things that are not that has a lot of memory |
|
| 37:37 | Typically, for each arithmetic operation so matrix rectum application is going away towards |
|
| 37:48 | left. I'll come back to that a second, and then it says |
|
| 37:53 | . Blast one and two and the stands for basic linear algebra subroutine that |
|
| 38:01 | step someone. You may be but it's not. It's essential in |
|
| 38:07 | algebra operations and the number afterwards. and three on the note. The |
|
| 38:15 | of nested loops. So coming back D. M in the Matrix multiply |
|
| 38:19 | talked about it has three nested so that's about three routine. It's |
|
| 38:27 | matrix vector multiplication. On the other , they are Ah yes, I |
|
| 38:35 | first go back to talk about blast a matrix vector multiplication is a |
|
| 38:39 | Two. Ah, it has two loops. You know, one going |
|
| 38:44 | columns of ongoing over Rose and last is things like We're in Stream one |
|
| 38:53 | copy scale some. Or try There's just one nested look. That's |
|
| 38:59 | blast. One Function with the Stream . Things are fairly simple in the |
|
| 39:06 | that you just incrementally and wrestle. , sits them step through memory in |
|
| 39:13 | very nice and orderly fashion, whereas not to put it to when you |
|
| 39:19 | a sports matrix. And in some , somebody doesn't know what this portion |
|
| 39:24 | . There's a matrix that mostly have in it, and if you non |
|
| 39:28 | interests on since there's mostly zeros, too expensive to store all therefore |
|
| 39:36 | But all the zeros someone only The non zero elements are a few |
|
| 39:42 | elements that happens to be zero. that means you get the much more |
|
| 39:48 | structure to access the data, then increment by one or a some increment |
|
| 39:53 | your fixed, um, distance to next element. So that's why it's |
|
| 39:58 | lot of address calculations and other things on when it is forced matrix vector |
|
| 40:07 | fast. Fourier transforms maybe against when get to some of you on. |
|
| 40:12 | you're familiar with it, it's one these in log and arithmetic complexity |
|
| 40:19 | So over data set besides end so with log and operations for data element |
|
| 40:25 | average. And then it comes to that then takes multiply. Case that |
|
| 40:33 | for well written cold should be Lemme limited for decent matrix ice is |
|
| 40:39 | there are on average at these and for data I. So this is |
|
| 40:47 | of the idea about the arithmetic So this is again when you know |
|
| 40:53 | about your application and you know the that you have. So then you |
|
| 40:59 | necessity arithmetic intensity off your application. then you can make a judgment as |
|
| 41:07 | whether it's likely to be limited by memory system or by the processors. |
|
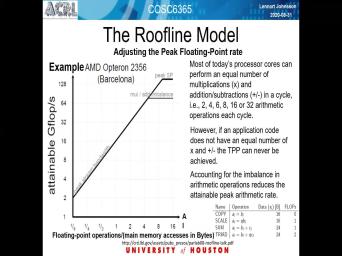
| 41:17 | . So here is a little bit detail. Examples alarm on can refine |
|
| 41:24 | most naive version off the roof line . Um, so, uh, |
|
| 41:31 | just pointed out, I guess, stream here. So in terms of |
|
| 41:35 | looked at stream in terms of the off floating point operations, um, |
|
| 41:40 | memory reference or per bite, clearly no nothing. So, basically, |
|
| 41:48 | intensity zeros has weight to the totally limited by the memory system. |
|
| 41:55 | , the scale version is somewhat but it's basically one operation for every |
|
| 42:01 | bytes so still kind of to the of where this actually graph starch. |
|
| 42:07 | then even in terms of the it is even to the left of |
|
| 42:13 | graph. So those are again assessing memory system. And as you can |
|
| 42:20 | , um, on this slanted perv this graph and says p extreme memory |
|
| 42:27 | . So this is something that you play with in terms of increasing arithmetic |
|
| 42:32 | , uh, to get this But the gym, On the other |
|
| 42:36 | , this has said from the previous , uh, well, rating |
|
| 42:41 | You should be able to exploit that has, on average and arithmetic operations |
|
| 42:47 | data item. In that case, becomes, um, limited by the |
|
| 42:56 | capabilities. So in the assignment you , ask Teoh, think you need |
|
| 43:04 | compute that lists. If the theoretical performance on it's a fairly simple one |
|
| 43:11 | do on certain on the process of . And if you have more than |
|
| 43:16 | processor, you can just multiply by number of processes. But the way |
|
| 43:20 | do it, it's simple you You can start with the number, |
|
| 43:26 | course for processor on, and then have the number operations, Precor per |
|
| 43:33 | . In our cases, the floating operations Ah, for the D Jim |
|
| 43:37 | taken do for a core, and the product of that gives you the |
|
| 43:44 | off the chip or the processor. then you have the clock right in |
|
| 43:50 | cycles per second, so that eventually to the total number off operations for |
|
| 43:59 | second for processor. So that's a peak performance, and this HPC challenge |
|
| 44:07 | of Ah, I told you before that if you use this number as |
|
| 44:14 | reference point for Huggel, your code then a good major response. If |
|
| 44:20 | can get 90 plus percent on the performance, Um, no. For |
|
| 44:31 | processes like the Intel processors and X also by Andy, they tend to |
|
| 44:39 | the capabilities. Single position ops is the number off, seeing double position |
|
| 44:49 | for a second, so one has pay attention to the data type. |
|
| 44:52 | gonna figure out what the number of for cycle, yes and typical once |
|
| 45:01 | . And that's, uh, in benchmark you're doing. That's nothing else |
|
| 45:07 | on then and subtracting multiplication so those things, and obviously fairly common, |
|
| 45:16 | division. But the division is a operation, and it's not. One |
|
| 45:23 | not normally counted as equivalent to and most apply or subtract. Um, |
|
| 45:35 | this comment is already on in terms the terrible Bold. Now, when |
|
| 45:44 | comes to modern processors, waltz are . You had soul. When one |
|
| 45:50 | at the big arithmetic rate in terms floating point, a swell, as |
|
| 45:58 | figures, it is that most of architectures today they are so called fused |
|
| 46:06 | of lie and architectures. That means a single instruction they can do golden |
|
| 46:16 | define and o. R. They do a number of pairs about the |
|
| 46:20 | in ads. So for the peak important rate, money soon's ah, |
|
| 46:29 | gets that by the capability or so both ends and multiply at the same |
|
| 46:39 | . So that's and now the process today depends on the vendor and this |
|
| 46:46 | you have got. Some of them do up to 32 arithmetic instructions per |
|
| 46:53 | per cycle. Oh, yeah, , even more. But so this |
|
| 47:00 | But if you're cold doesn't have it combination are as a multiplies, then |
|
| 47:11 | cannot achieve it. And they have appear in a way where they can |
|
| 47:15 | carried out concurrently, even if the number happens to be equal between |
|
| 47:20 | subtract and mom petition if they're um, organized in a way that |
|
| 47:27 | be carried out correctly concurrently than you lose, your actual possible peak is |
|
| 47:34 | equal to the theoretical peak. And we noticed for you know, this |
|
| 47:39 | Ah, stream benchmark. It only a multiply. So that means the |
|
| 47:43 | performance for doing scale is at most Oh, the theoretical peak performance in |
|
| 47:49 | same for some, on the other , for try. And it has |
|
| 47:53 | balance number and some of applications. , no, On top of |
|
| 48:03 | there is, um, the cycle scaler capability of Cindy capabilities or modern |
|
| 48:14 | modern processors. The has many functional , um, in the same core |
|
| 48:25 | it's not just that there many you have many function with units of |
|
| 48:28 | same kind and given the same So this is known as the very |
|
| 48:35 | in instruction word feel like W which is more general than Cindy. |
|
| 48:43 | for single instruction, multiple data. we will talk about these particular form |
|
| 48:49 | processor architectures much later, but this just for the roof. I'm always |
|
| 48:55 | to point out that money's to take things into account, because if the |
|
| 49:00 | is such that you cannot exploit the that or use multiple functional units because |
|
| 49:07 | logic convict cold is not conducive then the peak for your cold is |
|
| 49:15 | even as good as the theoretical peak even there taking a continent in balance |
|
| 49:22 | the ads and multiply so just downgraded . And then there is yet another |
|
| 49:30 | that is known as instruction level That is kind of try it |
|
| 49:36 | um, capture the fact that, , the compiler or the architected does |
|
| 49:44 | compiler, and the application does not you to, For instance, use |
|
| 49:50 | store units to remain memory concurrently is functional units in the processor soul. |
|
| 49:57 | lose additional because things get serialized. supposed to being done concurrently. So |
|
| 50:03 | instruction level parentless. So there's from ideal peeking from one monster. Use |
|
| 50:12 | roof line miles carefully. Then one to and try to get an |
|
| 50:20 | Oh, capabilities. All the architect for a particular code one needs to |
|
| 50:27 | insights into the coat this much as architect as well, no coming back |
|
| 50:38 | the stream. So now, in of this sloping line, has a |
|
| 50:43 | . That's the ideal thing. As mentioned, Stream is very latest and |
|
| 50:48 | sensitive. So if one doesn't have pre fetching, then there will be |
|
| 50:58 | , Mrs all the time and the Mrs Incur Wait time. So |
|
| 51:06 | in fact, the memory bandwidth you achieve is then much slower than if |
|
| 51:16 | are properly prefect. Um, the things, which also degrades memory system |
|
| 51:26 | potentially is the fact that again we'll more about this later on. But |
|
| 51:34 | servers or custom molds, they are or four socket, mostly two sockets |
|
| 51:43 | . That means there is an old off, has two processors or for |
|
| 51:51 | on the same circuit board and in , that is is kind of a |
|
| 51:58 | memory unit. So it means ever processor can access any piece of |
|
| 52:06 | But physically the memory is it's attached parts to each one of the process |
|
| 52:13 | so effectively each sock it. It's surgery associated with a certain amount of |
|
| 52:21 | . And if and you can easily and have the other space for the |
|
| 52:28 | associated with the processor in another but in order to access it, |
|
| 52:36 | kind of further away. So the to access data that lives in some |
|
| 52:42 | processor's memory on this in the same is lower. So this is known |
|
| 52:50 | a non uniform memory access ah system there ways to try to optimize the |
|
| 52:58 | for that. But if you but regardless, it does the great |
|
| 53:04 | a bit. So that's why it's starting with the best scenario for stream |
|
| 53:09 | , pre fetching the great. If doesn't work properly, this non uniform |
|
| 53:15 | access planning for the the greats, peak possible memory bandwidth and then Assis |
|
| 53:26 | here, as that stream is designed stepping through memory from one others to |
|
| 53:32 | next, which is ideal for the that memory systems are designed. But |
|
| 53:39 | that's not your application, so you much larger distances in addresses between successive |
|
| 53:47 | accesses, their performance degrades. more on here is just a slight |
|
| 53:57 | you figure out since you're asked to that. How you figure out the |
|
| 54:02 | peak memory bandwidth and, um, brisket tell. So you need to |
|
| 54:13 | then and figure out on that you get from query. The processor configuration |
|
| 54:19 | that things should tell you how many channels there are on the processor. |
|
| 54:24 | it's not, you might have to take the process of model number and |
|
| 54:28 | it up on the Web. for inter process is very easy to |
|
| 54:33 | him in it. Memory channels each has. So that's an easy number |
|
| 54:38 | find. Ah, when it comes all them the process you're going to |
|
| 54:44 | Ah, Sky Lake or bridges. from Simon, one, uh, |
|
| 54:51 | Channel. It is eight bytes so that's very easy to figure |
|
| 54:54 | Come in a bisque, return on hand. It wants Apply it to |
|
| 54:58 | the total number of ice bear clock you can do And then you have |
|
| 55:02 | again. Multiply it by the Great off the memory thus that you |
|
| 55:10 | . Yes, indeed. Er that's main memory on it says on the |
|
| 55:18 | you can use this what you get acquiring the process of what kind of |
|
| 55:23 | attached to it. Uh, that when there's okay, remember, Probably |
|
| 55:30 | or something Do they are memory and I see that the clock frequencies |
|
| 55:36 | um, megahertz ons only a Then come, Burke is, and |
|
| 55:44 | you have to multiply it. But two, because, oh, the |
|
| 55:50 | that double the d the arms in sense, with double data it |
|
| 55:54 | So it transfers data twice every clock . So that's why you have the |
|
| 56:01 | two. And then there is a here that says, Well, |
|
| 56:06 | life, It may not quite work way, but for the moment, |
|
| 56:10 | is good enough. When I talk memory system, I will talk more |
|
| 56:14 | but actually goes up. So this just the summaries line of what I |
|
| 56:21 | said and this Is that a couple Jesus that may be worth watching? |
|
| 56:29 | is from again. The Stream designer McAlpin gave the taka the supercomputing conference |
|
| 56:38 | years ago. This remember? That's nice talk is a nice video. |
|
| 56:42 | 1st 14 minutes is about history of . You know, if you don't |
|
| 56:48 | time, skip but the remainder, , 30 minutes is good, |
|
| 56:55 | background, too, by member assistance and why he created the stream benchmarks |
|
| 57:01 | what to expect going forward and in latter concepts, waas to expect conformity |
|
| 57:08 | justify much of what's being talked. this course, the during award electrified |
|
| 57:15 | Hennes inject the Paterson, they also worth watching. So now the here's |
|
| 57:22 | bunch of references. On the next , it would be the bugging. |
|
| 57:30 | , um, I'll stop for a before a change topic to be bugging |
|
| 57:37 | DSI if there are questions. So asked the National. So that's so |
|
| 57:50 | much time do you want the I think that Emma is probably smells |
|
| 57:56 | the sights I would privatize that you enough time, and then now you |
|
| 58:01 | it's it's fairly short. So maybe to 15 minutes. Okay, I'll |
|
| 58:06 | about five minutes in and then, , about debugging and then give it |
|
| 58:17 | you. So the helpful it cites fairly self explanatory predicted together with a |
|
| 58:31 | . But eso said before so the of this debugging slices Really yes. |
|
| 58:37 | , uh, get you too. some good tools instead of print f |
|
| 58:43 | trying to debug your coat. so, uh, if anybody didn't |
|
| 58:53 | , it was the slight actually Where does the notional debunk and come |
|
| 58:57 | ? Well, it came from Grace Hopper that some of you may no |
|
| 59:05 | she was became a very well known scientists computer programmer on She is the |
|
| 59:13 | that also gave raised to the great conferences Serious but yes, in the |
|
| 59:22 | days and computing when things were based relay machines, see, they discovered |
|
| 59:28 | problem and see and figure out what problem was. In that case, |
|
| 59:32 | was Ariel physical, but so, , they found in this one related |
|
| 59:41 | Miss function so ever since then, to clean up cold and makes them |
|
| 59:46 | , simply known as the bug. there's just if you slice is said |
|
| 59:52 | be effective. One really needs to good tools. Course if it's a |
|
| 59:58 | simple cold, a few lines, know, 10. 15 lines of |
|
| 60:02 | , then very simple tools like Definitely do the job when you come |
|
| 60:08 | . Conflicts coast with thousands of tens thousands or even hundreds of thousands of |
|
| 60:12 | of code, New Problem is something more powerful than free death. And |
|
| 60:20 | was just a little bit two business for presentation. But it's kind of |
|
| 60:26 | , since I don't have a book reading, no pistol points out. |
|
| 60:31 | the buggers do the debunkers best. is a wave to tell the compiler |
|
| 60:39 | keep enough information around that. You then use information where things goes wrong |
|
| 60:47 | your code, potentially or these. for things happened at various stages in |
|
| 60:51 | coat and a map it to or it to your text that you have |
|
| 60:59 | C cold or for turning colder whatever cold you're using. But it's the |
|
| 61:04 | you to do basically understand where things a little bit fishy in terms of |
|
| 61:10 | source code. Um, so and is true that. Just think the |
|
| 61:20 | in a perfect because when you use bugging modes on the compiler, then |
|
| 61:26 | not necessarily exactly the same, but still must false it, too. |
|
| 61:31 | execute herbal cold that they would do a non Bagnall than using print after |
|
| 61:36 | drink dolphins as instructions and the memory allocations and the lots of different |
|
| 61:42 | all when you use print, tough may work fine. And then you |
|
| 61:46 | print F in this team doesn't and they liked it for that to |
|
| 61:51 | . It's much less money, you brother. Um, so this is |
|
| 61:57 | thing? Where they said on here a bunch, don't think. |
|
| 62:02 | and cars used to use a The bugger gtb. And there's a |
|
| 62:07 | of their million very good tools after , you know, Intel us. |
|
| 62:13 | good tools for a little bit more on TV. The bugger and soldiers |
|
| 62:18 | for their platforms and about their ties to the compilers that you're using. |
|
| 62:25 | I think with that I was, but, uh, now flip through |
|
| 62:31 | just for you to know what's in slide deck, and then I Let's |
|
| 62:36 | . Yash, um, did the . So this is just to tell |
|
| 62:42 | what again when you used a d Moder completely keeps enough information that you |
|
| 62:48 | link things, uh, from, know, address in memory to source |
|
| 62:55 | . And, uh, here's the things and I think again suggests will |
|
| 63:02 | to some of these. And then is, if you really naive examples |
|
| 63:07 | one and some more time I let ask a question of figure was wrong |
|
| 63:14 | this one. Hopefully, you can it in vigil if you look at |
|
| 63:17 | these cold. But the program and what the loop does is not |
|
| 63:22 | compatible. And the next few um, that you see exactly in |
|
| 63:29 | various things what happens so you can a little bit simulation for yourself, |
|
| 63:34 | through this line and figure out musical , and then what 50 bugger tells |
|
| 63:40 | in return to your input to the bugger, what goes on on |
|
| 63:46 | is another example that is a little not very much more nimble, but |
|
| 63:52 | lived more in. So I think stop for that. Ah, |
|
| 63:59 | And, uh, this is that sophisticated the buggers. But this case |
|
| 64:05 | just for this course, just trying get to used to use the buggers |
|
| 64:11 | the good way without going into all nice feature. Something up. So |
|
| 64:17 | , this is Well, then get continue from here. And I should |
|
| 64:27 | sharing my screen. And on you should be able to share your |
|
| 64:36 | . Can everyone see my screen? . Okay. All right. So |
|
| 64:44 | is gonna be a quick demo on to use the D burger. That's |
|
| 64:50 | G D. B. That's from N U, which is most widely |
|
| 64:55 | . And it's an open source deep uh, so as you can see |
|
| 65:01 | the screen, there's a there's a . So I stopped for 30 seconds |
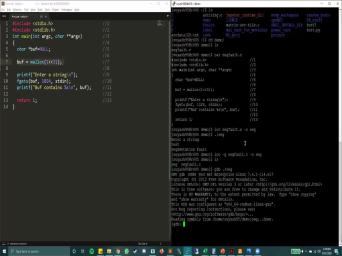
|
| 65:06 | that you guys look at it and trying to see what might be the |
|
| 65:10 | . But this code And then we go on But the debugging demo. |
|
| 65:17 | of course, anyone that happens to it within the 30 seconds or so |
|
| 65:22 | us amused herself. Intelligence. So anyone that the buffer smaller in |
|
| 66:00 | amount that you requested to read for , you've been here? Yeah, |
|
| 66:08 | , that's that's the amount off. the number off bites that gets is |
|
| 66:15 | to get. So that will be input size that you will give. |
|
| 66:21 | no, that's not going to be issue that's does the size of the |
|
| 66:27 | that gets will expect and will assign to buffer here, which will be |
|
| 66:36 | the memory here. That's okay. , let's let's start with it. |
|
| 66:46 | let's so first thing Teoh notice here this time I'm gonna compute Note. |
|
| 66:53 | don't do anything on Logan. Note , just to remind everyone, |
|
| 66:59 | I have the same court again So now let's go ahead and just |
|
| 67:06 | compile it. Using the intel compilers I'm using, i c. C |
|
| 67:11 | of GCC, you can use our as well. It's not going to |
|
| 67:15 | much difference in a piece for this here, so we've combined it and |
|
| 67:21 | go ahead and run it. So asking for, uh, just a |
|
| 67:26 | or anything. So let's just give thean food what's going to happen. |
|
| 67:32 | gives out a segmentation fault. if you just put in a bunch |
|
| 67:38 | print hips and try to get try print values of each of the variables |
|
| 67:43 | you have included according to be a cumbersome process. And if you |
|
| 67:47 | let's say, 2000 or 3000 or much larger code that has more than |
|
| 67:53 | lines. You don't want to put absolutely there, and that's going to |
|
| 67:58 | it's going to take a lot of to depart. In such case, |
|
| 68:02 | can use the D burger and how do that. It's simply what you |
|
| 68:08 | do is you would write your a command again, but this time you |
|
| 68:13 | a hyphen G flag when compiling the . Now, what's that? What |
|
| 68:18 | going to do is in normal can when you when you compile the court |
|
| 68:25 | any compiler, lots off meta data deleted that that is not required for |
|
| 68:33 | execution off your core. When you it with a hyphen G flag, |
|
| 68:38 | keeps the gifts that matter later, that allows you to use the deep |
|
| 68:44 | , which will lead that meta data you debug your program. When you |
|
| 68:51 | that using my hyphen G flag, finish normally and as you can see |
|
| 68:57 | are you can have another execute herbal , this time, instead of just |
|
| 69:03 | running the executable directly. What you want to do is run it using |
|
| 69:08 | GED. Become from Julie Rea deeper I'm jdb and just give your executable |
|
| 69:16 | Thean foot of that was was that to do is it's going to open |
|
| 69:21 | GED, be consul now the first when you do that you would want |
|
| 69:27 | just simply run your court and let what's going on. So if you |
|
| 69:33 | that, you can simply use the of run, and before that, |
|
| 69:37 | just go ahead and show you all different commands that you can use. |
|
| 69:41 | dive, help. You can see kind of different glasses, off |
|
| 69:46 | And if you, if you just , let's help break points, which |
|
| 69:52 | one of the classes off commands It will give you all the commands |
|
| 69:58 | you can use in the in the point category. Now, as I |
|
| 70:05 | , let's go ahead and use the command that we're going to see. |
|
| 70:08 | the run command with just which would normally run your program. As you |
|
| 70:13 | see again, you will see that asking for a string. It's |
|
| 70:18 | Go ahead and give an input That's a test and press enter and |
|
| 70:23 | . Now we have again received the fall. Now the next step you |
|
| 70:29 | want to do is you would want see where you are exactly getting the |
|
| 70:34 | fold and again. As I if you have a really large covered |
|
| 70:38 | than 1000 lines, of course you want to go ahead and just trace |
|
| 70:42 | manually where the cold weather the terrorist . So in this case, you |
|
| 70:47 | simply use the command called factories. when you when you enter that it |
|
| 70:55 | tell you exactly where the where the occurred. So that happened at several |
|
| 71:00 | fault dot C and online number of . So let's go ahead and see |
|
| 71:05 | online number 10. We see there's issue with this statement. No. |
|
| 71:12 | normal cases, you can assume that library definitions off functions such as it |
|
| 71:20 | , or any variables that are defined the luxuries, like a study in |
|
| 71:27 | should be working for him in normal unless somebody messed up while installing his |
|
| 71:33 | or compilers on the cluster. But everything's fine, we can safely assume |
|
| 71:38 | these two things don't have any issue what you would want to do. |
|
| 71:47 | you have a large court, you want to again go ahead and see |
|
| 71:51 | court again. What you can simply is use the command frame and give |
|
| 71:57 | frame number that's at the That's at error point in your code as the |
|
| 72:04 | did that. Come on. What that going to do is it's going |
|
| 72:07 | tell you exactly the statement that gave the error. So there are again |
|
| 72:12 | ways of checking for the record. , as I said, we can |
|
| 72:19 | have gets an STD in may not any issue. So let's check what |
|
| 72:24 | buff pointer is containing. So as expect, a buff should contain a |
|
| 72:31 | address because it is a pointer and allocating some memory to that point of |
|
| 72:37 | . If everything worked fine, it have a good point to a memory |
|
| 72:41 | in the memory. So if you to see what's contained in that very |
|
| 72:46 | . Just use the command print That's a duty, Beekman. And |
|
| 72:51 | give Buff as the barometer toe Now . As I said, we would |
|
| 72:56 | it to have a memory address. let's see. So, as you |
|
| 73:01 | see, Buff here is containing zero zero on Exodus. Simatovic is the |
|
| 73:08 | for no and which is not a thing because we want addictive point to |
|
| 73:15 | memory address. So now let's make that Matlock is not malfunctioning because that's |
|
| 73:24 | was the one assigning valued above. what we can do is here, |
|
| 73:29 | , we're gonna kill this program using pill Common Press. Why now? |
|
| 73:36 | we're going to do is we're gonna a break point here at line number |
|
| 73:41 | where Melo was assigning some address The way you can do that is |
|
| 73:48 | using simply the command called Break Give name four years, so scored |
|
| 73:55 | not the executable, remember? And the line number where you want to |
|
| 74:02 | the break point out when you do , GDP will tell you that when |
|
| 74:07 | break point was added at at this line in this source code fighting |
|
| 74:14 | You don't need to re compile your because Jdb already has the metadata. |
|
| 74:20 | . It knows what's which machine code . The line seven in your source |
|
| 74:27 | sort of. Once you have set a great point, let's go ahead |
|
| 74:31 | run the program again. So the for So as soon as we run |
|
| 74:36 | program, it got to the break and it stopped the execution at that |
|
| 74:42 | . Now let's see what the buff here. So again, we see |
|
| 74:49 | buff is condemning the value of Rich not have bean because Matt Look should |
|
| 74:54 | resigned it an address with an address now, if you go and look |
|
| 75:01 | the Maalox documentation, it gives it another value only when it cannot assign |
|
| 75:09 | amount of memory that you are requesting I'm not going to show the exact |
|
| 75:15 | . Facebook. You can go ahead look for my locks. Documentation. |
|
| 75:21 | can anybody tell me what's this much off memory is en gigabytes or |
|
| 75:30 | Just a quick question. So it's matter of one first 31 or something |
|
| 75:37 | those lines, right? So it's power 31 which equals two gigabytes of |
|
| 75:43 | . Uh, which seems quite a . So how about we give it |
|
| 75:49 | less amount off memory? So let's ahead and kill jdb here. |
|
| 75:56 | come out sec for dot c. say we give it I say to |
|
| 76:05 | job rather than gigabytes. Let's trying give it a two megabytes of |
|
| 76:13 | Let's tell him, Compile it This time, when you run |
|
| 76:25 | it will give the right off. as you can see it, using |
|
| 76:31 | such a deep of air and using a look, a man's trying to |
|
| 76:34 | what were the errors occurring and seeing variables are at that point, what |
|
| 76:41 | values are. You can easily pinpoint issues in your in your program. |
|
| 76:49 | there are, As I said, are quite a lot off commands that |
|
| 76:54 | can use, but you d be the simplest combined, as I said |
|
| 77:00 | can use, is run. Run cold. There is another command called |
|
| 77:08 | . Ah, hang on. So us introduce that can, right? |
|
| 77:37 | the list command what it does it going to show you a few lines |
|
| 77:43 | on the the statement where you got error. So again? Yes, |
|
| 77:49 | to the other commander. I showed like the frame number, the |
|
| 77:54 | You can use this list command to where the edit occurred because I showed |
|
| 78:00 | here you can also use Come on the Julie Be console to see all |
|
| 78:06 | of different about commands that are But Judy Bee, let's go out |
|
| 78:12 | again. See what commands. They break points so you can see simple |
|
| 78:17 | Come on command, which sets a point. You can delete existing great |
|
| 78:23 | . You can disable the break There are conditional break points that you |
|
| 78:28 | , so you can specify a And then you can assign that condition |
|
| 78:31 | your break point, which, if want to do some advance developing, |
|
| 78:36 | will be very useful to you so can follow us like simple workflow. |
|
| 78:54 | pinpoint what the others are in your . Just trying to explore more commands |
|
| 79:02 | Yeah, that's pretty much it. questions from anyone? Do you know |
|
| 79:12 | it's possible to use remote the bugger your own I D or we stuck |
|
| 79:15 | think The command line interface? you mean as in remote river having |
|
| 79:26 | . Could you repeat yourself? I'm sure. What do you mean by |
|
| 79:30 | ? Deeper. Um, I think think we get chatter applying them. |
|
| 79:35 | . I suppose for a little Okay. Any other questions? |
|
| 79:53 | Thank you. Stop shooting. I have a question for me |
|
| 80:08 | No, just number. Could be questions. Does the US have office |
|
| 80:14 | or the on a per appointment bases the syllabus of TBD right now? |
|
| 80:22 | , I haven't decided on that but if you want to have a |
|
| 80:28 | and get on a call sometime, so good. Yeah, who are |
|
| 80:32 | doing email? Okay, we can on the time. Maybe it's a |
|
| 80:41 | toe, even though you may be based on email agreements. But Mamie |
|
| 80:51 | may be useful to have it six slot if people can think of in |
|
| 80:57 | of planning their own time. The else send out a slope was |
|
| 81:05 | okay. Anything else? I was trouble getting the video points home to |
|
| 81:17 | at the recordings. The link to just times that I will never takes |
|
| 81:22 | anywhere. I are. You try users, you wage Logan. |
|
| 81:32 | What? I don't get to any . Really? I just mean that |
|
| 81:34 | just click on the link that you in the few TF. Um, |
|
| 81:39 | the website never responds on the Just at the time zone did tested |
|
| 81:45 | I put it in, but I test the beginning. See if there's |
|
| 81:49 | places I know in the past, has been Occasionally they have been doing |
|
| 82:00 | changes and it has been some temporary that can, alas, it, |
|
| 82:05 | know, not for a second or , but that prevented you know me |
|
| 82:11 | getting to it on. Um, if anyone has is just with, |
|
| 82:20 | send us an email and we will check that. There's nothing going on |
|
| 82:24 | the website that prevent you. So estimate sure is not the general problem |
|
| 82:30 | them. We can work with you if it's an individual problem to get |
|
| 82:39 | , so we'll double check and see it works. But Andi wasn't. |
|
| 82:47 | are the one that asked about Uh, okay. No. So |
|
| 82:52 | know it's double check on them. can get back to you if it |
|
| 82:56 | for me. Okay. Awesome. else? Okay, Uh, |
|
| 83:22 | and you may love to notify if doesn't have got their Afghans yet. |
|
| 83:33 | , yeah, I forgot. So also knew have not gotten yourself accounts |
|
| 83:39 | pull back. And, um, you see or have seen these do's |
|
| 83:46 | ? Because it's important that you get . Quick, please. On you |
|
| 83:54 | again tried to cram things into the day or two before his due |
|
| 83:59 | Um, so let's get you recount s. A p. I know |
|
| 84:04 | you have gotten. So there's not issue for many of you in that |
|
| 84:08 | that you have these problems using the and let us know. So you're |
|
| 84:12 | stuff. Please get their guns. about things. Okay. Okay. |
|
| 84:30 | , uh, I wrote trying to stuff recording her. If I can |
|
| 84:36 | somewhere, I'll stop there according now then inhibit the video will be, |
|
| 84:42 | I will check. Um, Mr with the video points website and get |
|
| 84:47 | to Jurgen. All right. Thank . Thank |
|