| 00:02 | um Good afternoon everyone. We're very to have Janice today to share with |
|
| 00:10 | what has been very helpful mentoring to of our other PSD students and other |
|
| 00:16 | groups thinking about data and what it means. Right? So sometimes one |
|
| 00:22 | one is three and I think that's probably you know one of the indirect |
|
| 00:26 | we'll have today. So Janice please it away. Right. So first |
|
| 00:30 | all thank you all for the I'm very pleased to be here to |
|
| 00:36 | on my soapbox. Um So like said we will have the slides available |
|
| 00:43 | after the class and we are recording so um you can refer back if |
|
| 00:50 | you know this is I've tried to a lot of material in this. |
|
| 00:56 | should be able to get through all it but if you have questions or |
|
| 00:59 | you want to look back at Right well we'll make sure that you |
|
| 01:04 | that opportunity. So um let's see are we what are we going to |
|
| 01:10 | about? So this could be useful at least the PhD students here just |
|
| 01:17 | us a little bit just maybe just or three phrases related to their area |
|
| 01:21 | research. Oh yeah so so I uh I am um here at the |
|
| 01:29 | of History. I am in the science department but I also teach at |
|
| 01:35 | owner's college in the data and society and I also am an instructor at |
|
| 01:40 | D. S. I. The . P. D. S. |
|
| 01:44 | . At their micro credential programs. broadly um interested in the sort of |
|
| 01:54 | learning um deep learning kind of problems with an emphasis on the data |
|
| 02:03 | So it's it's not so much about methodologies but it's about the um sort |
|
| 02:10 | the steps that you have to take make sure that you get usable data |
|
| 02:15 | you can then work with your And that comes from my background. |
|
| 02:22 | my PhD was in math. You I'm a recovering mathematician statistician. So |
|
| 02:30 | so that's basically the flavor of what going to talk about today and why |
|
| 02:37 | perfectly. And so I'm going to go through, I'm just going to |
|
| 02:40 | each PhD student to just tell us area of research that might also be |
|
| 02:46 | context for you. So I'm just to call out the names, Just |
|
| 02:49 | you, tell us the area of is not a lot of details. |
|
| 02:52 | , so will I. Hi I'm uh my area of research is high |
|
| 03:00 | computing. I'm trying to optimize and up the machine learning algorithm using open |
|
| 03:06 | MP. I. And thank Mhm. Hello. My research area |
|
| 03:13 | computer vision uh in in more specific detection, facial emotion affection. And |
|
| 03:21 | I'm trying to improve one of the expressions algorithm in machine learning. Thank |
|
| 03:27 | very much. MTs. Hello My research was previously based on data |
|
| 03:34 | on google scholar data. Thank you much Robin Hi I'm doing my research |
|
| 03:41 | the area of machine learning for Super . Our goal is to introduce new |
|
| 03:46 | , promote and improve their interpret ability evaluating neural model of sub support. |
|
| 03:51 | you very much if you can hear formula. Hello Professor. My research |
|
| 04:03 | in three D modeling and visualization. you. Round up. Hello. |
|
| 04:11 | research area is your spatial analysis. epidemiological analysis and data led into epidemiological |
|
| 04:19 | . Thank you. Thank you. . My research area is in computer |
|
| 04:27 | more specifically is augmented reality virtual reality also medical robotics. Thank you. |
|
| 04:37 | my research area is in textual summarization lecture videos and my first step is |
|
| 04:42 | extract keywords. Thank you. I we ran out of people here and |
|
| 04:45 | now with all you. All That's quite a broad range of subjects |
|
| 04:53 | as befits a top computer science Um but so hopefully you know what |
|
| 05:01 | going to talk about, you will that it could be applicable to all |
|
| 05:07 | the things that you're you're doing and of the reasons why is um at |
|
| 05:14 | point whatever it is, whatever kind research is that we're trying to do |
|
| 05:20 | going to have to evaluate it and some point we're going to have to |
|
| 05:24 | about some kind of statistical way of about what the results are and whether |
|
| 05:32 | know they show and affect whether they're showing something happened or didn't happen better |
|
| 05:40 | worse than than the baseline. So is partly what I want to focus |
|
| 05:47 | . This is what this lecture is to be focused on and it's supposed |
|
| 05:52 | sort of go a little bit give some intuition and some discussion about |
|
| 05:59 | why is it that we use the , methods that we use and what |
|
| 06:07 | of misconceptions that are common misconceptions that easy to occur so that you can |
|
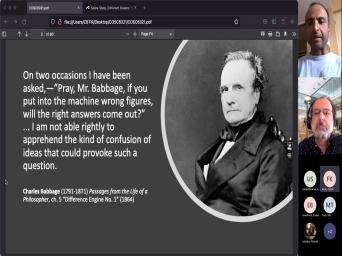
| 06:15 | . So the slide that I have that you know the reason I have |
|
| 06:20 | is because I like this quote, mean obviously it shows that computer science |
|
| 06:26 | you know, even from the early was keenly aware of the fact that |
|
| 06:31 | have to think about how you frame problem. You think you have to |
|
| 06:35 | about your data if you just run evaluation algorithm blindly, you put in |
|
| 06:43 | figures the right answers have no chance coming out right garbage in garbage |
|
| 06:50 | So there are basically four questions that always keep in mind when I'm working |
|
| 06:57 | something and these are listed right here these are sort of the things that |
|
| 07:02 | want to go over because a lot times we don't necessarily pay close attention |
|
| 07:11 | these, the answers to these questions this is not just students, this |
|
| 07:17 | I mean you could find published papers good scores and you would be surprised |
|
| 07:25 | by the fact that they didn't pay attention to these four questions. So |
|
| 07:31 | , this is what what we're talking . So you're going to look at |
|
| 07:35 | kind, there's going to be some of statistical summary. I mean it's |
|
| 07:39 | to have like the mean reported or going to have some kind of, |
|
| 07:44 | know, the media and some kind parameter estimation from your distribution. Does |
|
| 07:49 | say what you think it says? we on the same page with the |
|
| 07:57 | ? The next question is it could a whole bunch of tables that talk |
|
| 08:02 | the statistics of the data that you the evaluation or even maybe your research |
|
| 08:08 | , if your problem is amenable to , does that give you the full |
|
| 08:14 | of what you're trying to understand when collected this data or are things |
|
| 08:21 | Then the third question is, there's to be some statistical tests, there's |
|
| 08:27 | to be someone talking about p values accepting the alternate hypothesis or power. |
|
| 08:36 | like that. Um, there it's very common to misunderstand what is |
|
| 08:45 | described there. If you don't pay attention. And then finally, even |
|
| 08:51 | all those things are right, you always ask yourself if the question itself |
|
| 08:57 | you're asking makes sense and we have example in the end that I think |
|
| 09:03 | make this a little bit clear. these are the four types of things |
|
| 09:09 | I want to try and talk about and hopefully um it will make a |
|
| 09:15 | bit more sense once we go through details. Okay, so part |
|
| 09:23 | let's talk about statistical summaries. so here's the here's what I |
|
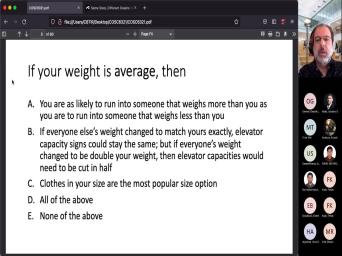
| 09:28 | When I say um think about Let's say that you want to figure |
|
| 09:34 | what the average weight is, You compute a number right? There |
|
| 09:42 | many ways to do that right? could look at the mean, you |
|
| 09:45 | look at the media and you can at the mod, you could look |
|
| 09:49 | does it mean when you look at number? What does it mean? |
|
| 09:54 | you say I want to see if way it is average right? We |
|
| 09:58 | all look at this multiple choice Do we think that one of these |
|
| 10:07 | Is the right one. Do we that all of these answers are the |
|
| 10:12 | 1? Do they all produce the number if they don't produce the same |
|
| 10:19 | , what does that mean? These are clearly very different ways of |
|
| 10:27 | about what it means for something to average. But at the same |
|
| 10:33 | these are all equally valid ways because might be asking about something right? |
|
| 10:43 | it depends on what you want to with the answer. It depends on |
|
| 10:48 | you're trying to get out of the . Whenever you're producing a summary, |
|
| 10:54 | necessarily focusing on some aspects and your emphasizing other aspects. So you have |
|
| 11:01 | think about what it is that you're . So these things emphasize different aspects |
|
| 11:07 | your data. If you're looking at like the mode of your distribution. |
|
| 11:12 | you're saying like what's the most popular ? Right? That's different. And |
|
| 11:20 | you're saying I want to understand I want to understand how the data |
|
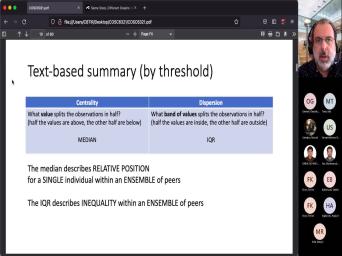
| 11:27 | . Right? When you talk about median of a set of data, |
|
| 11:34 | that says is it splits your values observations in half, half of the |
|
| 11:40 | are below the median and the other are above it gives you a threshold |
|
| 11:45 | ? In the middle. That is the same as what is the most |
|
| 11:51 | choice? Right? That is not same necessarily as what's the right? |
|
| 11:58 | mode? So this gives you a position so it answers a different |
|
| 12:06 | Okay. And it's obviously this was you know you have to be able |
|
| 12:11 | order your data to even answer that your data is categorical, you don't |
|
| 12:16 | any sense of the media. But two only agree. Right? If |
|
| 12:25 | have a symmetric uni modal distribution. ? So the median and the mode |
|
| 12:32 | always are not always the same. ? So that means that the answer |
|
| 12:38 | the question, what's the most popular is not the same as the answer |
|
| 12:42 | the question. What observation splits the in half and then you have the |
|
| 12:51 | quartile range. Okay? That's a of dispersion, right? Again? |
|
| 12:55 | says what band of value splits the in half, right? So You |
|
| 13:01 | two values, one is the the other is the 75%, quarter |
|
| 13:07 | half. The values are inside the half are outside. That's a different |
|
| 13:13 | of thinking about spread for your It's not the standard deviation, |
|
| 13:19 | It is the inter quartile range is again, a 5050 split 50% half |
|
| 13:27 | observations are inside the other half are . That gives you a different measure |
|
| 13:34 | what it means to think about how out your data is Which is not |
|
| 13:40 | same as the standard district standard deviation you're doing your statistics. Right? |
|
| 13:46 | depending on the kind of question that asking right, the the answers that |
|
| 13:54 | get would be different. So the right is yet another way of thinking |
|
| 14:03 | right? It says, let's look the total sum, right? The |
|
| 14:07 | value and then let's compare this to standardized measure that's divided by the number |
|
| 14:14 | observations. Right? So this is comparison measure. Alright, This says |
|
| 14:22 | does the total sum compare to the ? Right. And it's an easy |
|
| 14:29 | to compute So people use it all time, but that doesn't mean that |
|
| 14:33 | is always the most appropriate measure if distribution is not symmetric, right, |
|
| 14:41 | ? The mean is not the same the median, So the mean doesn't |
|
| 14:46 | you where half your observation split You could have a skew bread for |
|
| 14:54 | distribution. Think about something like Okay, There are some people that |
|
| 15:03 | very high worth very high incomes, billions. Most of the people do |
|
| 15:12 | . If you say what's the average instead of, you know, half |
|
| 15:16 | people have less than that and half people have more. That is going |
|
| 15:22 | be much, much less than if will say what's the average income in |
|
| 15:28 | ? Let's sum up the income of the people and see what the mean |
|
| 15:33 | is, right? That clear so , like what I'm talking about. |
|
| 15:40 | it make sense? Right? So another way, here's a different way |
|
| 15:49 | which the mean and the median are And why? It's not always enough |
|
| 15:59 | just look at one and you might to look at both of them. |
|
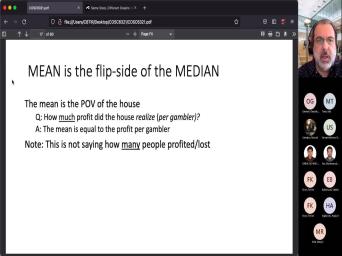
| 16:04 | , So the main is the flip of the media, the mean is |
|
| 16:09 | point of view of the house. you're thinking of gambling. Okay. |
|
| 16:15 | mean tells you how much profit the , right? The casino the lottery |
|
| 16:23 | going to make per gambler, It looks at the total profit that |
|
| 16:29 | make and it divides it by the of people that play. Mhm. |
|
| 16:34 | is not right, telling you how profit each gambler makes on average. |
|
| 16:42 | is not saying how many people are to profit or loss. Right. |
|
| 16:51 | you could have 99% of the people and one person lose and still you |
|
| 17:00 | have the casino make money because that lost so much more or vice |
|
| 17:07 | Right? So it's not about the many it is, about how much |
|
| 17:13 | that's the opposite of when you look the media, right? The median |
|
| 17:17 | the point of view of the gambler ? How many gamblers make a |
|
| 17:24 | If the median is greater than more than half of the gamblers make |
|
| 17:28 | proof if the median is less than , less than half of the gamblers |
|
| 17:34 | a profit. So again, this say how much we could be talking |
|
| 17:40 | scents or we could be talking about . If you care about the |
|
| 17:46 | you need to look at the media you care about them much, you |
|
| 17:51 | to look at the mean right? different things. So that's what I |
|
| 17:59 | by like when you're looking at the of your data, Right? It's |
|
| 18:04 | enough to just look at one or . A lot of times you have |
|
| 18:08 | look at all these different measures, have to look at all these different |
|
| 18:13 | to understand exactly how does the distribution your data? How is it |
|
| 18:19 | Right, What are these are different and you should have different ways of |
|
| 18:26 | them in order to get a full for your dad? So does that |
|
| 18:34 | sense so far? Am I going fast? Alright, it makes |
|
| 18:44 | So let's move on then, and look at Okay, so now that |
|
| 18:51 | can, you know, you can back and you can think about like |
|
| 18:54 | answers each one of these questions. how would you get a full |
|
| 18:58 | Right, Will you visit the original ? So let's move on to the |
|
| 19:04 | part. Right. So we're trying get a fuller picture by looking at |
|
| 19:10 | of these statistical measures. Right? the point is that sometimes you literally |
|
| 19:19 | to look at the picture and this what I mean by that, I |
|
| 19:23 | know if any of you have heard the data saurus. I know one |
|
| 19:27 | you has because one of you has me talk about this before but it's |
|
| 19:34 | really interesting um example um that you go online, you can click on |
|
| 19:43 | link and you can play with it the code is available, you can |
|
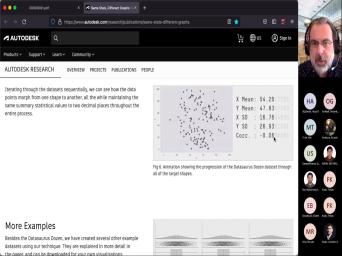
| 19:46 | it yourself and this is what I by that let's look at this image |
|
| 19:53 | the right, Okay, what does image do? Well, it has |
|
| 20:00 | the left side of it, the part of it, it has a |
|
| 20:04 | plot, right? It has basically whole bunch of different data sets, |
|
| 20:13 | ? You can see how the picture and it plots all these datasets and |
|
| 20:19 | the right, it computes the mean for the X variable, the mean |
|
| 20:29 | for the Y variable, the standard for the X. Variable and the |
|
| 20:34 | deviation for the Y variable. And also computes the correlation coefficient. These |
|
| 20:41 | all things that we know we've we think we understand. And if |
|
| 20:45 | told you that I have a data and it has, this means |
|
| 20:53 | this means for the Y 47.83, correlation coefficient negative 0.06. You might |
|
| 21:03 | that you have a pretty good picture what that dataset looks like. And |
|
| 21:09 | I'm here to tell you is that these datasets up to this precision, |
|
| 21:16 | significant digits, they have the exact statistics. Every single one of those |
|
| 21:23 | , every single one of those scatter produces the same statistics. When you |
|
| 21:33 | at that kind of accuracy. So does that say? Should we think |
|
| 21:40 | all these data sets the same Should we use the same kind of |
|
| 21:46 | to try and um you know, them to try and analyze them, |
|
| 21:53 | are very different. They have very patterns, they should be looked at |
|
| 22:01 | very different ways, right there? at all the same. But if |
|
| 22:07 | just look at the summaries, if just look at those numbers, we're |
|
| 22:12 | to miss that we're going to miss picture. And there's other examples, |
|
| 22:18 | , it doesn't have to be as as this. The point is that |
|
| 22:24 | know even if you look at the plot there's information missing. It might |
|
| 22:30 | tell you everything that you want when trying to understand how to analyze the |
|
| 22:37 | . So it's always it's never a of time to try and do some |
|
| 22:44 | data analysis to try and look at plots to try and look at your |
|
| 22:49 | in different ways, not just in of statistics but also instead in terms |
|
| 22:55 | graphs. So anyone, I have this before, anyone surprised by the |
|
| 23:06 | that this happens. Is this something seems like oh yeah we knew about |
|
| 23:15 | . Um I just I recently very saw paper where they tested like some |
|
| 23:22 | by giving students data like this. the just to check whether people were |
|
| 23:29 | actually going through the data correctly or . I saw it on twitter |
|
| 23:34 | It was the paper where um the were asked to verify whether a certain |
|
| 23:43 | relation existed and the ones that were to verify it did not notice that |
|
| 23:49 | was a gorilla in the scatter And the ones that were not told |
|
| 23:56 | the gorilla right? Which if you a gorilla shape in your data set |
|
| 24:02 | would immediately start being suspicious about whether real data or not about whether you're |
|
| 24:09 | know data collection was working properly or . Right? So that's what we're |
|
| 24:17 | about. But what I want every of you to keep in mind is |
|
| 24:24 | you can never spend too much time at your dad. I mean you |
|
| 24:31 | just do that. You eventually have do other things with it, but |
|
| 24:36 | think that it's waste of time to at your data and and think about |
|
| 24:41 | carefully. Okay, so this is the way, this is called |
|
| 24:50 | if you want a fancy name for . It goes back to the paper |
|
| 24:56 | FJ AM scum like almost 50 years and it's called he had started with |
|
| 25:03 | Quartet, which is these four datasets that he showed and those show again |
|
| 25:10 | we were talking about. They all the same statistics. But if you |
|
| 25:15 | looking at the data set that's top , maybe a linear regression makes |
|
| 25:21 | But if you're looking at the data on the top right, it's clearly |
|
| 25:24 | quadratic. You shouldn't be looking at linear regression when you're looking at the |
|
| 25:30 | left here. Again, strong linear trend, but strong outlier. |
|
| 25:39 | So how you deal with the data is going to change even though the |
|
| 25:46 | set has the exact same statistics, maybe a little bit of a |
|
| 25:53 | but maybe this is useful for all us. Sure. Um Is there |
|
| 25:59 | unity universally accepted definition of an Because otherwise I'm tempted to basically look |
|
| 26:06 | the data if some point is away what I'm expecting. I'm gonna delete |
|
| 26:10 | saying it's an outlier. What's wrong that? So we'll touch maybe a |
|
| 26:17 | bit on that. The next the question is about statistical testing. And |
|
| 26:23 | outliers are the way you define an . Right? It can mean two |
|
| 26:33 | things. So one thing is that you have, if you understand that |
|
| 26:43 | have control over how you collect your , right. Outliers are basically things |
|
| 26:52 | don't follow the protocol for data So if you had like humans coding |
|
| 27:01 | data said, right, Some humans mistakes, right? There's typos there's |
|
| 27:09 | sleep whatever those could be considered right? Because the method that produced |
|
| 27:15 | right, is different. So this the kind of thing that you catch |
|
| 27:20 | having some kind of sort of audit , some sort of quality assurance, |
|
| 27:26 | control, whether you're collecting the Right? So that's how you deal |
|
| 27:32 | that kind of thing. But there another definition if you will of outlier |
|
| 27:39 | comes like if you don't have access that, like you're presented with the |
|
| 27:43 | set, right? And you're looking it. Mhm. And there the |
|
| 27:48 | way to decide if something is an or not is by having a model |
|
| 27:54 | your head, in your like you how the data should look like, |
|
| 28:00 | ? You have to have a distribution place, you have to have an |
|
| 28:04 | for what you think, right? two different types of data that live |
|
| 28:11 | this data, right? You say for example, in this example that |
|
| 28:16 | have here in the bottom left you could say I trust my model |
|
| 28:25 | than I trust the data. I that there's a linear trend because |
|
| 28:32 | right? Not because I'm looking at data here, but because the process |
|
| 28:36 | I'm studying should have a linear right? So then if I see |
|
| 28:41 | that don't fit that linear trend in very obvious way, right? The |
|
| 28:46 | trend can give me a statistical right? The ones that failed a |
|
| 28:52 | test, they're outliers somehow they were by mistake. Somehow they come from |
|
| 28:58 | different process and I ignore them. ? But that is very much dependent |
|
| 29:05 | you having a suggestion about what the is like a theoretical understand prediction |
|
| 29:15 | Right? So you trust your model you reject that right? If you |
|
| 29:22 | have any strong reason. Two trust model, right? Then it's |
|
| 29:31 | much harder to reject data. Then what you do is you |
|
| 29:38 | well maybe I trust my data and need to think about different models. |
|
| 29:46 | I thought about the model was is and I need to think that. |
|
| 29:52 | most of the time the safest thing do if you see a situation like |
|
| 29:57 | is to seek to get more data . That's not always an option. |
|
| 30:04 | if you get more data, you sort of get a better stronger right |
|
| 30:13 | if you will about whether you should your model, right? Does it |
|
| 30:19 | to produce more outliers at the same or you know, do they go |
|
| 30:26 | ? Right. Like the new points in line with the data that you |
|
| 30:33 | ? Does that make sense? It . It makes me even curious about |
|
| 30:38 | question which is uh if I trust model and if I know the |
|
| 30:44 | why should I even bother collecting Because that's a great question because in |
|
| 30:54 | statistics, the reason you collect data not so that you can see which |
|
| 31:00 | is better. It's so cold that can estimate the coefficients of your |
|
| 31:09 | So if you say that's a linear , right? I know that distance |
|
| 31:16 | related to speed by a linear Right? You don't collect data to |
|
| 31:24 | that you collect data to establish what's marginal coefficient, Right? What's the |
|
| 31:31 | for that relationship? What's that And that's what traditional statistics does. |
|
| 31:39 | . It says, how can I these numbers these parameters? Right. |
|
| 31:45 | parametric statistics. If I know that is the model, right. If |
|
| 31:50 | hypothesize that this is the model. makes a lot of sense, then |
|
| 31:56 | do I know which relationship? How I select the relationship then between let's |
|
| 32:03 | distance and speed. Let's see if don't know, is it linear or |
|
| 32:08 | . Right? So if you're let's say machine learning. Right? |
|
| 32:11 | say okay, um Sidekick learn has total of 15 different models with 20 |
|
| 32:19 | parameters each. So I need to up 300 runs and I will see |
|
| 32:25 | gives me the highest accuracy, That's kind of like how a lot |
|
| 32:30 | people do it. Um and that's how statistics works. So let me |
|
| 32:39 | on. I think that if I on to my third part, it |
|
| 32:45 | become a little bit clearer how to about answering that. Is that |
|
| 32:52 | Of course. Thank you. but great questions. Right. This |
|
| 32:56 | this is I'm glad that we're discussing . So that's the third question. |
|
| 33:05 | ? So it says does the statistical say what you think? It |
|
| 33:11 | All right. Like we said, of the time, a statistical says |
|
| 33:15 | tell you whether the model is It tells you what the coefficients for |
|
| 33:19 | model. R right? So this where we get to hypothesis testing. |
|
| 33:29 | , let me ask before we even started, people have seen hypothesis |
|
| 33:36 | I'm assuming people have heard of you know, and selecting the beta |
|
| 33:44 | and looking at power, is there we're not judging. But is there |
|
| 33:50 | that has not heard of like no and alternate hypothesis and significance and alpha |
|
| 34:04 | . Okay, good. So you have an understanding, right? At |
|
| 34:09 | in in theory of what we talked when we say statistical testing. So |
|
| 34:17 | me try and and walk you through a little bit because I think that |
|
| 34:24 | is one of the most misunderstood concepts statistics and it is not an easy |
|
| 34:32 | and it is not, I thought and I have a whole bunch of |
|
| 34:37 | if you're interested to show you why , this is leading to reproducibility |
|
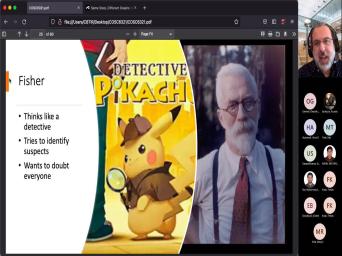
| 34:44 | So the thing to remember is that whole thing started with a statistician called |
|
| 34:49 | about 100 years ago and Fisher's attitude that of a detective. Fisher was |
|
| 34:58 | saying statistical testing. The purpose of testing is so that we can doubt |
|
| 35:07 | . It's not. So that we choose the model the purpose of statistical |
|
| 35:13 | so that we can say do I that this model is a good choice |
|
| 35:20 | most of the time that would be answer would be no. And his |
|
| 35:26 | was geared towards rejecting, right? the null hypothesis, the default position |
|
| 35:35 | that someone is innocent. They've done wrong. If you're trying to estimate |
|
| 35:41 | means or some kind of slope or The difference. Right? The number |
|
| 35:46 | zero. All right. That's your hypothesis. And then Fisher says, |
|
| 35:55 | let's set up the rejection of that . The alternative is not innocent. |
|
| 36:02 | alternative is they did something wrong. alternative is the difference in population means |
|
| 36:09 | not zero. The alternative is their . Right? So our model is |
|
| 36:17 | baseline assumption and we're trying to find to doubt it. We're trying to |
|
| 36:23 | reasons to say maybe that's not a model. Thank you. So the |
|
| 36:29 | that this works is we produced a value. Anyone here doesn't know how |
|
| 36:37 | compute a P value or how to a program. Right? Your favorite |
|
| 36:45 | that will produce the P value for experiment. Again, here's what the |
|
| 36:55 | value measures, right? The p is the probability that you would observe |
|
| 37:06 | results of your experiment. If your your model was true, Right? |
|
| 37:17 | what percentage of innocent people behave in suspicious way? That's what the P |
|
| 37:26 | is. Thanks. Let's tried to thought experiment. Let's say you have |
|
| 37:33 | coin? You flip it 100 times value is the proportion of the |
|
| 37:41 | right? One experiment is 100 Another experiment is another 100 flips. |
|
| 37:47 | ? What proportion of those experiments would a specific degree of bias? |
|
| 37:55 | Would produce a certain number of tails more? Right. More extreme. |
|
| 38:02 | we're looking at the false alarms. ? So if we say, How |
|
| 38:09 | times would we get 60 tails or ? Right? The p value is |
|
| 38:18 | one out of 20 times that you the 100 flip experiments? If you |
|
| 38:26 | get 60 tails or more, that's the P value does, that's what |
|
| 38:32 | p value measures. It says. the coin is fair, right? |
|
| 38:37 | your model is correct, then You see this experiment 5% of the |
|
| 38:46 | Is that clear? Yes. So there is something called significance, correct |
|
| 39:00 | takes this bias, right? The of tails and translate it into standard |
|
| 39:08 | , right? The sigma's it says this experiment, 55 tails or |
|
| 39:16 | That's one standard deviation away, 60 more. That's two standard deviations, |
|
| 39:25 | or more. That's three standard deviations so on. Right? So significance |
|
| 39:33 | to the number of standard deviations, ? We can always translate In two |
|
| 39:40 | deviations that the spread of the right? So the smaller the P |
|
| 39:48 | , they hire the significance, the sigma's And so the more you can |
|
| 39:54 | the model, but the more you say that's not I'm not trusting |
|
| 40:00 | right? That's that's it's risky to that this is the case. It |
|
| 40:07 | only happen 5% of the time. what are the odds, right? |
|
| 40:15 | , you start with the model, assume it's true, Low p |
|
| 40:20 | high significance means you have reason for , right? And here's the |
|
| 40:28 | Here's why significance is important because different and different people. I mean, |
|
| 40:37 | no uniform way to decide what's good . Alright? If you're looking at |
|
| 40:43 | polls, you know, they talk the margin of error, that's one |
|
| 40:49 | . And if something is above the of error, they say, you |
|
| 40:54 | , this is a tight race. say these people are, you |
|
| 40:57 | this is a clear winner in the . Well, one sigma is not |
|
| 41:06 | enough. If you're talking about something physics in physics, You need 5 |
|
| 41:15 | to establish that this model should be to establish that you found a different |
|
| 41:22 | , right? So huge gap in people think about which is why the |
|
| 41:30 | that we think about reporting significance level be reflecting that, right? You |
|
| 41:40 | basically compute the p value, then the significance level that value has. |
|
| 41:47 | then you can say this is the level, right? This is the |
|
| 41:52 | of trust. This is the level doubt, right? 1.96 or 2.5 |
|
| 41:59 | whatever the level is, right, that and say that's why I'm doubting |
|
| 42:04 | . Right? That is the responsible to talk about it. If you |
|
| 42:10 | it's less than 5%, right? that's the two sigma standard. |
|
| 42:16 | okay, but that's not really Like who made this the uniformly, |
|
| 42:26 | know, the universal standard for So, that's what significance is |
|
| 42:34 | Right? That's the way that fisher this whole process of Well, how |
|
| 42:39 | I know if this model makes sense my data, right? He |
|
| 42:44 | let's think if if the model were , would we get this data set |
|
| 42:52 | ? That's what fisher says. He , Let's look at this example, |
|
| 43:01 | ? 4% for provide. Right? means that there were 96 people out |
|
| 43:09 | who are innocent and are not acting and there's going to be four people |
|
| 43:15 | are innocent but are acting suspiciously. ? That's like the tail event. |
|
| 43:20 | ? That's the 60 taels or more we flip a fair coin. |
|
| 43:28 | This is what the P value It's the likelihood that you would get |
|
| 43:35 | observed evidence in your experiment if you that experiment and the model was |
|
| 43:47 | Right? So can anyone see why can be problematic? What's wrong with |
|
| 43:56 | thinking here's the what's wrong Shouldn't we in the business of looking at guilty |
|
| 44:19 | ? Why confuse just the probabilities of people that are innocent? We should |
|
| 44:24 | finding the guilty people. We should thinking about the red row numbers, |
|
| 44:30 | the green row numbers saying okay, doubting this because not many innocent people |
|
| 44:41 | that way is not the same as data set suggests that this person is |
|
| 44:51 | ? So Janice Are you saying we to look at the population mean population |
|
| 44:56 | and distribution. So what I'm saying that we need to think of this |
|
| 45:03 | a binary classifier problem. This is hypothesis testing, right is not simply |
|
| 45:13 | give me a probably give me a level because really what it is. |
|
| 45:20 | a binary classifier and a binary classifier a confusion matrix. There are two |
|
| 45:29 | types of mistakes you could be What you really want to do is |
|
| 45:33 | want to know if your model is positive, right? That's what we're |
|
| 45:42 | to understand. Is this model truly model that underlines the data. And |
|
| 45:49 | we think about it this way, that means that our experiments are statistical |
|
| 45:56 | testing is really an algorithm for There is a binary outcome. This |
|
| 46:05 | the right model. This is not right model. And there is a |
|
| 46:10 | truth, right? And what we to do is we need to structure |
|
| 46:16 | hypothesis tests to understand what their performance . In terms of this confusion |
|
| 46:24 | Right? How many times do they us the true positive? Not just |
|
| 46:29 | many times do they avoid the false ? Because that's what fisher does. |
|
| 46:38 | ? If you only think about significance you're only thinking about the false |
|
| 46:45 | You're not thinking about the two So how do they go through thinking |
|
| 46:51 | positive? I'm glad you asked because my next slides. So we have |
|
| 46:58 | think like lawyers, Okay, what trying to do is there's two cases |
|
| 47:05 | . One suppose one supposes that the is innocent, the other lawyer says |
|
| 47:11 | person is guilty, right? That's binary classifier. The p value is |
|
| 47:19 | the false positive or the false alarm . Right? This is what we |
|
| 47:25 | . This is by definition right? want this percentage to be small. |
|
| 47:32 | we also need to think about the positive rate. And if you look |
|
| 47:39 | this, you will find out that is called so many different things. |
|
| 47:44 | called rico. It's called sensitivity. called the hit rate. It's called |
|
| 47:49 | power of the test. And the it's called so many things is because |
|
| 47:54 | is very, very important and people many, many fields, not just |
|
| 48:01 | decision theory. I mean they've come with it again and again. |
|
| 48:06 | And there is no standardized way of about. But really this is the |
|
| 48:11 | important ratio that we have to think . If we have a statistical |
|
| 48:17 | it should have specific performance in terms its true positive rate. Right? |
|
| 48:26 | it should be as close to 100% possible. Right? We don't want |
|
| 48:33 | get false negatives either. Right. that make sense? So, here's |
|
| 48:45 | we think about the performance of a test classify. This works for any |
|
| 48:52 | classification algorithm, not just statistical Right? You have one axis where |
|
| 48:59 | plug the p value, right? you have another axis where you plot |
|
| 49:05 | power And the perfect classifier would have for the P value. Right? |
|
| 49:11 | smallest p value that you can. ? That's the highest significance, |
|
| 49:17 | The smaller the p the more the And it would have 100% for |
|
| 49:24 | Right? Remember power is a true rate And we want that to be |
|
| 49:30 | . Right? So it should be to 100%. So it should be |
|
| 49:33 | number here. And the problem is actual classifiers doesn't matter whether it's a |
|
| 49:43 | test or if it's a face recognition or if it's a, you |
|
| 49:49 | as long as you have a binary , you're going to be away from |
|
| 49:54 | point, You will have two types errors. There's what's called the Type |
|
| 49:59 | error and the Type two error. , how many people have heard of |
|
| 50:04 | one and Type two errors? I this stuff. Okay, so if |
|
| 50:16 | haven't, this is what they are . It's just a fancy way of |
|
| 50:21 | about. But false positives and false . Type one error is How far |
|
| 50:31 | From 0% are you in your P ? How far off from one |
|
| 50:37 | 100% arguing your power. But so is a fundamental limitation that we have |
|
| 50:49 | . Any kind of classifier that we is always going to have To balance |
|
| 50:55 | these two. Yeah. And so going back, right, let's recap |
|
| 51:02 | this is important to get franked. we think in terms of fisher and |
|
| 51:09 | , right? We set up a hypothesis. If we're thinking like Nayman |
|
| 51:16 | Pearson, who were the statisticians that fisher and sort of built up this |
|
| 51:24 | statistical thinking, then we have a a main hypothesis, right, Which |
|
| 51:32 | that someone is not guilty, but beyond reasonable doubt, Right? What |
|
| 51:40 | say is you cannot be 100% sure always going to be a minimum level |
|
| 51:48 | ? You have to show that someone guilty above reasonable doubt, right? |
|
| 51:56 | it's below you're going to keep with presumption of innocence. Right? |
|
| 52:03 | So it's not about whether in truth is an effect, it's about whether |
|
| 52:12 | test is capable of detecting it. not about whether this. In |
|
| 52:19 | this is the wrong model. It's whether your test is equipped to reject |
|
| 52:27 | model. Those are two different It's not about whether someone is |
|
| 52:33 | It's about whether we can prove it reasonable doubt. Right? Does the |
|
| 52:39 | show above a certain threshold? And a key difference, Right? And |
|
| 52:47 | goes to the alternative hypothesis as It says, what's the other lawyers |
|
| 52:56 | ? The other lawyer is saying it above the reasonable doubt, it is |
|
| 53:03 | the minimum level, it is a effect. Right? And so these |
|
| 53:10 | the two competing positions that we have we run a statistical test, one |
|
| 53:19 | says this is the right model up a margin and the other says this |
|
| 53:27 | not the right model. Up to March, Right? And so |
|
| 53:36 | the p value, which can computer value, but this time it's not |
|
| 53:42 | if the evidence is true. I'm if the model is true, that's |
|
| 53:46 | probability of the evidence, right? is the minimum threshold now comes into |
|
| 53:54 | , right? If the model is right? The knoll is true up |
|
| 54:01 | a certain error, right? Then would see this kind of evidence. |
|
| 54:12 | like we said, there's two different of error. There's type one error |
|
| 54:17 | we think like that and there's type error, right? This has nothing |
|
| 54:22 | do with the significance itself. This there's wrongful convictions. We're you have |
|
| 54:31 | who is convicted because the evidence was , but it was actually wrong, |
|
| 54:40 | ? And you have guilty people who acquitted. It's not that they didn't |
|
| 54:47 | it. It's just that the evidence was not enough in either case. |
|
| 54:54 | test that we set up right, a mistake and that's we're trying to |
|
| 55:01 | both. Right? This is what classifier should do. We're trying to |
|
| 55:07 | how a hypothesis test right performs in of these two numbers. Because both |
|
| 55:14 | are important. So the thing to is that the p value right, |
|
| 55:24 | determines whether you get Whether you choose one or the other. Right? |
|
| 55:31 | so if we set it to stricter , right? Like fisher did The |
|
| 55:38 | is zero right? It's not about beyond a reasonable doubt is anyone who's |
|
| 55:46 | gets convicted but 100% power. You're going to miss anyone. But I |
|
| 55:53 | you're also going to convict everyone. ? That's not good. The other |
|
| 56:00 | is if you have a threshold that's high, right? If you |
|
| 56:05 | you know what I need to be 100%. If there is any |
|
| 56:12 | I'm not going to say they're guilty then no one will be a |
|
| 56:18 | no one will be convicted. You never be able to reject the |
|
| 56:22 | right? One extreme. No matter model, you're always going to |
|
| 56:28 | oh yeah, the other extreme, matter the model, you're always just |
|
| 56:33 | to say, hmm, I don't it. It's wrong. Right? |
|
| 56:37 | there's got to be something in right? And the way you think |
|
| 56:42 | that is if you plot your number mistakes and the power right? If |
|
| 56:47 | plot the p value and the just like we did before, you're |
|
| 56:54 | to get a curve, there's going be This point here where the performance |
|
| 57:02 | your classifier is bad because it basically all the type one errors and none |
|
| 57:08 | the top type two. And that's your threshold is too low. And |
|
| 57:13 | another friend where yours classifier does all type two errors and none of the |
|
| 57:20 | work because your threshold is too And as you're very threshold in |
|
| 57:26 | you're moving along a curve and that's the R. O. C curve |
|
| 57:31 | for receiver operating characteristic. It goes to Radar and World War Two but |
|
| 57:36 | not important. So this is what is what the situation is. When |
|
| 57:42 | have a classifier, when you have statistical tests a hypothesis test it's going |
|
| 57:50 | its performance is going to be determined the way you set up the |
|
| 57:57 | And so if you want to be is what we were saying earlier you |
|
| 58:05 | more points. You need more You're always going to do better if |
|
| 58:11 | have more points you never you can have too many points. Okay. |
|
| 58:17 | . Of course. You're limited by budget. You're limited by all kinds |
|
| 58:20 | things in what you have. But have to understand that the amount of |
|
| 58:25 | that you have puts a fundamental limit how well your hypothesis tests can |
|
| 58:34 | Right roo seekers become closer and closer the ideal left top left corner. |
|
| 58:44 | more data points you have right, how power and sample size are |
|
| 58:52 | So another way to think about that that this is this third ratio that |
|
| 58:59 | didn't talk about right? The positive value or the precision of your |
|
| 59:06 | this is what change is what moves R. O. C curve closer |
|
| 59:11 | closer to the perfect classifier. So when you think of your hypothesis |
|
| 59:19 | as how does it perform in terms this confusion matrix, this is how |
|
| 59:25 | things relate. So how does in practical terms? That's not. |
|
| 59:32 | can read about this experiment but let's go skip to the um to how |
|
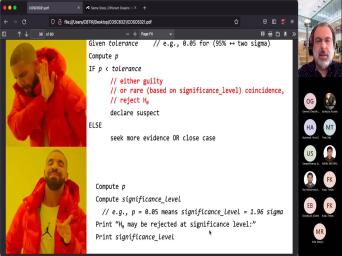
| 59:41 | should work when you're doing a hypothesis . So you start by fixing two |
|
| 59:51 | alpha and beta al phase. The of the threshold that you want for |
|
| 59:59 | one errors right? It's how many conventions in there locked run are you |
|
| 60:06 | to tolerate? How many times are willing to say that's the right model |
|
| 60:13 | it wasn't. And then you have , Which is the long term probability |
|
| 60:18 | the type two error, right, yet acquitted, which is how many |
|
| 60:25 | right are you willing to except the model? Did they say the |
|
| 60:34 | One of them is except the wrong . The other is reject the right |
|
| 60:39 | . But so Usually people use this 5% for alpha and 20% for |
|
| 60:48 | In physics the alpha becomes more like it becomes three million and so |
|
| 60:57 | . But the point is that you these two values right? And once |
|
| 61:02 | fix these two values there is a nothing else that you can do right |
|
| 61:08 | is you're going to have to live the possibility that you made one or |
|
| 61:13 | other mistake and these are the Right? And so this is your |
|
| 61:21 | . You start with an alpha and beta. Do you compute the p |
|
| 61:27 | the p value does not tell you about significance. Now, what the |
|
| 61:32 | value is. Does is it tells if your test is powerful enough to |
|
| 61:39 | that judgment or not, If your value is not, then you don't |
|
| 61:47 | power. You cannot make the So you accept one of the |
|
| 61:53 | But that's just by default. That's the presumption of innocence. Like you |
|
| 61:57 | shouldn't have. That's not a good . That's a sham trial. If |
|
| 62:05 | power is enough, right? If power is enough, then you look |
|
| 62:12 | the P value and you compare it Alpha, your threshold and if it's |
|
| 62:19 | right, then yes, you have reason to doubt the all the main |
|
| 62:27 | . So you accept the alternative. it's not, if it's above the |
|
| 62:33 | , then it means that the opposite . You had enough reason to prove |
|
| 62:42 | main hypothesis. And so that's a model. So, this part |
|
| 62:51 | the power calculation is often not properly , but people do this kind of |
|
| 63:00 | . And then they talk about accepting hypothesis or the other. And then |
|
| 63:04 | talk about the significance of their No. When you're doing hypothesis testing |
|
| 63:11 | you're trying to accept one or the , you're trying to prove if the |
|
| 63:15 | is right or wrong. What you to say is I have enough power |
|
| 63:20 | make that call or my experiment didn't enough power, I should have collected |
|
| 63:27 | data. That's the way to go . Does that make sense? Does |
|
| 63:40 | help with the question that you Yeah. Thank you. Sure. |
|
| 63:51 | we got like what five minutes I won't keep you long. This |
|
| 63:56 | last thing that I wanted to talk right? So if you want to |
|
| 64:00 | more, if you want to read about this, there's a big literature |
|
| 64:05 | the subject. But so Now we to part four. This is sometimes |
|
| 64:16 | most surprising thing for some people. let's say this comes from a paper |
|
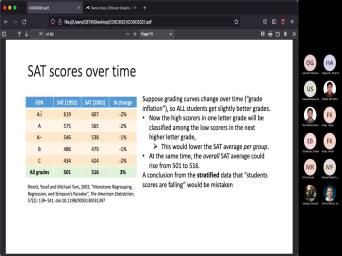
| 64:23 | in 2003. Let's say that we to study S. A. |
|
| 64:28 | Scores over time. S. T. S. R. Like |
|
| 64:30 | is for those of you who are from the US. They're the undergraduate |
|
| 64:35 | take them. Uh And it's a test and the score um The higher |
|
| 64:45 | score the better and it helps you the highest score you have, the |
|
| 64:53 | it is to get into college. They looked at the S.A.T. scores |
|
| 64:58 | 1992 and again, 10 years later 2002. And they had they built |
|
| 65:06 | table where they said, here's the who got a plus in high school |
|
| 65:13 | there G. P. A. those people scored an average. And |
|
| 65:21 | this is mean right? We talked the difference between media and mean and |
|
| 65:26 | the beginning but this is the mean on the S. A. |
|
| 65:30 | Over the people who had an Plus G. P. A. |
|
| 65:34 | it was 619. And then Different of people 10 years later those who |
|
| 65:41 | a plus now score 607 on the . A. T. Right? |
|
| 65:49 | that's the way to read this. that clear? So if we think |
|
| 65:55 | if we look at this there's a like what happens with the S. |
|
| 65:59 | . T. Scores over time. ? And if we look at any |
|
| 66:07 | grade right? If we look at one of these grades you're going to |
|
| 66:13 | there's a drop, it was from 19 to 607. From 5 75 |
|
| 66:19 | 5 65. 2% draw right across grades. If you pick a grade |
|
| 66:27 | average dropped by 1 - 2%. that clear? I'm not doing |
|
| 66:36 | You can verify that right. You the numbers. This is I'm not |
|
| 66:41 | here. So on the average students worse on the S. A. |
|
| 66:47 | . 10 years later can we say ? I mean strange is not that |
|
| 66:54 | but it's his list. Well let's at this top the bottom row. |
|
| 67:03 | . The bottom row is let's look all the students without separate them into |
|
| 67:13 | . Okay. Just all these The average score among all the students |
|
| 67:21 | 501. 10 years later the average is 5 16. That's an increase |
|
| 67:30 | 3%. So now it seems like students are scoring higher on average. |
|
| 67:49 | have a paradox. That is a . It's called Simpson's paradox. Well |
|
| 67:59 | just happened. What does it tell ? What can we say? What |
|
| 68:08 | says is that you have to be ? Are you asking the right |
|
| 68:16 | Okay. This is asking the question ? When I look at any given |
|
| 68:27 | right, does perform as decrease and answer is yes. This says when |
|
| 68:37 | look at any given students, does decrease? And the answer is |
|
| 68:46 | it increases. Right? So the grade performance drops, the average student |
|
| 68:55 | increases. Do you care about the or about the students? It's two |
|
| 69:01 | questions. Why does it matter? is there some great inflation happening |
|
| 69:10 | Is that the reason there it is ? If you look at the grade |
|
| 69:18 | it says that the performance drops the to read this is that the grades |
|
| 69:26 | assigned more leniently right. That's what means for a great. When the |
|
| 69:33 | the S. A. T. for a particular grade, that means |
|
| 69:37 | people will lower S. A. . Scores get the same G. |
|
| 69:41 | . A. Right? So what's is if you had a great |
|
| 69:46 | if you're great incurs change all the get slightly better grades and all the |
|
| 69:53 | do better on the S. T. But now the high scores |
|
| 69:58 | one letter grade will be classified among low scores in the next higher levels |
|
| 70:05 | great. Right. And so the . A. T. Average per |
|
| 70:09 | grade drops. Right. That's what inflation means. So the orange rolls |
|
| 70:15 | that there is great inflation and the Rose shows that students are scoring better |
|
| 70:23 | getting better at the S. T. So you may not be |
|
| 70:30 | the question you think you're answering if restrict yourself to the Orange Rose and |
|
| 70:41 | the point that I want to That's the last point that I wanted |
|
| 70:45 | make. So if the question was we're trying to understand if there's great |
|
| 70:51 | happening, then the orange one is area to focus on. Right? |
|
| 70:56 | . Although then you would want to about how you structure your model, |
|
| 71:04 | ? Because then the letter grade becomes outcome, not the exposure. |
|
| 71:12 | So, but yes, that's basically of them is studying the question of |
|
| 71:20 | inflation. The other of them is the question of student performance. Same |
|
| 71:25 | said, not at all the same . Right. And this is the |
|
| 71:32 | thing that I want to leave you . This is the Choluteca bridge. |
|
| 71:37 | . It was built very modern. It could withstand a category four |
|
| 71:47 | Right? Standards were very exactly. was progress and then the Hurricane four |
|
| 71:54 | hit. And it literally changed the of the river and washed away. |
|
| 72:02 | approaches to the bridge. So, that the right question to ask? |
|
| 72:12 | , did you want a bridge that withstand a hurricane for hurricane or did |
|
| 72:18 | want a system? Right. Did want a highway that could withstand the |
|
| 72:27 | ? Right? It's far better to the right question, but have an |
|
| 72:32 | answer. Okay. Maybe you could less money on building a bridge that |
|
| 72:38 | do so, you know, that be so exactingly bridge, but spend |
|
| 72:42 | of that money on the approaches. rather than having an exact answer to |
|
| 72:49 | wrong question. Okay. And that's why all of these questions that we |
|
| 72:55 | in place are meant to give you mindset that says, am I asking |
|
| 73:01 | right question? My following for Simpson's and my following, Am I not |
|
| 73:07 | the full picture? Am I understanding it means to talk about the statistical |
|
| 73:15 | ? And that's the end of my . As per usual slides were manufacturing |
|
| 73:23 | that processes words, a word So they may contain type of mistakes |
|
| 73:27 | omissions. So if you find let me know. But other than |
|
| 73:33 | , I hope that it was clear I hope that um, when you |
|
| 73:38 | it, it will be even clearer it will be helpful with your research |
|
| 73:46 | thank you again for the opportunity. you. And this, We really |
|
| 73:52 | you spending this time with us. going to ask the students in attendance |
|
| 73:58 | they have any last question. Maybe have time for one question if they |
|
| 74:01 | to. And if and if not is my email, I'll be happy |
|
| 74:07 | follow up because I know that we over. Yeah. All right. |
|
| 74:13 | gonna stop recording now, |
|