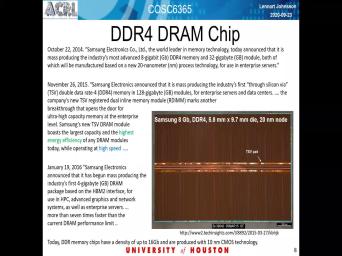
| 00:00 | mhm Yes it is time unit and are not many that has checked in |
|
| 00:24 | . Uh huh will never Let's start asking. And at this time. |
|
| 00:31 | , so I'll continue to document memory today. The last time I was |
|
| 00:37 | talking about cashes and a little bit memory is integrated into and server and |
|
| 00:49 | I'll focus more on main memory itself its properties that is important to understand |
|
| 00:57 | failure. Mm So that's it. it's just kind of well see this |
|
| 01:08 | part one as you forget to part , but part one is about Basically |
|
| 01:12 | main memory in itself. And for , if I get this more about |
|
| 01:19 | power management of systems. So the thing is to talk about the design |
|
| 01:26 | then go through the various stages and try to somewhere as what I've done |
|
| 01:32 | about And this is part two as said, if I get it, |
|
| 01:39 | highly control our consumption. So now the memory, this is just a |
|
| 01:46 | showing a little bit of the Think that's some sense. Uh for |
|
| 01:53 | difference between memory ships and processes chips go back and look at what was |
|
| 02:00 | about in terms of processes, chips to be in the range of 5-700 |
|
| 02:08 | mm and in this case here they considerably smaller. I think this one |
|
| 02:20 | . So this Shows a little bit the horizontal axis. one three different |
|
| 02:26 | memory manufacturers and then for each one them it is successive generations of chips |
|
| 02:38 | but that's this line chance to show I'm is there are considerably smaller. |
|
| 02:44 | As you can see from the left , they're about 40-60 sq mm. |
|
| 02:51 | there are More than 10 times smaller your typical processor chip. And then |
|
| 02:57 | itself has certain consequences in terms of you can actually work with these |
|
| 03:05 | The good news is that memory tends be very cheap. Part of the |
|
| 03:11 | for that is that the chips are so the years and the manufacturing process |
|
| 03:16 | just usually considerably harder than it is processor chips. So that I think |
|
| 03:24 | much and you can also see in of the number or dancing of these |
|
| 03:29 | that are uh pretty impressive. So look at the most recent generation chips |
|
| 03:37 | are about 100 megabits per square So that means you get a typical |
|
| 03:44 | may you know, even up to on a single these silicon that is |
|
| 03:52 | to 50 square millimeters insides Anyway. I was just to get a big |
|
| 04:00 | , a little bit of Iran The chips that is used for making |
|
| 04:08 | memory and pretty much all systems and different is I guess I should say |
|
| 04:16 | . So the memory is since many back their kids back are manufactured in |
|
| 04:23 | same technology as the process of So that is the c most technology |
|
| 04:33 | with but two different types of memory designs fundamentally different designs also have |
|
| 04:44 | different properties. So last time mostly about Cashes and Cashes are built |
|
| 04:50 | I was known as islam or send random access memory. Yeah. Whereas |
|
| 04:58 | memory that the thing that is packaged as dim for instance our goal separately |
|
| 05:04 | the circuit bowl or in this high with memories. They yeah tend to |
|
| 05:13 | birthed out of was known as dynamic access memory. And the difference between |
|
| 05:21 | two kind of a sketch of here the design is like. So the |
|
| 05:27 | memory using the RAM chips there are basically to be cheap and for that |
|
| 05:37 | means also very small in size you lots of bits of human piece of |
|
| 05:43 | and so they are effectively just want capacitor and transistor that is basically an |
|
| 05:51 | on switch and the capacity is the that stores The charge that defines whether |
|
| 05:57 | system is in a zero or 1 the bit that's a zero or a |
|
| 06:04 | . Now the thing that is used caches are the Strahm and they are |
|
| 06:11 | done as six transistor cells not to you on the right hand side. |
|
| 06:15 | that means they are considerably larger in of the silicon area required to store |
|
| 06:23 | bit compared to the D ram. difference is that they are able to |
|
| 06:30 | ST which the than mammograms are kind not very good at. So they |
|
| 06:37 | of leach. So it doesn't take that long before you lost the space |
|
| 06:45 | I'll come back to that. But means that dynamic random access memory also |
|
| 06:51 | to have what's known as a refresh restore charges in the memory cells. |
|
| 06:58 | you get the error because it doesn't charged at least now the design than |
|
| 07:07 | actual memories um are organized in this way isn't as organized as the matrix |
|
| 07:16 | in each one of these little cross past volume extremist orbits. And so |
|
| 07:28 | the operations will come to in a bit uh as to when you want |
|
| 07:34 | particular bit or collection a bit they to gain both a role address and |
|
| 07:41 | address. That's very simple. Just you get the matrix element out of |
|
| 07:46 | matrix that you have a Rwanda column . So there's nothing unique about that |
|
| 07:53 | it also means that if you take micro photograph and remember if you get |
|
| 07:58 | that looks like in the upper right corner, they are incredibly well um |
|
| 08:05 | um or like also seen on this for flipping and touch screen. So |
|
| 08:13 | are incredibly dense and they're much dancer terms of transistors per unit area. |
|
| 08:20 | you'll find in the process of design so well structured and can be compacted |
|
| 08:30 | very highly. There's just another thing tells you a little bit to stick |
|
| 08:34 | the hot I guess by now four ago but density has increased but again |
|
| 08:42 | the picture of it memory chip and is just kind a little bit more |
|
| 08:48 | of the extreme and then if you go and look at the footprint in |
|
| 08:55 | of the actual physical size in terms square millimeters of cells and they are |
|
| 09:01 | larger than what they are in the cells. Again, so that's why |
|
| 09:08 | system is expensive relative to the room it requires a larger amount of silicon |
|
| 09:18 | If I remember I guess roughly at 10 times society. It's not more |
|
| 09:27 | so that uh was going to talk their how this actually works and that |
|
| 09:35 | in part a consequence of this kind matrix type design to get to memory |
|
| 09:44 | or works. So it's just uh are pictures of one thing on the |
|
| 09:50 | hand side. It shows up against and there's a role address in the |
|
| 09:56 | address but right. one of the of memory chips is that column and |
|
| 10:08 | address this share basically bet lines. you're like so you can only give |
|
| 10:16 | address at the time. Either the address or the column address. And |
|
| 10:21 | reason for actually sharing the wires and pins is again that the memory chips |
|
| 10:29 | small so you don't have much real to actually provide all the signals you |
|
| 10:37 | both addressing and data and clocks and and all of it. So it |
|
| 10:44 | been the case for a long That depends for rolling column of justice |
|
| 10:50 | shared and that has consequences on is why the dirham is much lower than |
|
| 10:57 | islam? I'm coming to that, not part of it. I'll get |
|
| 11:01 | why it is a good question about and a few slides. I'll try |
|
| 11:05 | explain why it is but its inherent the matrix design. That's where it |
|
| 11:11 | from. Not so much from the that to share pins. So then |
|
| 11:21 | in part because of also energy one has constraints in terms of how |
|
| 11:35 | um in fact the power, the and I'll come to that. So |
|
| 11:44 | is in fact and I'll explain it the next few slides, but that's |
|
| 11:49 | one goes through some of this That is in the right hand column |
|
| 11:53 | this slide where says activate, read pre charge and refresh. And I |
|
| 12:00 | on the next few slides I'll try make sense out of why these things |
|
| 12:06 | the way they are. But it that it's a bit of a process |
|
| 12:12 | either write or read the memory because takes several steps either to read or |
|
| 12:18 | the memory. It's not just sending address there, even if it got |
|
| 12:24 | separate Derwin column. It is, there's more to the story of how |
|
| 12:28 | the arms are operated. That's not case for extra. So it's unique |
|
| 12:34 | the design for them in order to themselves small and sheep to uh |
|
| 12:44 | So here is a little bit more again where this capacity stores a bit |
|
| 12:51 | the transistor access to switch that basically you to either read or write the |
|
| 12:59 | . The problem with this theory ramses you read, I suppose that you |
|
| 13:05 | the capacity of being charged represents the which is the most common, that |
|
| 13:09 | can be the opposite but there is charge and the transistor that represent the |
|
| 13:15 | . And when you want to capture state, you in fact loses the |
|
| 13:22 | and the transistor. So whenever times read something um you're kind of as |
|
| 13:31 | said destroy the state and that you not what you wanted to happen. |
|
| 13:36 | that means that after you kind of the value, you need to restore |
|
| 13:42 | to make sure that the next time want to access it is still |
|
| 13:46 | the state that you had before. that's part of the reason why there's |
|
| 13:51 | bit of a process that in Read it. In fact requires a |
|
| 13:57 | write type operation every time. Um if you remember this uh matrix picture |
|
| 14:09 | I think I'll come back to that the next slide, I can't say |
|
| 14:13 | . So um so maybe I'll talk it and the slide. So basically |
|
| 14:20 | happens then what Francis one needs to order to be able to read arrow |
|
| 14:31 | um need to what's known as And that's again it's a function of |
|
| 14:37 | fact that how you managed power on chip that. Yeah basically only kind |
|
| 14:43 | enabled one at the time in terms reading roles. And that means when |
|
| 14:50 | go from reading one role to another there is a process again of closing |
|
| 14:56 | or restoring things that you may have in the read process before you can |
|
| 15:04 | or activate another rope. Now Rose to be quite long for instance or |
|
| 15:19 | Rose may contain many Work. So not just 32 or 64 bits. |
|
| 15:26 | uh in order to collect some segments number of bits in a role. |
|
| 15:36 | also then give column addresses. So was again the sharing of the bits |
|
| 15:43 | first to give a row address. that allows you then to activate a |
|
| 15:50 | role that contains the data you want read. And then you provide column |
|
| 15:58 | . But as I mentioned there are data items to cook in the role |
|
| 16:05 | the D. Ram. So you the optional selecting basically different columns that |
|
| 16:16 | the collection of them uh contain the for a word that you will or |
|
| 16:22 | or single or double precision where that want. So once you have activated |
|
| 16:28 | role you can read collections of columns sequence without going through the process of |
|
| 16:40 | they're all again. So uh I'll back to that and if you just |
|
| 16:47 | so the process is usually activate the and then if you have good access |
|
| 16:58 | memory, that means hopefully you will columns within the same rule in order |
|
| 17:07 | to enter the penalty and time in of going through the closure and activation |
|
| 17:14 | a given role and activation of a role. So this is just a |
|
| 17:19 | example showing that this case there are different columns that one wants to read |
|
| 17:26 | of the same role. So that's you activate Rose zero and then you |
|
| 17:31 | for uh set a column zero and read for one and read 3 to |
|
| 17:36 | . But then the next read was a different role in this case just |
|
| 17:40 | next row, row one, but could have been to anyone role and |
|
| 17:45 | process will be the same. So nothing unique just to jump into the |
|
| 17:50 | row. But then before you need do that one needs to do what |
|
| 17:56 | as the pre charge. That is restoring whatever this role was that they |
|
| 18:01 | working with. And then after that's and you can activate it new role |
|
| 18:07 | you want to read. And then process repeats in after all and when |
|
| 18:15 | row is red, It kind of into row buffer and I'll come back |
|
| 18:21 | that 10 later slides. So in what happens is you copy this roll |
|
| 18:26 | the robot for and then you get various columns out of this robe. |
|
| 18:36 | So this is just a listing of I kind of just said, what |
|
| 18:41 | when you want to read in a , you activate it and then you |
|
| 18:46 | go through the rate, right process you want to do and then you |
|
| 18:50 | to close it and then Hold on the next one. So I'll stop |
|
| 18:58 | for after another couple of slides and if there are questions given that there |
|
| 19:05 | a bit of a process as a of several steps in order to read |
|
| 19:10 | write a data item to the one has this notion of cycle time |
|
| 19:21 | is not to be confused with the cycles of the memory. So cycle |
|
| 19:31 | and then when it comes to dirham used to describe there. So the |
|
| 19:40 | time between for making successive requests to memory because each request or access is |
|
| 19:55 | associated with several steps. So that's cycle time for the RAM is longer |
|
| 20:04 | the access time and hello come back that again. And another graphical |
|
| 20:13 | But so it was kind of an of what this access times are cycle |
|
| 20:20 | relationship between them but it's kind of silly example but just to try to |
|
| 20:27 | the fact that there is a process that's why time between successive requests is |
|
| 20:36 | than just retrieving a particular item part the memory. Um and now I'm |
|
| 20:46 | a little bit of the detail but anyone of you at some point in |
|
| 20:52 | life need to buy it the um configure servers and pc's these items are |
|
| 21:00 | fact very important and this refers to different steps that are necessary when you |
|
| 21:09 | read. All right in the Iran there is this column access stroll bar |
|
| 21:23 | just this t cast time that is number of cycles that it takes after |
|
| 21:32 | send or give the column address to memory to the Iran before you can |
|
| 21:41 | get the data uh for that column . And part of these things comes |
|
| 21:53 | the fact that it turns out that memory bus for channel operates the higher |
|
| 22:04 | frequency than the deer on itself. that's in part coming um to halfway |
|
| 22:14 | fully answering the question. Why I'm a slow I will try to |
|
| 22:18 | it more yeah in the following Why? Also then the cock rate |
|
| 22:26 | the memory is so much lower than crop. Great on there. Memory |
|
| 22:32 | that in turn is actually slower than clock rate of the processor typically. |
|
| 22:39 | so there is an memory dear. memory is characteristic with is for timing |
|
| 22:49 | or numbers. So one is again number of cycles it takes after you |
|
| 22:55 | the column address before you can actually the values out. Then there's also |
|
| 23:04 | number of cycles that it takes after give the go address before you can |
|
| 23:12 | the column address and that's sort of road to column delay or RCD. |
|
| 23:22 | there is the thing when in here close up the role that also takes |
|
| 23:28 | time and that's characterized but this time recharge RP and then there is yet |
|
| 23:39 | time that is not related to the time for the memory that is the |
|
| 23:46 | you kind of need to stay in role after the issue a role address |
|
| 23:53 | you can issue mhm, recharger, up the role to move to the |
|
| 23:59 | real. So again, when you at specs for the RAM chips, |
|
| 24:06 | tells you a little bit about what bus rate tends to be or is |
|
| 24:11 | and I'll show you some examples In next side or two but it's also |
|
| 24:17 | in terms of these various delays associated the different steps in using the tiara |
|
| 24:29 | was kind of a little bit graphical of how the different times are |
|
| 24:36 | So the RCD was the time after give their all address. Before you |
|
| 24:42 | give the column address, someone you to do something at all the first |
|
| 24:48 | the road address and that takes a time and then you want to issue |
|
| 24:53 | column address and that is the tr tells you how many stifle it Thanks |
|
| 25:00 | terms of memory bust, cycles of , cycles before events go from one |
|
| 25:06 | the other and once you have ready issue a column address then that in |
|
| 25:12 | takes some time to teach us. then you can is to several column |
|
| 25:22 | without waiting for the completion. So can kind of pipeline address column addresses |
|
| 25:31 | that and then we have this minimum time for a role that is the |
|
| 25:41 | , active time will have to stroke then there is on the right hand |
|
| 25:47 | then they pre charged and when you're all of this. Yeah, so |
|
| 25:53 | minimum active time after you issue the address that tells you the earliest time |
|
| 25:59 | can issue pre charge and then the charges subject sometimes and then they're kind |
|
| 26:06 | deal with the whole process of activating old and closing it up and now |
|
| 26:16 | talk about some numbers I guess for , the chips here and chips and |
|
| 26:22 | I'll stop and see if there are . Um but before I've used this |
|
| 26:30 | of DDR and they will show up the next few slides and in case |
|
| 26:35 | think I define it in some earlier but just for your reference again, |
|
| 26:40 | stands for double data rate and what means is that one can got data |
|
| 26:49 | on when the clock signal is rising when it's fault. So then and |
|
| 26:56 | sort of, my little picture here shows a bunch of clock cycles. |
|
| 27:01 | the double air shows the length of clock cycle. So in that case |
|
| 27:05 | can get uh either read or write values per clock cycle through this double |
|
| 27:13 | rate design. No, just in for what I think is on the |
|
| 27:20 | slide shows that the external, there's ratio. Typically that is for |
|
| 27:28 | the internal clock for the memory is times slower than the bus clock. |
|
| 27:39 | . So here is now, I was a state of the art |
|
| 27:47 | for DDR, The Science of DDR is now the most recent designs that |
|
| 27:54 | being used in servers at the end this year, There will be a |
|
| 28:01 | survey generation coming up that will use next generation DDR five, that may |
|
| 28:08 | used in some other scenarios but um is still making the point was typical |
|
| 28:17 | the er, memories and the numbers terms of data rates, some of |
|
| 28:27 | numbers change and some of the numbers change much. Try to point that |
|
| 28:34 | . We have talked earlier on that , process and memory tends to be |
|
| 28:40 | more following because it's slow um and come to the reason why the clock |
|
| 28:47 | so much lower for inside the memory the slide or two but if you |
|
| 28:57 | in the first column on this so I guess the first column is |
|
| 29:01 | still er four and then there's You , four digit number after 1600 on |
|
| 29:08 | top and then 30 200 at the and that's related to okay, the |
|
| 29:17 | channel bus speed um that is She looked at the second column that |
|
| 29:29 | you the actual clock rate four, DDR memory ship itself, so to |
|
| 29:40 | , or the memory array of bits the memory chip, so that goes |
|
| 29:50 | in the lower range of performance for our memory from At 200 MHz And |
|
| 29:57 | top of the line is 400 So well my doctor, I talked |
|
| 30:05 | the process of designs, they tend operate in the 2.5 to 4 gigahertz |
|
| 30:13 | range. So They're about 10 times clock rate than the rate at which |
|
| 30:21 | bitter race in DDR memory operates. that's the fundamental reason I would say |
|
| 30:32 | memories a lot slower. No one wonder why is to cooperate so low |
|
| 30:37 | here clear. And I'll come to , as I mentioned now in order |
|
| 30:43 | try to mitigate a little bit um problem with such so low clocks rates |
|
| 30:52 | the our memory one plays some tricks that as you can see here that |
|
| 31:01 | I. O bus for memory channel incorporate as if you look at this |
|
| 31:09 | consistently four times higher than what it inside the memory and I'll talk a |
|
| 31:17 | bit tall. These things can be in which and how they actually |
|
| 31:25 | The our memory is designed in order be enable to also deliver things on |
|
| 31:31 | bus at the rate the buses operating the fact that it's four times |
|
| 31:38 | Then the memory cells themselves operates. then on we look at this data |
|
| 31:46 | , the transfer rate that is nowadays um rated as transfers per second and |
|
| 31:59 | is just meaning million transfers per seconds related to megahertz cooperates. But this |
|
| 32:06 | every thin or wire then can deliver at This rate which is on the |
|
| 32:17 | line is 1600 mega transfers perception and is per wire so to speak in |
|
| 32:28 | Memory Channel. As you can see is a factor of two for the |
|
| 32:32 | data rate goes from 800 to So there's two per clock cycle and |
|
| 32:37 | true throughout this column. So that the day they are future. And |
|
| 32:44 | we have just um all names here then which is then the factor of |
|
| 32:54 | higher than the transition. So This of indicates that it's kind of at |
|
| 33:03 | eight chip because now it's related more what's happening on the bus. And |
|
| 33:10 | you do then use this eight chips have put eight of them together. |
|
| 33:18 | then you actually get uh the rates terms of advice per second on the |
|
| 33:25 | channel. That in this case is gigabytes per second. For the lower |
|
| 33:31 | for the higher Speed grade lead er is 25.6 gigabytes per second. So |
|
| 33:44 | moving on to this notion all the I get there was the T |
|
| 33:51 | C. D. And R. . And the cast or column I |
|
| 33:57 | stopped. I guess I ended up listed as cl in this column |
|
| 34:02 | But these are the best for the here that sells how many cocks |
|
| 34:07 | In terms of the memory bust it takes delay between the single column |
|
| 34:16 | and before you can get something. if you see the row address, |
|
| 34:21 | number of cycles it takes before you issue a mhm column address and then |
|
| 34:29 | police charge time. So you can that the faster the internal cost. |
|
| 34:35 | coastal If you go down by the here, the higher the rate of |
|
| 34:42 | caucus for the memory cells the more delay cycle this takes before you can |
|
| 34:50 | do something. So even though the are higher as you go towards the |
|
| 34:58 | here. So the higher rate speed chips, the delay between the different |
|
| 35:04 | in the process of reading or writing . The chip goes up. So |
|
| 35:10 | the end the column here to the then tells you the actual physical time |
|
| 35:18 | they used to for the lower grade . Yes, 12.5 nine a second |
|
| 35:27 | if you look at the fastest it's not much Um it's actually |
|
| 35:35 | It's actually 59 seconds. So it's of counterintuitive and that's one needs to |
|
| 35:45 | for whether I want to spend the to buy the fastest are great memory |
|
| 35:52 | . Um that has benefits but if do um for instance you don't need |
|
| 36:02 | switch between different girls all that the you can stay in the same role |
|
| 36:08 | you don't need to pay the time pre charge and so on. So |
|
| 36:12 | memory access pattern also it gives you idea whether um it pays off because |
|
| 36:22 | the late agency involved that the agency not necessarily go down. In fact |
|
| 36:27 | goes up and potentially in this case the states the same so late in |
|
| 36:34 | it doesn't buy you anything band width . It does buy you something and |
|
| 36:43 | is one important very important aspects in you configure your memory, you know |
|
| 36:52 | here for a second and I'll try explain a little bit by things are |
|
| 36:58 | of staying pretty much the same and and not only in terms of the |
|
| 37:05 | to the cooperate that you have inside memory chip but it's also if you |
|
| 37:12 | goes through and I think I have on the future site but over |
|
| 37:17 | So the different generations of DDR the late insee hasn't changed much. |
|
| 37:24 | I'll see if there are questions at point and the muscles again try to |
|
| 37:30 | more why they things are so slow on physics. Okay. Uh do |
|
| 37:46 | little bit more on the physics then guess there's a little bit more of |
|
| 37:50 | was said to Leighton see measured in what it is. And the graph |
|
| 37:56 | at the bottom left shows pretty much say it's actually speed rates but it |
|
| 38:06 | different bullets here is you can see table above I guess I should say |
|
| 38:12 | has the different generations of DDR memory the right thing column here shows |
|
| 38:18 | it has decreased in the first and don't have a year but this is |
|
| 38:23 | ago in terms of the single data design stuff. A double data rate |
|
| 38:30 | probably about 20 years old, the one. But as you can see |
|
| 38:36 | numbers has not really changed and it's essentially inherent in the way the physics |
|
| 38:46 | for C mel's memories. So it's that member of designers are ignorant of |
|
| 38:53 | need to make higher performance chips but is fundamental. So as long as |
|
| 39:01 | stays with the c most technology for chips memory chips the latency is not |
|
| 39:11 | to change and that's something very important try to remember as a kind of |
|
| 39:21 | rule of them don't have too much that the internals of the our memory |
|
| 39:29 | improve in speed um tricks have been if I can say so, but |
|
| 39:37 | has been ways to try to mitigate fact bye increasing the capability to deliver |
|
| 39:47 | to the memory bus. So one to make up for the slow clocks |
|
| 39:56 | the actual architecture of this sign of chips that I will get to think |
|
| 40:03 | . Um yes, so I think will talk a little bit how one |
|
| 40:10 | up or try to bridge the differences one can, but the bridging is |
|
| 40:17 | terms of bandwidth, not in terms latency, I can't Strict Physics Last |
|
| 40:30 | . So yeah, it's kind of picture of how the year on chips |
|
| 40:39 | put together so and one of the few slides today I showed this kind |
|
| 40:47 | fundamental idea of memory being being organized matrix with rules and columns and and |
|
| 40:57 | cross point in between rows and There is a bit sometimes more than |
|
| 41:04 | being stored but fundamentally it's kind of you'll column organization. So here is |
|
| 41:11 | little bit of you know, square to denote one of these. A |
|
| 41:21 | of memory bits. Now, in for this case that the DDR please |
|
| 41:30 | and part of it is also true the therefore they'll talk, give examples |
|
| 41:35 | that today, therefore is a little more complex on the principle Maybe more |
|
| 41:40 | explained on this DDR three. So why I still have this Slides for |
|
| 41:45 | DDR three memory to illustrate how things up. So in fact inside the |
|
| 41:52 | there are eight it raised of memory and those are known as banks not |
|
| 42:05 | confused their ranks. That has to with um sets of memory chips that |
|
| 42:14 | the bus fit for. These are are internal in the they are designed |
|
| 42:23 | sometimes it also is kind of known pages and things uh incurs penalties when |
|
| 42:32 | move from one bank turned up. , it's just said you need to |
|
| 42:40 | roll and call them addresses and that inherent for each one of the |
|
| 42:47 | But then you also need to select back. So the standard For the |
|
| 42:55 | three memory requires that there are eight inside the chip. Memory designers don't |
|
| 43:03 | an option. So eight banks requires bits too select which particular banks I |
|
| 43:10 | to talk to and then we have role addresses and the column addresses. |
|
| 43:19 | now if one looks at the spec the things that exemplified on this drawing |
|
| 43:25 | , It's known as a one gigabit times eight. Yeah, So that |
|
| 43:34 | eight bits wide delivery sawing, every kind of clock is puts out |
|
| 43:44 | bits and then The organization then suffer collection of eight bits, there is |
|
| 43:52 | at least some makeup. So one Yeah, so the chip no, |
|
| 43:59 | saying I think Maryland. So this the banks already mentioned on so on |
|
| 44:04 | is the times eight. So if looks at the detail here and so |
|
| 44:09 | things that comes out that dimension gets of the ship is then it's white |
|
| 44:14 | much specify weight of the. Yeah The 128 that is an and in |
|
| 44:26 | the number of columns um there is that follows that Because some other way |
|
| 44:34 | at 1.8 tells you how many columns are. So that means they're seven |
|
| 44:39 | you find at the bottom here to out which column you want to be |
|
| 44:43 | . And also and when I looked the bank description you find in a |
|
| 44:49 | columns and the descriptions or it's a of roles times the number of columns |
|
| 44:56 | that it's associated with each um your intersections. So it's kind of the |
|
| 45:02 | dimension. That's just an issue economy that are 64 bits. No The |
|
| 45:15 | bits um is kind of not totally . So I think it says |
|
| 45:21 | Right so This is known as kind um the burst mode of eight. |
|
| 45:31 | that means for every request in fact get 64 bits and not just |
|
| 45:41 | So that's kind of the roll buffer a column for the robot for that |
|
| 45:48 | terms of the readout You get actually Value orbits instead of eight bits. |
|
| 45:58 | that's why and then kind of can up for the discrepancy between the data |
|
| 46:10 | of the memory channel and the internal rate. He said there was a |
|
| 46:16 | of four in the turn in clock between the bus and the internals and |
|
| 46:22 | it was double reiterate. So there's but bust cycles. You deliver The |
|
| 46:30 | . So that means in fact there a factor of eight difference in terms |
|
| 46:39 | what gets put out and that's why burst Motor eight is matching that First |
|
| 46:45 | of four in the clockwise and factor for the double. Okay. All |
|
| 46:52 | . So, uh let's see if have something. Yeah, so these |
|
| 46:57 | the number of all simply. And so if you work out the numbers |
|
| 47:06 | , 16 K rose tons 1 28 from 64 beats per row column |
|
| 47:13 | Um then you get 1 28 megabits then there are eight of those banks |
|
| 47:21 | considered for. Okay, go bit chip. So it's, you |
|
| 47:35 | some memories are fairly complex entities in own right. Uh Let's see what |
|
| 47:46 | have. Right. Yeah. So other thing is also Then I point |
|
| 47:54 | in number two on this slide, , that many of the processors works |
|
| 48:04 | 64 Byte Cache lines and Each the with is typically 64 bits or eight |
|
| 48:19 | . So also this first mode of kind of matches the ability to serve |
|
| 48:27 | lots. So that's connection between burst and cash lines as what um any |
|
| 48:45 | on this? Uh, so as soil, I showed you something about |
|
| 48:52 | er four and then I'll give you little bit more of examples here about |
|
| 48:58 | er, memory and problems in using . So, again, one is |
|
| 49:14 | to figure out again how to increase ability to deliver things faster to the |
|
| 49:24 | bust. Spike, the fact that cooperate internally is low and that's part |
|
| 49:30 | what one is trying to do with DDR for design that is or |
|
| 49:35 | So it tends to have groups or and the access time depends on whether |
|
| 49:44 | are working in a single group or group in different accesses or access things |
|
| 49:52 | different groups. So the timing performance of the R4, it's more complex |
|
| 50:01 | it is for the they are three does improve the potential peak then if |
|
| 50:09 | can get uh, Memory DDR so they did therefore peak. There |
|
| 50:21 | , there is on the memory bus according to the Spectators twice that it |
|
| 50:28 | fully we are full but it doesn't that the internals are working nfs to |
|
| 50:35 | . Just that the complexity of the as I will call it all the |
|
| 50:41 | and chip itself has got the more oil complex. Oh, so it |
|
| 50:51 | a little bit, I guess This four groups of banks that addressing is |
|
| 50:56 | of similar still things are shared on bus. But then it just as |
|
| 51:06 | said, it it's more complicated. that's why also you can't just take |
|
| 51:13 | server that was to send for DDR memory and tried to plug unity. |
|
| 51:18 | , Uh trip for nearly our five . It doesn't work. So then |
|
| 51:27 | have a slide here that leads to problem and how do you get the |
|
| 51:34 | performance are not out of the DDR . So because of the internal designs |
|
| 51:44 | well as the pin limitation, there potentially serious performance. It's just in |
|
| 51:54 | video are so it's by no means random access memory as the notion of |
|
| 52:02 | RAM and talks about main memory is deer and but it's by no means |
|
| 52:08 | access. So yes, basically saying if so on this particular example there |
|
| 52:22 | a memory chip that there DDR 1333 MHz so far works out the |
|
| 52:33 | And it was on a previous Line that corresponds to 10 .66 - |
|
| 52:39 | gigabits fights per second. And that's the access pattern to the diagram is |
|
| 52:47 | most favorable if you're only working in banks, air drops by a factor |
|
| 52:56 | two. And if you just work a single bank Than it goes down |
|
| 53:02 | 18 of the peak performance. So you happens to be unlucky and successive |
|
| 53:15 | that you want happens to be reciting the same bank, your performance or |
|
| 53:23 | Main memory goes down by a factor eight For the the R three memory |
|
| 53:28 | potentially more fatty. Therefore so it's big difference in terms of the ability |
|
| 53:41 | the memory to deliver its peak performance pattern has a huge impact on the |
|
| 53:50 | performance. This is just for a the around chip I think. Um |
|
| 53:58 | and then a multicourse, easy to when access is the memory comes from |
|
| 54:03 | course. You may also have additional on request successive requests um not being |
|
| 54:15 | call us then to single banks are banks. So here is kind of |
|
| 54:25 | simple example in a server type in which case in the in the |
|
| 54:32 | scenario basically things are just interpreted successive across the memory channels. So you |
|
| 54:42 | all the memory channels and in the case it turns out that the data |
|
| 54:48 | you want is on a single memory for that memory channels it happens to |
|
| 54:55 | in a single day. So in case the ratio between the best scenario |
|
| 55:00 | the worst scenario is um the yes 3 41 gigabytes per second. The |
|
| 55:12 | scenario and then it's very segregation depending how the access pattern is relative to |
|
| 55:19 | main memory design. So in that it can be a factor of over |
|
| 55:24 | performance degradation. Just as a function where how you access the memory for |
|
| 55:32 | data that you are having for your . So any questions on done before |
|
| 55:45 | talk about them why the corporate is , so I have a question uh |
|
| 55:56 | we use the single bank honored he channeling our band with radios. Strike |
|
| 56:08 | hopefully you're data. I lay out respect the memory and the way you |
|
| 56:18 | it uh will be such that you end up in this worst case |
|
| 56:27 | So well typically as being done is if you have for instance your matrices |
|
| 56:37 | multidimensional arrays, there are first flatten one year ray. All multidimensional arrays |
|
| 56:47 | by default, you know it all order column is your order depending on |
|
| 56:53 | to see or for tre so it into I won the right and this |
|
| 57:00 | the array is then typically laid out that to get the best performance if |
|
| 57:08 | accessed by Straight Strike one. So means it's played out across memory channels |
|
| 57:15 | across banks within the data chips or for the each memory channels. So |
|
| 57:27 | try to do it. So if have Australia one access, you get |
|
| 57:32 | peak memory performance but coming back to cities sometimes you, that means if |
|
| 57:41 | flattened writes like a robot. So you go in a row, the |
|
| 57:47 | element in the role is also then a place where you get fast access |
|
| 57:53 | being out either when you go down column. The next column is um |
|
| 58:03 | length of a role away from. So the first element in the second |
|
| 58:11 | is The roll length away from the element in the 1st row. So |
|
| 58:17 | means it may end up in a where it could be in the same |
|
| 58:24 | as the first element of the Roll. So it could be that |
|
| 58:29 | the column elements are in the same . So that when you work to |
|
| 58:36 | column access instead of row access, get the very slow bank performance instead |
|
| 58:45 | the best case scenario across banks and . So that's fine. It tends |
|
| 58:53 | be if people have, they optimize for The four turn cold by the |
|
| 59:04 | border. And they were made And that was part of the mm |
|
| 59:08 | to guess the second assignment I Um then if one were to convert |
|
| 59:18 | call to Seiko. Um that has opposite uh flattening so column in your |
|
| 59:33 | then it is preserved, the innermost low accesses. Then you get miserable |
|
| 59:44 | and that kind of fairly easy to patio Madonna may take sponsor book client |
|
| 59:51 | . Um and it, regardless of programming language is used, try to |
|
| 59:59 | the water between the two innermost loops you usually will see a big difference |
|
| 60:03 | performance. So so that the banner limited according to the data access but |
|
| 60:13 | not just like if you use the channel, your bandwidth is not automatically |
|
| 60:19 | only their new access to the RAM upon the access pattern, your bandwidth |
|
| 60:25 | be limited. Right, correct? . Thank you. So that's the |
|
| 60:34 | from you know, the program is to get good performance. One would |
|
| 60:43 | to be conscientious both how your erase by default laid out in memory and |
|
| 60:56 | what the access pattern is in the to their race. Such a do |
|
| 61:04 | and unfortunately there is not much control the layout of the kind of flattening |
|
| 61:13 | multidimensional erase standard programming languages has going fault the notion that memory is random |
|
| 61:23 | . So it doesn't take structural memory architecture memory into account. So it |
|
| 61:32 | things are random access and that's the on which the design is made. |
|
| 61:37 | unfortunately that's not true in reality and why one needs to as a programmer |
|
| 61:43 | trying to optimize performance, understand also the memory system itself is designed. |
|
| 61:55 | no, a little bit of comments and so I mentioned that the physics |
|
| 62:01 | why it's hard to get Corporates to up to be comfortable to what it |
|
| 62:10 | for processors. So yes, here's gap but talks about Sun Island. |
|
| 62:16 | this, I think I showed this like before. So you can see |
|
| 62:23 | also this, the technology being used building memory. So one has effectively |
|
| 62:31 | RC circuit and um the future sizes by the state of the art technology |
|
| 62:42 | today it's about and typical I think memories in the 10 to 50 nanometer |
|
| 62:52 | . It then the feature sizes the and not all this the smallest basically |
|
| 62:59 | issues whether you use that. state of the art or one generation |
|
| 63:05 | in terms of cost. Perfect. that yes, but the point is |
|
| 63:11 | scales. So the as we do notice hopefully I mean how they some |
|
| 63:24 | of the physics or electrical engineering course that time we can all imagine that |
|
| 63:32 | the thinner wire is the higher the is or you know, I think |
|
| 63:39 | usual analogy is kind of a holds most of us have seen. |
|
| 63:44 | really tiny holes are a stroll and things through. The straw is much |
|
| 63:50 | than pushing things that were white fat . So there's a resistance goes up |
|
| 63:58 | the smaller the future sizes are on check and something is also happening to |
|
| 64:06 | capacitors. The area scales down. that's a good thing. But also |
|
| 64:13 | vertical distance between the plates and the scales down. So um no changes |
|
| 64:23 | of the charge that they need to in order to in um charges or |
|
| 64:31 | capacitor. So in the end that up being this RC constant that defines |
|
| 64:39 | things behaves and you work out the that the cross section on the |
|
| 64:45 | it goes the square that means the goes up with the square of the |
|
| 64:51 | factor. Um or the wire and and rules with the scaling factor the |
|
| 65:02 | . But in the end the the RC product actually gets worse with |
|
| 65:10 | scaling factor. Now, if the gets shorter than and your sister also |
|
| 65:23 | smaller because the wire is shorter. when it comes to memory, the |
|
| 65:32 | of the warriors tend to stay the because you need to get things out |
|
| 65:36 | the chip. So you have to singles across the chip. So if |
|
| 65:44 | wire length remains saying the same. even though Warriors gets thinner and smaller |
|
| 65:51 | transistors get smaller and the charges get in the end it gets kind of |
|
| 66:00 | so it through a lot of tampering the physics. That one I've actually |
|
| 66:08 | to retain the cop grades on the ships. Um in principle one should |
|
| 66:16 | that to actually potentially have gotten worse the sense that it would be necessary |
|
| 66:23 | use lower cooperates for state of the technology but one has managed to maintain |
|
| 66:31 | whereas so that's because I think one to run things across the chip to |
|
| 66:37 | the signals out. That's not quite . Um I finally quickly flee back |
|
| 66:47 | one of the early signs. If can do a quick flip here, |
|
| 66:51 | just don't want the right way to it. So here you can see |
|
| 66:56 | are basically segments. So inside these there are segment someone doesn't fully run |
|
| 67:04 | without seeing the restoration. Um But Ron needs to run them quite some |
|
| 67:10 | . So in practice between single restorations wires remain at the same length. |
|
| 67:19 | that's not true when you look at of designs because the process of designs |
|
| 67:25 | not as dense and they have more of also feeling power. So in |
|
| 67:31 | case one can actually benefit from the future sizes. Except as I mentioned |
|
| 67:38 | the leakage is the problem. Someone even increase the cooperates on processor chips |
|
| 67:44 | . So even there things have kind landed in a space where carcasses don't |
|
| 67:49 | much as they are not increasing much their. Um And the discrepancy in |
|
| 67:56 | grades comes from basically the fundamental physics the desire to have very dense designs |
|
| 68:05 | uh huh. Memory and not quite stents designs. It's More than a |
|
| 68:12 | of 10 less for processor chips. in that case function have been able |
|
| 68:22 | run things at the higher clock grades the smaller feature sizes. So this |
|
| 68:29 | trying to explain why um It is the cooperates has remained low for memory |
|
| 68:41 | and that there is this problem that not easily solved by architecture. Um |
|
| 68:52 | ramps. So I hope that's when answer the question why it turns out |
|
| 69:03 | the rams our soul much sewer and one is try to make up for |
|
| 69:12 | by having this first note inside the and multiple banks in order to be |
|
| 69:18 | to output uh huh or delivers all a certain sense. Okay the Iran |
|
| 69:29 | is inside itself paralleled by having delivering internal buses more bits than the external |
|
| 69:39 | is only like 64 bits In a internally for eight picks out. But |
|
| 69:51 | other thing to be aware of that latency and memory chips has remained pretty |
|
| 69:57 | constant for over a decade, almost decades and it's not likely to chip |
|
| 70:03 | change come forward even though uh huh me increase ways of having more parallelism |
|
| 70:12 | the DDR memory to deliver more on memory bus. All right. Um |
|
| 70:25 | a little bit of another way of to alleviate the difference uh in speed |
|
| 70:34 | main memory and the process of ship the speed of cash is on site |
|
| 70:43 | the process is just so one thing to try to bring oh memory |
|
| 70:50 | I'm closer than being say on the board and basically try to use Iran |
|
| 71:01 | Iran inside the chip itself and that been done in some recent process of |
|
| 71:09 | science. So and that's known as the Iran for embedded the Iran so |
|
| 71:15 | that case ones use the deer um held designs and not the s from |
|
| 71:24 | cell design for the so called embedded that has been used in for instance |
|
| 71:33 | IBM started to use it for there three and sometimes they also call it |
|
| 71:37 | the four cashes. And intel has started to use this embedded the |
|
| 71:43 | That yeah is one transistor cells for but it has different both speed and |
|
| 71:58 | data retain mint properties again because it's totally different to science. So it's |
|
| 72:04 | ah behaving or operating like the cache cells. So it's operating on a |
|
| 72:12 | mode because of the design. But again they see most technologies or in |
|
| 72:19 | to try to get a little bit speed and energy efficiency and again it's |
|
| 72:27 | transistor so you can get more bits the need to E. D ram |
|
| 72:32 | you can get in the next So that's kind of a trade off |
|
| 72:36 | designers authority to use embedded there and some of the chips. So here |
|
| 72:45 | kind of an example what it is put it you can see it there |
|
| 72:49 | two my practice decide. And the thing is to try to get another |
|
| 72:58 | design but it's still external to the . Um And that this was known |
|
| 73:03 | to be the X point is um a product about two or three years |
|
| 73:12 | it's I told the new way of memory cells and in terms of speed |
|
| 73:20 | cost it fits between the Iran and memory. It's just something to be |
|
| 73:26 | of. It doesn't change. Doesn't in between Ekstrom and era money is |
|
| 73:34 | the Iran and pick prevalent or disk some flavor or flash. And there |
|
| 73:42 | just summary characteristics in terms of Layton for the different type of memory technologies |
|
| 73:51 | are being used, that the color lines is for the different memory technologies |
|
| 73:58 | it kind of shows a little bit things fits in terms of latency and |
|
| 74:06 | will stop there and it any more I'll try to get summarize it and |
|
| 74:16 | probably I don't the part two, just a few minutes I guess I |
|
| 74:25 | do my own somewhere and just reminding of what was partially coming in there |
|
| 74:34 | uh lecture last time in terms of these deer and ships are then put |
|
| 74:42 | in terms of modules known as thems uh unused chips are different with and |
|
| 74:50 | enables configuration in terms of different amounts memory um, that you have not |
|
| 74:59 | but using different number of bits per chip, but the width also helps |
|
| 75:07 | in configuring memory and then things get . Both energy rights and time wise |
|
| 75:16 | go up on a circuit board, via the socket onto the circuit board |
|
| 75:22 | dinner slot. So they're embedded system to use membership directly soldered onto the |
|
| 75:31 | board instead of using yes and them . But so again, increase both |
|
| 75:43 | performance and to performance in terms of and latency one in recent years in |
|
| 75:53 | last few have started to both memory dies and then integrate them in |
|
| 76:05 | same package as the processor chip. using what's known as silicon, no |
|
| 76:11 | interpose er that has a lot more and than what you can do from |
|
| 76:18 | socket to the board so you get channels, the memory and you can |
|
| 76:24 | operate them at a good speed. and then there was just some simple |
|
| 76:32 | of um the performance kind of difference both in terms of speed and energy |
|
| 76:47 | and I guess I found looks at bottom rows here um I can see |
|
| 76:53 | the Stacked memory, the high bandwidth are about 10 times As energy efficient |
|
| 77:01 | the DDR four. Um and it's considerably higher data. Right. So |
|
| 77:11 | are some choices today but I've been memories clearly also more expensive but mm |
|
| 77:20 | candidate. So it has been used some of the G P U. |
|
| 77:23 | in particular. Yeah, but not Gpus because of costs. So you |
|
| 77:30 | get Gps people, they are memory spm memory mhm Let's see what |
|
| 77:38 | Yes. The main point that they discussed a bit. And council question |
|
| 77:45 | to be aware of that main memory its name. The RAM. It's |
|
| 77:54 | no means uniform access uh it can a judge performance difference. So it's |
|
| 78:06 | and we try to understand performance if not good. What the reason mitt |
|
| 78:15 | it's just unfortunate access pattern to the the compiler decided to flatten the |
|
| 78:25 | Mhm And right, this is a innocent. So okay. No time |
|
| 78:33 | time. Part two maybe time for Questions. I'll come back to part |
|
| 78:39 | in the future. Lecture. It not be next lecture album. Um |
|
| 78:44 | , probably decided. Talking about open . And the part to hear about |
|
| 78:51 | power is um there is possibilities from user to actually manage power. But |
|
| 79:01 | most cases it can help explain somewhat performance data that you collect and doing |
|
| 79:11 | or timing experiments because on the control uh car crates and that happens happens |
|
| 79:22 | the rock. So it might be useful most of you as a way |
|
| 79:30 | trying to understand what might have the difference between different runs and the |
|
| 79:39 | time. It also I think it's interesting to see how but the big |
|
| 79:45 | like facebook and other studio in terms how they actually control power in their |
|
| 79:51 | centers, including all the way down the ship. But I'll stop |
|
| 79:57 | Take questions. Mhm |
|